 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing What to Label for Few Shot Microscopy Image Cell Segmentation
Nov 18, 2022


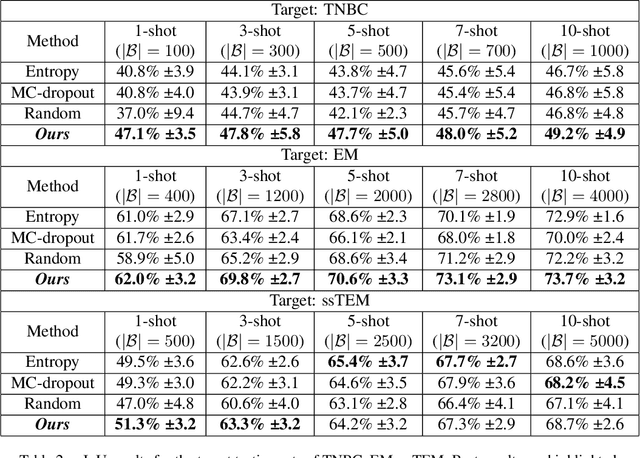
In microscopy image cell segmentation, it is common to train a deep neural network on source data, containing different types of microscopy images, and then fine-tune it using a support set comprising a few randomly selected and annotated training target images. In this paper, we argue that the random selection of unlabelled training target images to be annotated and included in the support set may not enable an effective fine-tuning process, so we propose a new approach to optimise this image selection process. Our approach involves a new scoring function to find informative unlabelled target images. In particular, we propose to measure the consistency in the model predictions on target images against specific data augmentations. However, we observe that the model trained with source datasets does not reliably evaluate consistency on target images. To alleviate this problem, we propose novel self-supervised pretext tasks to compute the scores of unlabelled target images. Finally, the top few images with the least consistency scores are added to the support set for oracle (i.e., expert) annotation and later used to fine-tune the model to the target images. In our evaluations that involve the segmentation of five different types of cell images, we demonstrate promising results on several target test sets compared to the random selection approach as well as other selection approaches, such as Shannon's entropy and Monte-Carlo dropout.
Edge-Based Self-Supervision for Semi-Supervised Few-Shot Microscopy Image Cell Segmentation
Aug 03, 2022
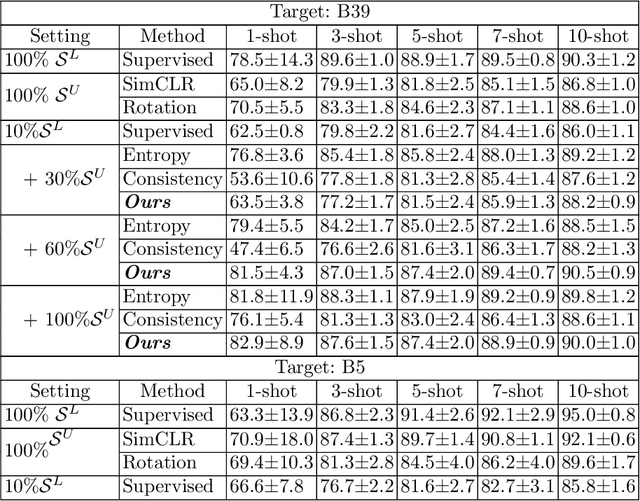

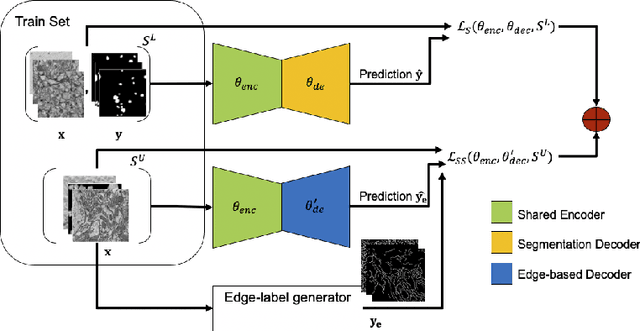
Deep neural networks currently deliver promising results for microscopy image cell segmentation, but they require large-scale labelled databases, which is a costly and time-consuming process. In this work, we relax the labelling requirement by combining self-supervised with semi-supervised learning. We propose the prediction of edge-based maps for self-supervising the training of the unlabelled images, which is combined with the supervised training of a small number of labelled images for learning the segmentation task. In our experiments, we evaluate on a few-shot microscopy image cell segmentation benchmark and show that only a small number of annotated images, e.g. 10% of the original training set, is enough for our approach to reach similar performance as with the fully annotated databases on 1- to 10-shots. Our code and trained models is made publicly available