 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Gradient-based Uncertainty for Monocular Depth Estimation
Feb 09, 2025



Monocular depth estimation, similar to other image-based tasks, is prone to erroneous predictions due to ambiguities in the image, for example, caused by dynamic objects or shadows. For this reason, pixel-wise uncertainty assessment is required for safety-critical applications to highlight the areas where the prediction is unreliable. We address this in a post hoc manner and introduce gradient-based uncertainty estimation for already trained depth estimation models. To extract gradients without depending on the ground truth depth, we introduce an auxiliary loss function based on the consistency of the predicted depth and a reference depth. The reference depth, which acts as pseudo ground truth, is in fact generated using a simple image or feature augmentation, making our approach simple and effective. To obtain the final uncertainty score, the derivatives w.r.t. the feature maps from single or multiple layers are calculated using back-propagation. We demonstrate that our gradient-based approach is effective in determining the uncertainty without re-training using the two standard depth estimation benchmarks KITTI and NYU. In particular, for models trained with monocular sequences and therefore most prone to uncertainty, our method outperforms related approaches. In addition, we publicly provide our code and models: https://github.com/jhornauer/GrUMoDepth
Consistency Regularisation for Unsupervised Domain Adaptation in Monocular Depth Estimation
May 27, 2024In monocular depth estimation, unsupervised domain adaptation has recently been explored to relax the dependence on large annotated image-based depth datasets. However, this comes at the cost of training multiple models or requiring complex training protocols. We formulate unsupervised domain adaptation for monocular depth estimation as a consistency-based semi-supervised learning problem by assuming access only to the source domain ground truth labels. To this end, we introduce a pairwise loss function that regularises predictions on the source domain while enforcing perturbation consistency across multiple augmented views of the unlabelled target samples. Importantly, our approach is simple and effective, requiring only training of a single model in contrast to the prior work. In our experiments, we rely on the standard depth estimation benchmarks KITTI and NYUv2 to demonstrate state-of-the-art results compared to related approaches. Furthermore, we analyse the simplicity and effectiveness of our approach in a series of ablation studies. The code is available at \url{https://github.com/AmirMaEl/SemiSupMDE}.
Out-of-Distribution Detection for Monocular Depth Estimation
Aug 11, 2023In monocular depth estimation, uncertainty estimation approaches mainly target the data uncertainty introduced by image noise. In contrast to prior work, we address the uncertainty due to lack of knowledge, which is relevant for the detection of data not represented by the training distribution, the so-called out-of-distribution (OOD) data. Motivated by anomaly detection, we propose to detect OOD images from an encoder-decoder depth estimation model based on the reconstruction error. Given the features extracted with the fixed depth encoder, we train an image decoder for image reconstruction using only in-distribution data. Consequently, OOD images result in a high reconstruction error, which we use to distinguish between in- and out-of-distribution samples. We built our experiments on the standard NYU Depth V2 and KITTI benchmarks as in-distribution data. Our post hoc method performs astonishingly well on different models and outperforms existing uncertainty estimation approaches without modifying the trained encoder-decoder depth estimation model.
Heatmap-based Out-of-Distribution Detection
Nov 15, 2022Our work investigates out-of-distribution (OOD) detection as a neural network output explanation problem. We learn a heatmap representation for detecting OOD images while visualizing in- and out-of-distribution image regions at the same time. Given a trained and fixed classifier, we train a decoder neural network to produce heatmaps with zero response for in-distribution samples and high response heatmaps for OOD samples, based on the classifier features and the class prediction. Our main innovation lies in the heatmap definition for an OOD sample, as the normalized difference from the closest in-distribution sample. The heatmap serves as a margin to distinguish between in- and out-of-distribution samples. Our approach generates the heatmaps not only for OOD detection, but also to indicate in- and out-of-distribution regions of the input image. In our evaluations, our approach mostly outperforms the prior work on fixed classifiers, trained on CIFAR-10, CIFAR-100 and Tiny ImageNet. The code is publicly available at: https://github.com/jhornauer/heatmap_ood.
Gradient-based Uncertainty for Monocular Depth Estimation
Aug 03, 2022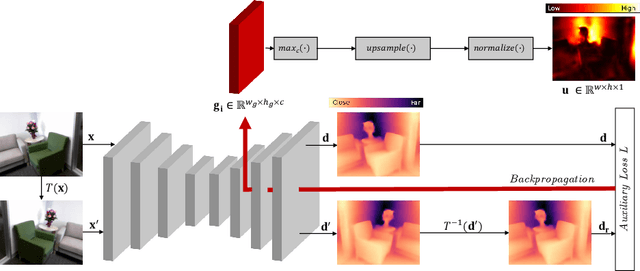
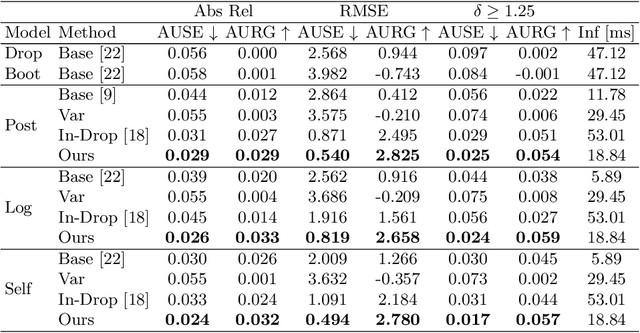
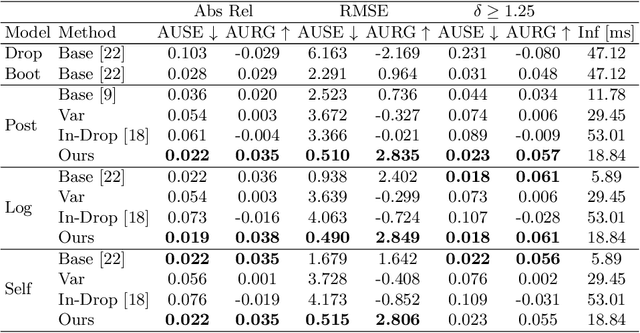
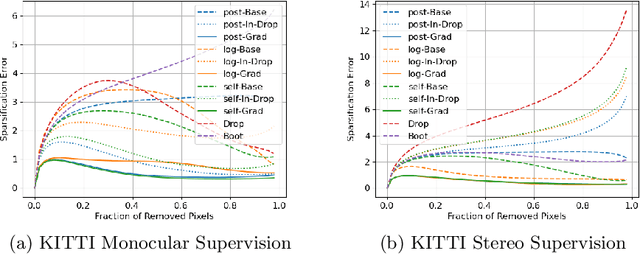
In monocular depth estimation, disturbances in the image context, like moving objects or reflecting materials, can easily lead to erroneous predictions. For that reason, uncertainty estimates for each pixel are necessary, in particular for safety-critical applications such as automated driving. We propose a post hoc uncertainty estimation approach for an already trained and thus fixed depth estimation model, represented by a deep neural network. The uncertainty is estimated with the gradients which are extracted with an auxiliary loss function. To avoid relying on ground-truth information for the loss definition, we present an auxiliary loss function based on the correspondence of the depth prediction for an image and its horizontally flipped counterpart. Our approach achieves state-of-the-art uncertainty estimation results on the KITTI and NYU Depth V2 benchmarks without the need to retrain the neural network. Models and code are publicly available at https://github.com/jhornauer/GrUMoDepth.
Visual Domain Adaptation for Monocular Depth Estimation on Resource-Constrained Hardware
Aug 05, 2021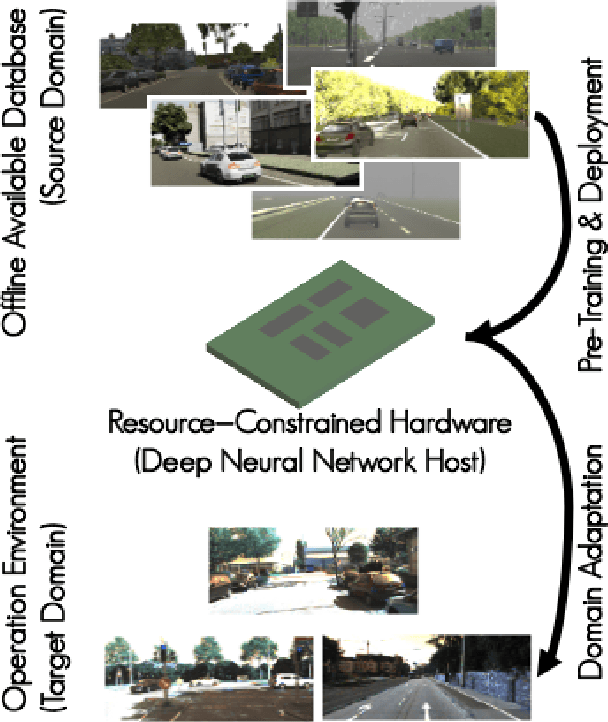
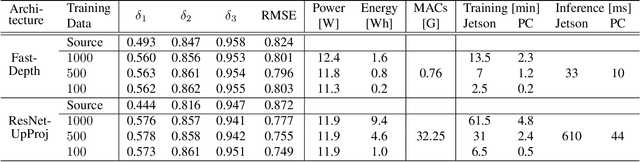
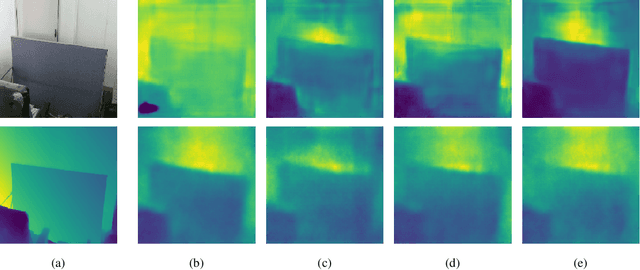
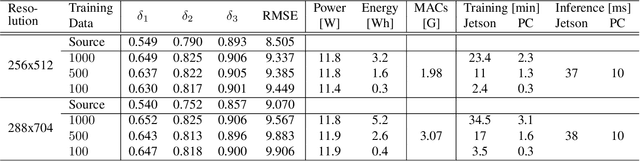
Real-world perception systems in many cases build on hardware with limited resources to adhere to cost and power limitations of their carrying system. Deploying deep neural networks on resource-constrained hardware became possible with model compression techniques, as well as efficient and hardware-aware architecture design. However, model adaptation is additionally required due to the diverse operation environments. In this work, we address the problem of training deep neural networks on resource-constrained hardware in the context of visual domain adaptation. We select the task of monocular depth estimation where our goal is to transform a pre-trained model to the target's domain data. While the source domain includes labels, we assume an unlabelled target domain, as it happens in real-world applications. Then, we present an adversarial learning approach that is adapted for training on the device with limited resources. Since visual domain adaptation, i.e. neural network training, has not been previously explored for resource-constrained hardware, we present the first feasibility study for image-based depth estimation. Our experiments show that visual domain adaptation is relevant only for efficient network architectures and training sets at the order of a few hundred samples. Models and code are publicly available.
Few-Shot Microscopy Image Cell Segmentation
Jun 29, 2020


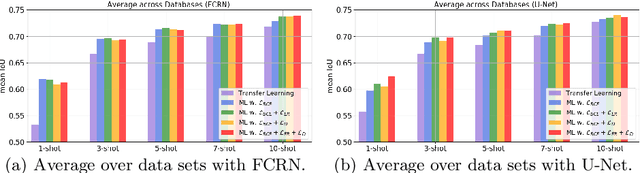
Automatic cell segmentation in microscopy images works well with the support of deep neural networks trained with full supervision. Collecting and annotating images, though, is not a sustainable solution for every new microscopy database and cell type. Instead, we assume that we can access a plethora of annotated image data sets from different domains (sources) and a limited number of annotated image data sets from the domain of interest (target), where each domain denotes not only different image appearance but also a different type of cell segmentation problem. We pose this problem as meta-learning where the goal is to learn a generic and adaptable few-shot learning model from the available source domain data sets and cell segmentation tasks. The model can be afterwards fine-tuned on the few annotated images of the target domain that contains different image appearance and different cell type. In our meta-learning training, we propose the combination of three objective functions to segment the cells, move the segmentation results away from the classification boundary using cross-domain tasks, and learn an invariant representation between tasks of the source domains. Our experiments on five public databases show promising results from 1- to 10-shot meta-learning using standard segmentation neural network architectures.