 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSA: Localized Semantic Alignment for Enhancing Temporal Consistency in Traffic Video Generation
Feb 05, 2026Controllable video generation has emerged as a versatile tool for autonomous driving, enabling realistic synthesis of traffic scenarios. However, existing methods depend on control signals at inference time to guide the generative model towards temporally consistent generation of dynamic objects, limiting their utility as scalable and generalizable data engines. In this work, we propose Localized Semantic Alignment (LSA), a simple yet effective framework for fine-tuning pre-trained video generation models. LSA enhances temporal consistency by aligning semantic features between ground-truth and generated video clips. Specifically, we compare the output of an off-the-shelf feature extraction model between the ground-truth and generated video clips localized around dynamic objects inducing a semantic feature consistency loss. We fine-tune the base model by combining this loss with the standard diffusion loss. The model fine-tuned for a single epoch with our novel loss outperforms the baselines in common video generation evaluation metrics. To further test the temporal consistency in generated videos we adapt two additional metrics from object detection task, namely mAP and mIoU. Extensive experiments on nuScenes and KITTI datasets show the effectiveness of our approach in enhancing temporal consistency in video generation without the need for external control signals during inference and any computational overheads.
TQD-Track: Temporal Query Denoising for 3D Multi-Object Tracking
Apr 04, 2025Query denoising has become a standard training strategy for DETR-based detectors by addressing the slow convergence issue. Besides that, query denoising can be used to increase the diversity of training samples for modeling complex scenarios which is critical for Multi-Object Tracking (MOT), showing its potential in MOT application. Existing approaches integrate query denoising within the tracking-by-attention paradigm. However, as the denoising process only happens within the single frame, it cannot benefit the tracker to learn temporal-related information. In addition, the attention mask in query denoising prevents information exchange between denoising and object queries, limiting its potential in improving association using self-attention. To address these issues, we propose TQD-Track, which introduces Temporal Query Denoising (TQD) tailored for MOT, enabling denoising queries to carry temporal information and instance-specific feature representation. We introduce diverse noise types onto denoising queries that simulate real-world challenges in MOT. We analyze our proposed TQD for different tracking paradigms, and find out the paradigm with explicit learned data association module, e.g. tracking-by-detection or alternating detection and association, benefit from TQD by a larger margin. For these paradigms, we further design an association mask in the association module to ensure the consistent interaction between track and detection queries as during inference. Extensive experiments on the nuScenes dataset demonstrate that our approach consistently enhances different tracking methods by only changing the training process, especially the paradigms with explicit association module.
SVS-GAN: Leveraging GANs for Semantic Video Synthesis
Sep 09, 2024


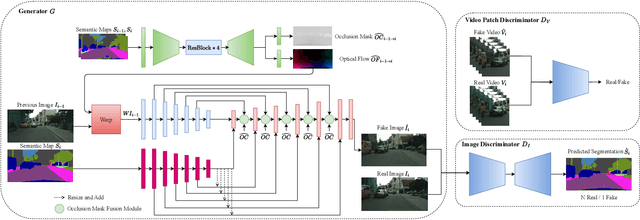
In recent years, there has been a growing interest in Semantic Image Synthesis (SIS) through the use of Generative Adversarial Networks (GANs) and diffusion models. This field has seen innovations such as the implementation of specialized loss functions tailored for this task, diverging from the more general approaches in Image-to-Image (I2I) translation. While the concept of Semantic Video Synthesis (SVS)$\unicode{x2013}$the generation of temporally coherent, realistic sequences of images from semantic maps$\unicode{x2013}$is newly formalized in this paper, some existing methods have already explored aspects of this field. Most of these approaches rely on generic loss functions designed for video-to-video translation or require additional data to achieve temporal coherence. In this paper, we introduce the SVS-GAN, a framework specifically designed for SVS, featuring a custom architecture and loss functions. Our approach includes a triple-pyramid generator that utilizes SPADE blocks. Additionally, we employ a U-Net-based network for the image discriminator, which performs semantic segmentation for the OASIS loss. Through this combination of tailored architecture and objective engineering, our framework aims to bridge the existing gap between SIS and SVS, outperforming current state-of-the-art models on datasets like Cityscapes and KITTI-360.
Joint Out-of-Distribution Detection and Uncertainty Estimation for Trajectory Prediction
Aug 04, 2023



Despite the significant research efforts on trajectory prediction for automated driving, limited work exists on assessing the prediction reliability. To address this limitation we propose an approach that covers two sources of error, namely novel situations with out-of-distribution (OOD) detection and the complexity in in-distribution (ID) situations with uncertainty estimation. We introduce two modules next to an encoder-decoder network for trajectory prediction. Firstly, a Gaussian mixture model learns the probability density function of the ID encoder features during training, and then it is used to detect the OOD samples in regions of the feature space with low likelihood. Secondly, an error regression network is applied to the encoder, which learns to estimate the trajectory prediction error in supervised training. During inference, the estimated prediction error is used as the uncertainty. In our experiments, the combination of both modules outperforms the prior work in OOD detection and uncertainty estimation, on the Shifts robust trajectory prediction dataset by $2.8 \%$ and $10.1 \%$, respectively. The code is publicly available.
RESET: Revisiting Trajectory Sets for Conditional Behavior Prediction
Apr 12, 2023It is desirable to predict the behavior of traffic participants conditioned on different planned trajectories of the autonomous vehicle. This allows the downstream planner to estimate the impact of its decisions. Recent approaches for conditional behavior prediction rely on a regression decoder, meaning that coordinates or polynomial coefficients are regressed. In this work we revisit set-based trajectory prediction, where the probability of each trajectory in a predefined trajectory set is determined by a classification model, and first-time employ it to the task of conditional behavior prediction. We propose RESET, which combines a new metric-driven algorithm for trajectory set generation with a graph-based encoder. For unconditional prediction, RESET achieves comparable performance to a regression-based approach. Due to the nature of set-based approaches, it has the advantageous property of being able to predict a flexible number of trajectories without influencing runtime or complexity. For conditional prediction, RESET achieves reasonable results with late fusion of the planned trajectory, which was not observed for regression-based approaches before. This means that RESET is computationally lightweight to combine with a planner that proposes multiple future plans of the autonomous vehicle, as large parts of the forward pass can be reused.
Multi-Task Edge Prediction in Temporally-Dynamic Video Graphs
Dec 06, 2022Graph neural networks have shown to learn effective node representations, enabling node-, link-, and graph-level inference. Conventional graph networks assume static relations between nodes, while relations between entities in a video often evolve over time, with nodes entering and exiting dynamically. In such temporally-dynamic graphs, a core problem is inferring the future state of spatio-temporal edges, which can constitute multiple types of relations. To address this problem, we propose MTD-GNN, a graph network for predicting temporally-dynamic edges for multiple types of relations. We propose a factorized spatio-temporal graph attention layer to learn dynamic node representations and present a multi-task edge prediction loss that models multiple relations simultaneously. The proposed architecture operates on top of scene graphs that we obtain from videos through object detection and spatio-temporal linking. Experimental evaluations on ActionGenome and CLEVRER show that modeling multiple relations in our temporally-dynamic graph network can be mutually beneficial, outperforming existing static and spatio-temporal graph neural networks, as well as state-of-the-art predicate classification methods.
A Benchmark for Unsupervised Anomaly Detection in Multi-Agent Trajectories
Sep 05, 2022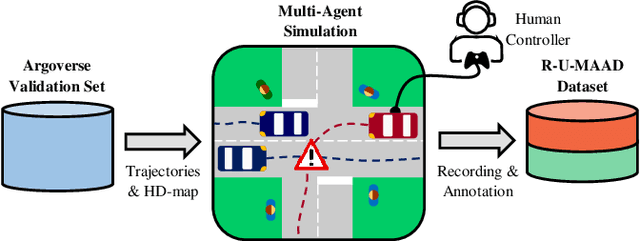

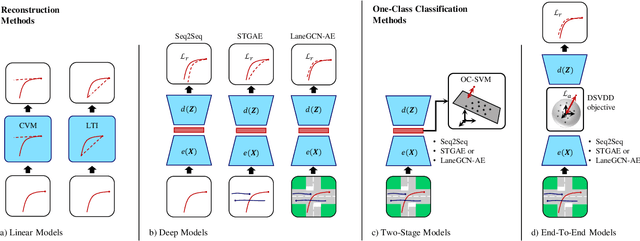
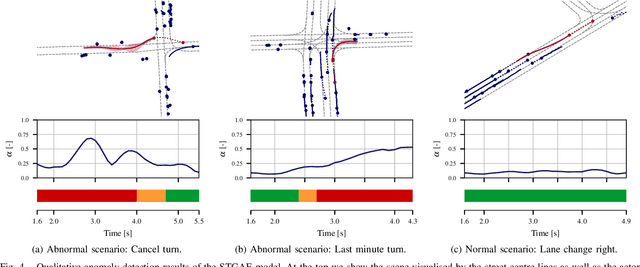
Human intuition allows to detect abnormal driving scenarios in situations they never experienced before. Like humans detect those abnormal situations and take countermeasures to prevent collisions, self-driving cars need anomaly detection mechanisms. However, the literature lacks a standard benchmark for the comparison of anomaly detection algorithms. We fill the gap and propose the R-U-MAAD benchmark for unsupervised anomaly detection in multi-agent trajectories. The goal is to learn a representation of the normal driving from the training sequences without labels, and afterwards detect anomalies. We use the Argoverse Motion Forecasting dataset for the training and propose a test dataset of 160 sequences with human-annotated anomalies in urban environments. To this end we combine a replay of real-world trajectories and scene-dependent abnormal driving in the simulation. In our experiments we compare 11 baselines including linear models, deep auto-encoders and one-class classification models using standard anomaly detection metrics. The deep reconstruction and end-to-end one-class methods show promising results. The benchmark and the baseline models will be publicly available.
Anomaly Detection in Multi-Agent Trajectories for Automated Driving
Oct 28, 2021

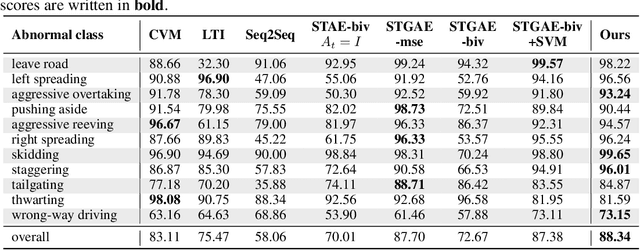
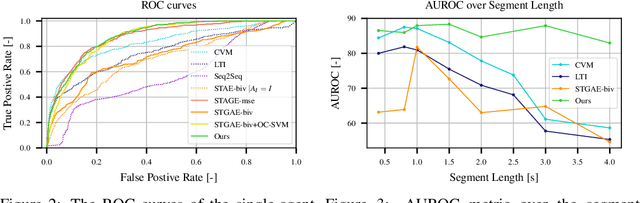
Human drivers can recognise fast abnormal driving situations to avoid accidents. Similar to humans, automated vehicles are supposed to perform anomaly detection. In this work, we propose the spatio-temporal graph auto-encoder for learning normal driving behaviours. Our innovation is the ability to jointly learn multiple trajectories of a dynamic number of agents. To perform anomaly detection, we first estimate a density function of the learned trajectory feature representation and then detect anomalies in low-density regions. Due to the lack of multi-agent trajectory datasets for anomaly detection in automated driving, we introduce our dataset using a driving simulator for normal and abnormal manoeuvres. Our evaluations show that our approach learns the relation between different agents and delivers promising results compared to the related works. The code, simulation and the dataset are publicly available on https://github.com/againerju/maad_highway.
Self-Supervised 3D Human Pose Estimation with Multiple-View Geometry
Aug 17, 2021



We present a self-supervised learning algorithm for 3D human pose estimation of a single person based on a multiple-view camera system and 2D body pose estimates for each view. To train our model, represented by a deep neural network, we propose a four-loss function learning algorithm, which does not require any 2D or 3D body pose ground-truth. The proposed loss functions make use of the multiple-view geometry to reconstruct 3D body pose estimates and impose body pose constraints across the camera views. Our approach utilizes all available camera views during training, while the inference is single-view. In our evaluations, we show promising performance on Human3.6M and HumanEva benchmarks, while we also present a generalization study on MPI-INF-3DHP dataset, as well as several ablation results. Overall, we outperform all self-supervised learning methods and reach comparable results to supervised and weakly-supervised learning approaches. Our code and models are publicly available
Traffic Control Gesture Recognition for Autonomous Vehicles
Jul 31, 2020


A car driver knows how to react on the gestures of the traffic officers. Clearly, this is not the case for the autonomous vehicle, unless it has road traffic control gesture recognition functionalities. In this work, we address the limitation of the existing autonomous driving datasets to provide learning data for traffic control gesture recognition. We introduce a dataset that is based on 3D body skeleton input to perform traffic control gesture classification on every time step. Our dataset consists of 250 sequences from several actors, ranging from 16 to 90 seconds per sequence. To evaluate our dataset, we propose eight sequential processing models based on deep neural networks such as recurrent networks, attention mechanism, temporal convolutional networks and graph convolutional networks. We present an extensive evaluation and analysis of all approaches for our dataset, as well as real-world quantitative evaluation. The code and dataset is publicly available.