 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spatio-Temporal Multilayer Perceptron for Gesture Recognition
Paper and Code
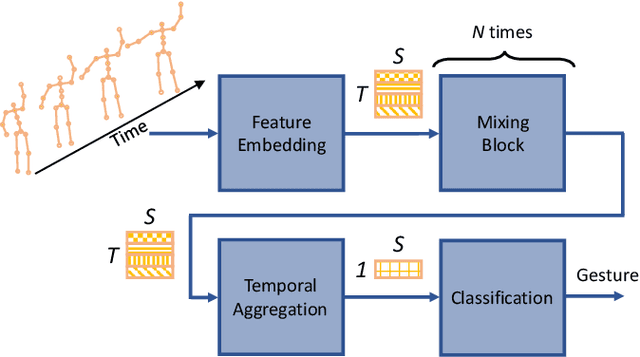
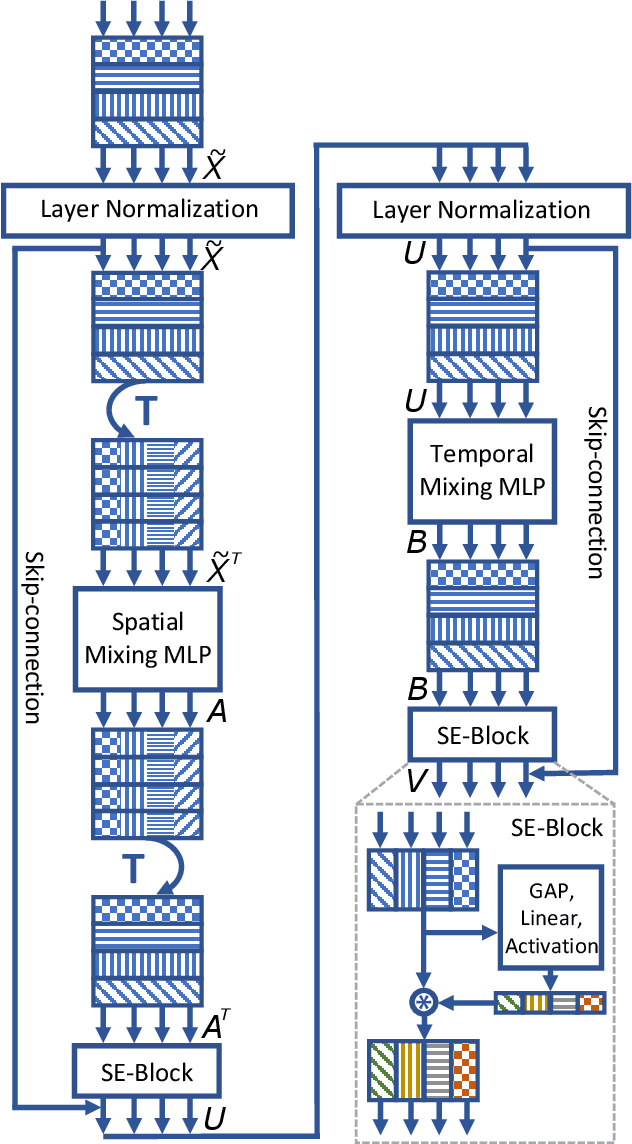
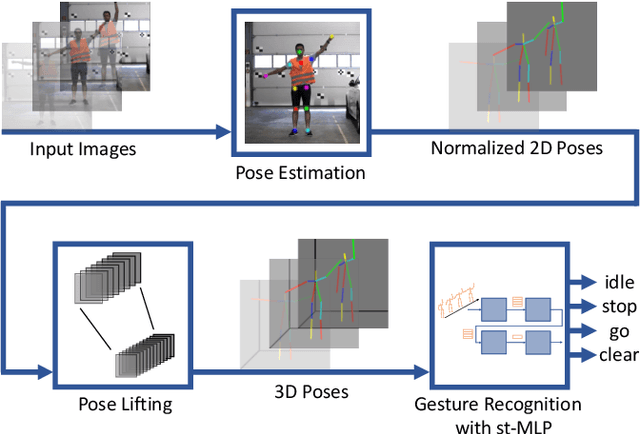
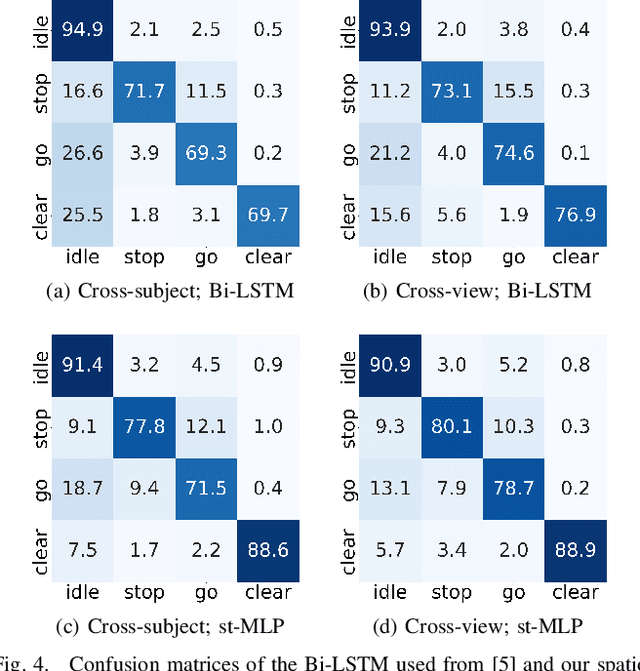
Gesture recognition is essential for the interaction of autonomous vehicles with humans. While the current approaches focus on combining several modalities like image features, keypoints and bone vectors, we present neural network architecture that delivers state-of-the-art results only with body skeleton input data. We propose the spatio-temporal multilayer perceptron for gesture recognition in the context of autonomous vehicles. Given 3D body poses over time, we define temporal and spatial mixing operations to extract features in both domains. Additionally, the importance of each time step is re-weighted with Squeeze-and-Excitation layers. An extensive evaluation of the TCG and Drive&Act datasets is provided to showcase the promising performance of our approach. Furthermore, we deploy our model to our autonomous vehicle to show its real-time capability and stable execution.