 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYPE: Hybrid Planning with Ego Proposal-Conditioned Predictions
Oct 14, 2025Safe and interpretable motion planning in complex urban environments needs to reason about bidirectional multi-agent interactions. This reasoning requires to estimate the costs of potential ego driving maneuvers. Many existing planners generate initial trajectories with sampling-based methods and refine them by optimizing on learned predictions of future environment states, which requires a cost function that encodes the desired vehicle behavior. Designing such a cost function can be very challenging, especially if a wide range of complex urban scenarios has to be considered. We propose HYPE: HYbrid Planning with Ego proposal-conditioned predictions, a planner that integrates multimodal trajectory proposals from a learned proposal model as heuristic priors into a Monte Carlo Tree Search (MCTS) refinement. To model bidirectional interactions, we introduce an ego-conditioned occupancy prediction model, enabling consistent, scene-aware reasoning. Our design significantly simplifies cost function design in refinement by considering proposal-driven guidance, requiring only minimalistic grid-based cost terms. Evaluations on large-scale real-world benchmarks nuPlan and DeepUrban show that HYPE effectively achieves state-of-the-art performance, especially in safety and adaptability.
Evidential Uncertainty Estimation for Multi-Modal Trajectory Prediction
Mar 07, 2025Accurate trajectory prediction is crucial for autonomous driving, yet uncertainty in agent behavior and perception noise makes it inherently challenging. While multi-modal trajectory prediction models generate multiple plausible future paths with associated probabilities, effectively quantifying uncertainty remains an open problem. In this work, we propose a novel multi-modal trajectory prediction approach based on evidential deep learning that estimates both positional and mode probability uncertainty in real time. Our approach leverages a Normal Inverse Gamma distribution for positional uncertainty and a Dirichlet distribution for mode uncertainty. Unlike sampling-based methods, it infers both types of uncertainty in a single forward pass, significantly improving efficiency. Additionally, we experimented with uncertainty-driven importance sampling to improve training efficiency by prioritizing underrepresented high-uncertainty samples over redundant ones. We perform extensive evaluations of our method on the Argoverse 1 and Argoverse 2 datasets, demonstrating that it provides reliable uncertainty estimates while maintaining high trajectory prediction accuracy.
Advancing Out-of-Distribution Detection via Local Neuroplasticity
Feb 20, 2025In the domain of machine learning, the assumption that training and test data share the same distribution is often violated in real-world scenarios, requiring effective out-of-distribution (OOD) detection. This paper presents a novel OOD detection method that leverages the unique local neuroplasticity property of Kolmogorov-Arnold Networks (KANs). Unlike traditional multilayer perceptrons, KANs exhibit local plasticity, allowing them to preserve learned information while adapting to new tasks. Our method compares the activation patterns of a trained KAN against its untrained counterpart to detect OOD samples. We validate our approach on benchmarks from image and medical domains, demonstrating superior performance and robustness compared to state-of-the-art techniques. These results underscore the potential of KANs in enhancing the reliability of machine learning systems in diverse environments.
Traffic and Safety Rule Compliance of Humans in Diverse Driving Situations
Nov 04, 2024
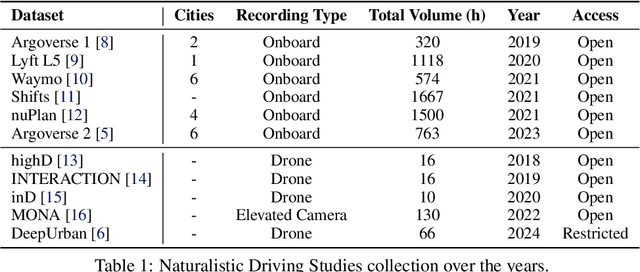
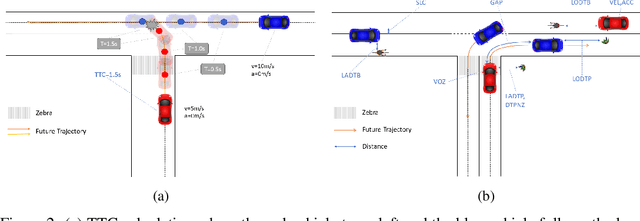

The increasing interest in autonomous driving systems has highlighted the need for an in-depth analysis of human driving behavior in diverse scenarios. Analyzing human data is crucial for developing autonomous systems that replicate safe driving practices and ensure seamless integration into human-dominated environments. This paper presents a comparative evaluation of human compliance with traffic and safety rules across multiple trajectory prediction datasets, including Argoverse 2, nuPlan, Lyft, and DeepUrban. By defining and leveraging existing safety and behavior-related metrics, such as time to collision, adherence to speed limits, and interactions with other traffic participants, we aim to provide a comprehensive understanding of each datasets strengths and limitations. Our analysis focuses on the distribution of data samples, identifying noise, outliers, and undesirable behaviors exhibited by human drivers in both the training and validation sets. The results underscore the need for applying robust filtering techniques to certain datasets due to high levels of noise and the presence of such undesirable behaviors.
LMR: Lane Distance-Based Metric for Trajectory Prediction
Apr 13, 2023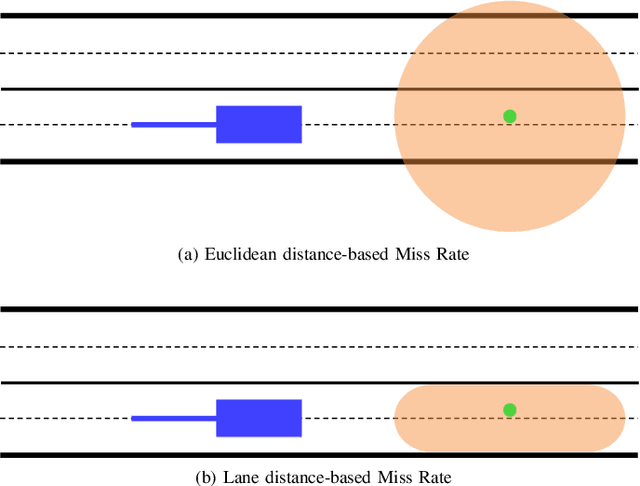

The development of approaches for trajectory prediction requires metrics to validate and compare their performance. Currently established metrics are based on Euclidean distance, which means that errors are weighted equally in all directions. Euclidean metrics are insufficient for structured environments like roads, since they do not properly capture the agent's intent relative to the underlying lane. In order to provide a reasonable assessment of trajectory prediction approaches with regard to the downstream planning task, we propose a new metric that is lane distance-based: Lane Miss Rate (LMR). For the calculation of LMR, the ground-truth and predicted endpoints are assigned to lane segments, more precisely their centerlines. Measured by the distance along the lane segments, predictions that are within a certain threshold distance to the ground-truth count as hits, otherwise they count as misses. LMR is then defined as the ratio of sequences that yield a miss. Our results on three state-of-the-art trajectory prediction models show that LMR preserves the order of Euclidean distance-based metrics. In contrast to the Euclidean Miss Rate, qualitative results show that LMR yields misses for sequences where predictions are located on wrong lanes. Hits on the other hand result for sequences where predictions are located on the correct lane. This means that LMR implicitly weights Euclidean error relative to the lane and goes into the direction of capturing intents of traffic agents. The source code of LMR for Argoverse 2 is publicly available.
RESET: Revisiting Trajectory Sets for Conditional Behavior Prediction
Apr 12, 2023It is desirable to predict the behavior of traffic participants conditioned on different planned trajectories of the autonomous vehicle. This allows the downstream planner to estimate the impact of its decisions. Recent approaches for conditional behavior prediction rely on a regression decoder, meaning that coordinates or polynomial coefficients are regressed. In this work we revisit set-based trajectory prediction, where the probability of each trajectory in a predefined trajectory set is determined by a classification model, and first-time employ it to the task of conditional behavior prediction. We propose RESET, which combines a new metric-driven algorithm for trajectory set generation with a graph-based encoder. For unconditional prediction, RESET achieves comparable performance to a regression-based approach. Due to the nature of set-based approaches, it has the advantageous property of being able to predict a flexible number of trajectories without influencing runtime or complexity. For conditional prediction, RESET achieves reasonable results with late fusion of the planned trajectory, which was not observed for regression-based approaches before. This means that RESET is computationally lightweight to combine with a planner that proposes multiple future plans of the autonomous vehicle, as large parts of the forward pass can be reused.
Exploring Navigation Maps for Learning-Based Motion Prediction
Feb 13, 2023The prediction of surrounding agents' motion is a key for safe autonomous driving. In this paper, we explore navigation maps as an alternative to the predominant High Definition (HD) maps for learning-based motion prediction. Navigation maps provide topological and geometrical information on road-level, HD maps additionally have centimeter-accurate lane-level information. As a result, HD maps are costly and time-consuming to obtain, while navigation maps with near-global coverage are freely available. We describe an approach to integrate navigation maps into learning-based motion prediction models. To exploit locally available HD maps during training, we additionally propose a model-agnostic method for knowledge distillation. In experiments on the publicly available Argoverse dataset with navigation maps obtained from OpenStreetMap, our approach shows a significant improvement over not using a map at all. Combined with our method for knowledge distillation, we achieve results that are close to the original HD map-reliant models. Our publicly available navigation map API for Argoverse enables researchers to develop and evaluate their own approaches using navigation maps.
SCENE: Reasoning about Traffic Scenes using Heterogeneous Graph Neural Networks
Jan 09, 2023Understanding traffic scenes requires considering heterogeneous information about dynamic agents and the static infrastructure. In this work we propose SCENE, a methodology to encode diverse traffic scenes in heterogeneous graphs and to reason about these graphs using a heterogeneous Graph Neural Network encoder and task-specific decoders. The heterogeneous graphs, whose structures are defined by an ontology, consist of different nodes with type-specific node features and different relations with type-specific edge features. In order to exploit all the information given by these graphs, we propose to use cascaded layers of graph convolution. The result is an encoding of the scene. Task-specific decoders can be applied to predict desired attributes of the scene. Extensive evaluation on two diverse binary node classification tasks show the main strength of this methodology: despite being generic, it even manages to outperform task-specific baselines. The further application of our methodology to the task of node classification in various knowledge graphs shows its transferability to other domains.
* Thomas Monninger and Julian Schmidt are co-first authors. The order was determined alphabetically
MEAT: Maneuver Extraction from Agent Trajectories
Jun 10, 2022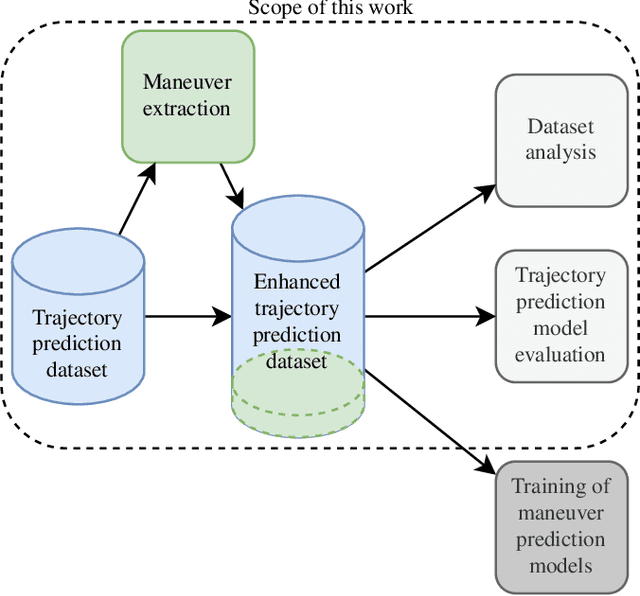
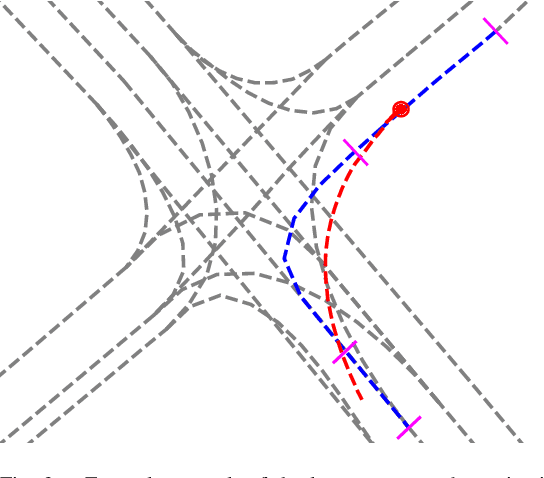
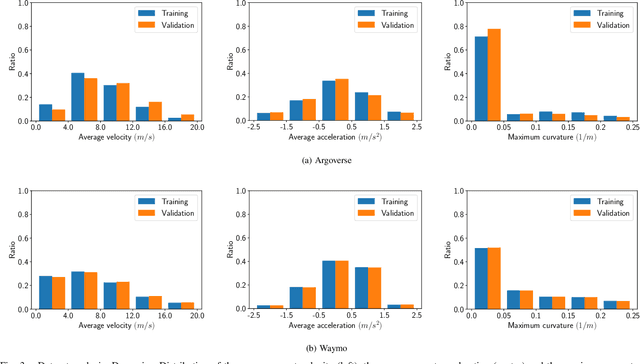
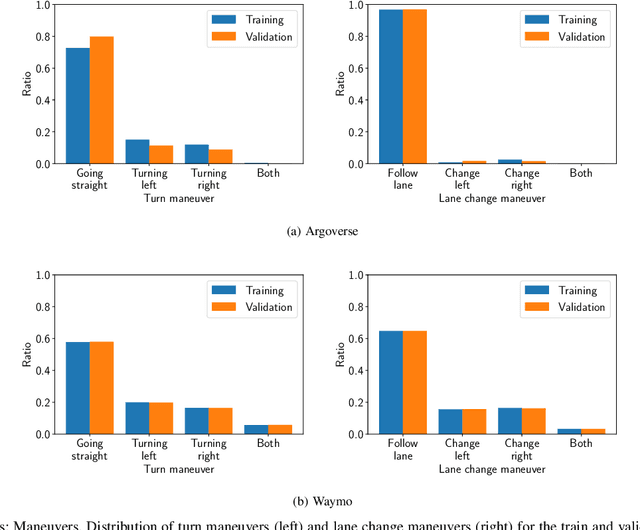
Advances in learning-based trajectory prediction are enabled by large-scale datasets. However, in-depth analysis of such datasets is limited. Moreover, the evaluation of prediction models is limited to metrics averaged over all samples in the dataset. We propose an automated methodology that allows to extract maneuvers (e.g., left turn, lane change) from agent trajectories in such datasets. The methodology considers information about the agent dynamics and information about the lane segments the agent traveled along. Although it is possible to use the resulting maneuvers for training classification networks, we exemplary use them for extensive trajectory dataset analysis and maneuver-specific evaluation of multiple state-of-the-art trajectory prediction models. Additionally, an analysis of the datasets and an evaluation of the prediction models based on the agent dynamics is provided.
CRAT-Pred: Vehicle Trajectory Prediction with Crystal Graph Convolutional Neural Networks and Multi-Head Self-Attention
Feb 10, 2022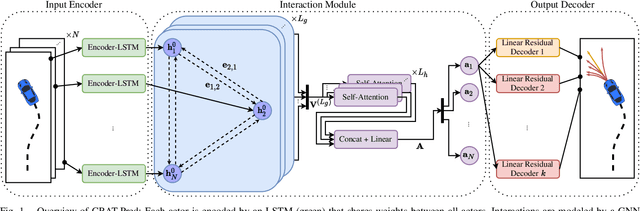
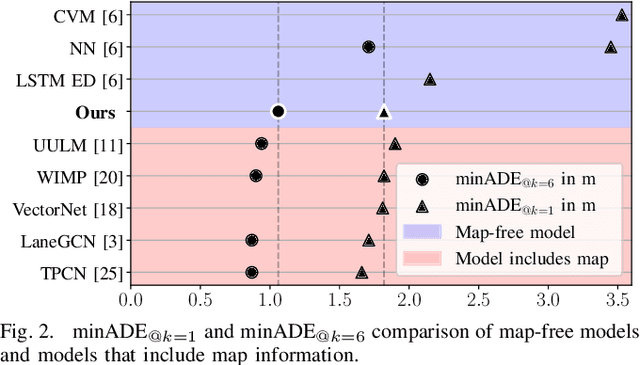
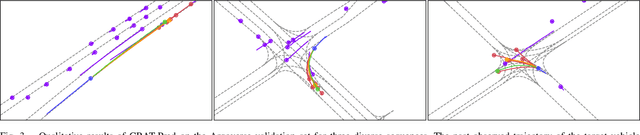
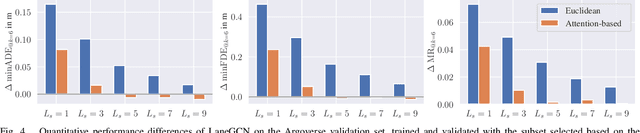
Predicting the motion of surrounding vehicles is essential for autonomous vehicles, as it governs their own motion plan. Current state-of-the-art vehicle prediction models heavily rely on map information. In reality, however, this information is not always available. We therefore propose CRAT-Pred, a multi-modal and non-rasterization-based trajectory prediction model, specifically designed to effectively model social interactions between vehicles, without relying on map information. CRAT-Pred applies a graph convolution method originating from the field of material science to vehicle prediction, allowing to efficiently leverage edge features, and combines it with multi-head self-attention. Compared to other map-free approaches, the model achieves state-of-the-art performance with a significantly lower number of model parameters. In addition to that, we quantitatively show that the self-attention mechanism is able to learn social interactions between vehicles, with the weights representing a measurable interaction score. The source code is publicly available.