 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic and Safety Rule Compliance of Humans in Diverse Driving Situations
Nov 04, 2024
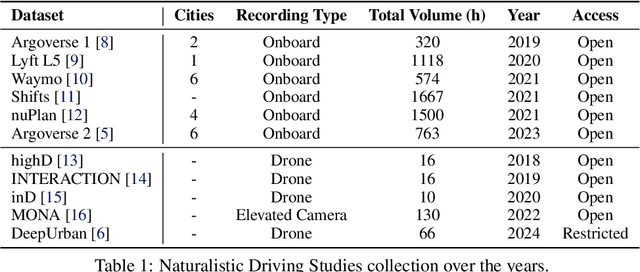
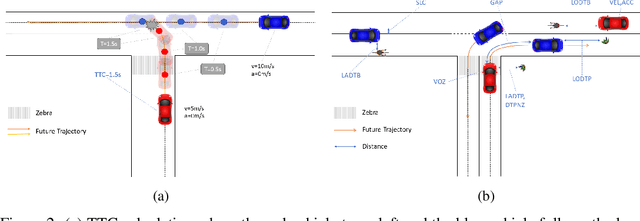

The increasing interest in autonomous driving systems has highlighted the need for an in-depth analysis of human driving behavior in diverse scenarios. Analyzing human data is crucial for developing autonomous systems that replicate safe driving practices and ensure seamless integration into human-dominated environments. This paper presents a comparative evaluation of human compliance with traffic and safety rules across multiple trajectory prediction datasets, including Argoverse 2, nuPlan, Lyft, and DeepUrban. By defining and leveraging existing safety and behavior-related metrics, such as time to collision, adherence to speed limits, and interactions with other traffic participants, we aim to provide a comprehensive understanding of each datasets strengths and limitations. Our analysis focuses on the distribution of data samples, identifying noise, outliers, and undesirable behaviors exhibited by human drivers in both the training and validation sets. The results underscore the need for applying robust filtering techniques to certain datasets due to high levels of noise and the presence of such undesirable behaviors.
A Realism Metric for Generated LiDAR Point Clouds
Aug 31, 2022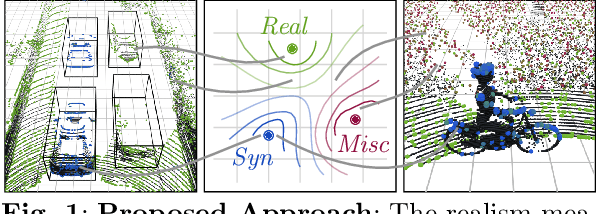
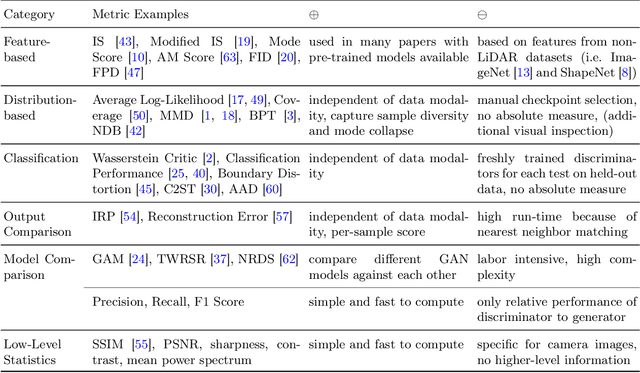
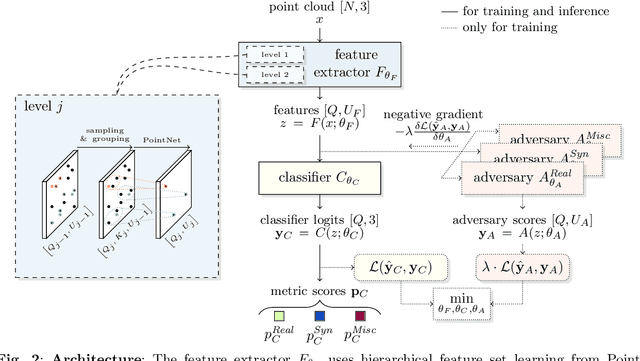
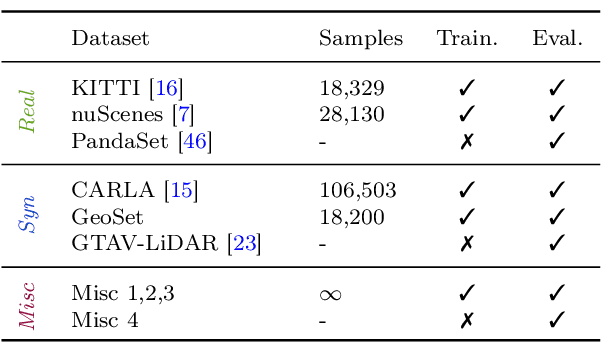
A considerable amount of research is concerned with the generation of realistic sensor data. LiDAR point clouds are generated by complex simulations or learned generative models. The generated data is usually exploited to enable or improve downstream perception algorithms. Two major questions arise from these procedures: First, how to evaluate the realism of the generated data? Second, does more realistic data also lead to better perception performance? This paper addresses both questions and presents a novel metric to quantify the realism of LiDAR point clouds. Relevant features are learned from real-world and synthetic point clouds by training on a proxy classification task. In a series of experiments, we demonstrate the application of our metric to determine the realism of generated LiDAR data and compare the realism estimation of our metric to the performance of a segmentation model. We confirm that our metric provides an indication for the downstream segmentation performance.
A Survey on Deep Domain Adaptation for LiDAR Perception
Jun 07, 2021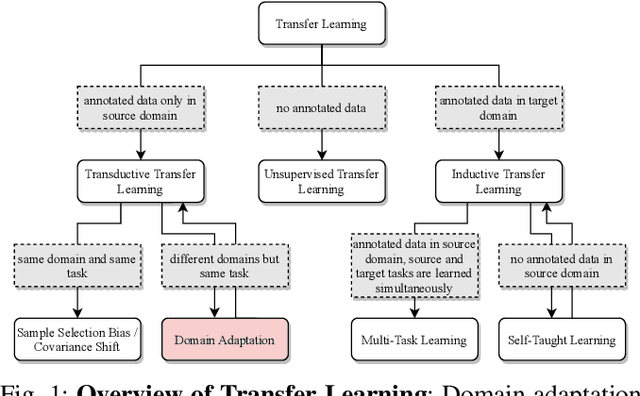
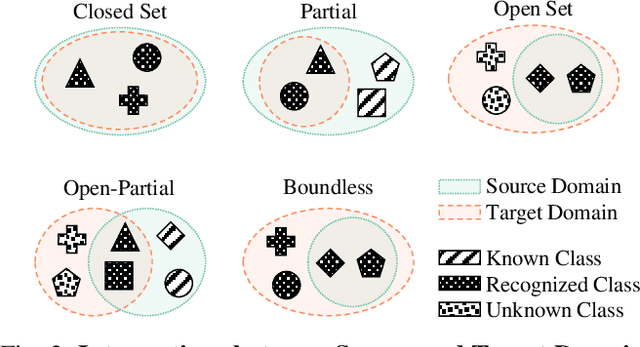
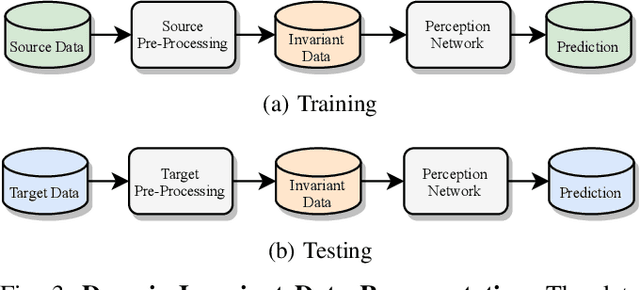
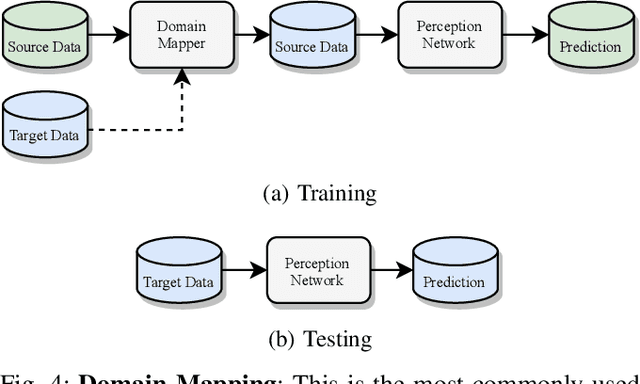
Scalable systems for automated driving have to reliably cope with an open-world setting. This means, the perception systems are exposed to drastic domain shifts, like changes in weather conditions, time-dependent aspects, or geographic regions. Covering all domains with annotated data is impossible because of the endless variations of domains and the time-consuming and expensive annotation process. Furthermore, fast development cycles of the system additionally introduce hardware changes, such as sensor types and vehicle setups, and the required knowledge transfer from simulation. To enable scalable automated driving, it is therefore crucial to address these domain shifts in a robust and efficient manner. Over the last years, a vast amount of different domain adaptation techniques evolved. There already exists a number of survey papers for domain adaptation on camera images, however, a survey for LiDAR perception is absent. Nevertheless, LiDAR is a vital sensor for automated driving that provides detailed 3D scans of the vehicle's surroundings. To stimulate future research, this paper presents a comprehensive review of recent progress in domain adaptation methods and formulates interesting research questions specifically targeted towards LiDAR perception.
Semantic Scene Completion using Local Deep Implicit Functions on LiDAR Data
Nov 19, 2020

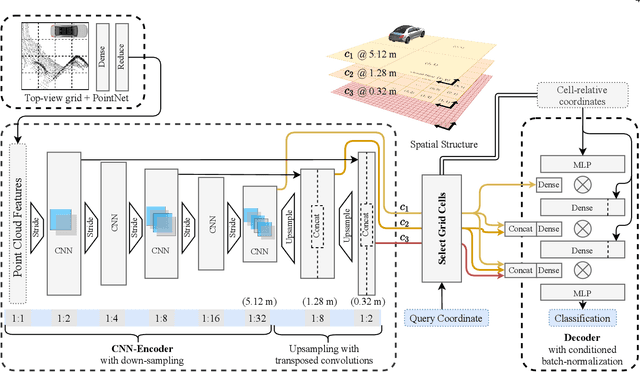
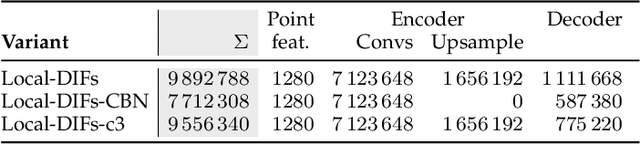
Semantic scene completion is the task of jointly estimating 3D geometry and semantics of objects and surfaces within a given extent. This is a particularly challenging task on real-world data that is sparse and occluded. We propose a scene segmentation network based on local Deep Implicit Functions as a novel learning-based method for scene completion. Unlike previous work on scene completion, our method produces a continuous scene representation that is not based on voxelization. We encode raw point clouds into a latent space locally and at multiple spatial resolutions. A global scene completion function is subsequently assembled from the localized function patches. We show that this continuous representation is suitable to encode geometric and semantic properties of extensive outdoor scenes without the need for spatial discretization (thus avoiding the trade-off between level of scene detail and the scene extent that can be covered). We train and evaluate our method on semantically annotated LiDAR scans from the Semantic KITTI dataset. Our experiments verify that our method generates a powerful representation that can be decoded into a dense 3D description of a given scene. The performance of our method surpasses the state of the art on the Semantic KITTI Scene Completion Benchmark in terms of both geometric and semantic completion Intersection-over-Union (IoU).
Scan-based Semantic Segmentation of LiDAR Point Clouds: An Experimental Study
Apr 28, 2020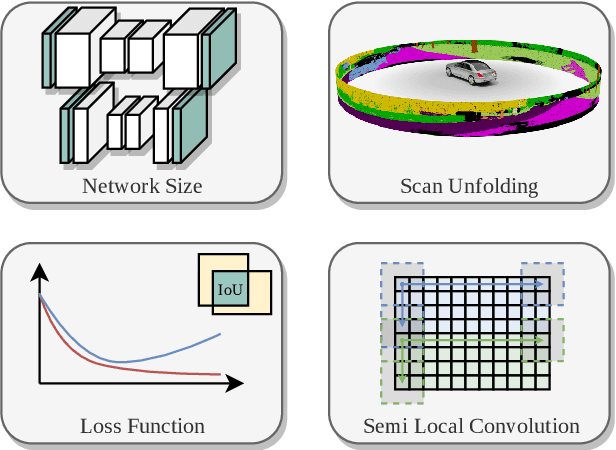
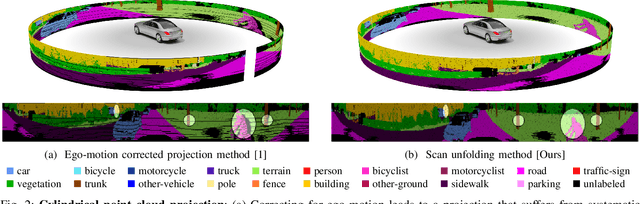
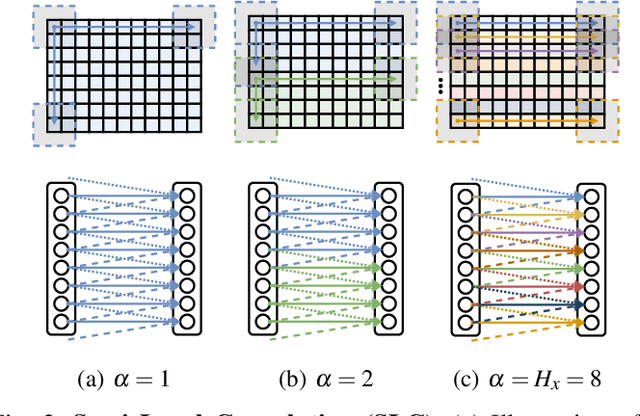
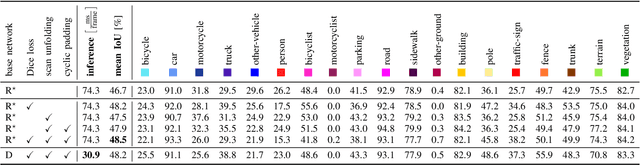
Autonomous vehicles need to have a semantic understanding of the three-dimensional world around them in order to reason about their environment. State of the art methods use deep neural networks to predict semantic classes for each point in a LiDAR scan. A powerful and efficient way to process LiDAR measurements is to use two-dimensional, image-like projections. In this work, we perform a comprehensive experimental study of image-based semantic segmentation architectures for LiDAR point clouds. We demonstrate various techniques to boost the performance and to improve runtime as well as memory constraints. First, we examine the effect of network size and suggest that much faster inference times can be achieved at a very low cost to accuracy. Next, we introduce an improved point cloud projection technique that does not suffer from systematic occlusions. We use a cyclic padding mechanism that provides context at the horizontal field-of-view boundaries. In a third part, we perform experiments with a soft Dice loss function that directly optimizes for the intersection-over-union metric. Finally, we propose a new kind of convolution layer with a reduced amount of weight-sharing along one of the two spatial dimensions, addressing the large difference in appearance along the vertical axis of a LiDAR scan. We propose a final set of the above methods with which the model achieves an increase of 3.2% in mIoU segmentation performance over the baseline while requiring only 42% of the original inference time.
CNN-based synthesis of realistic high-resolution LiDAR data
Jun 28, 2019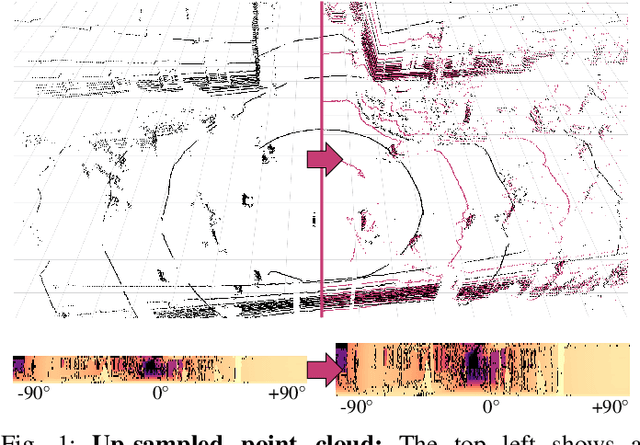
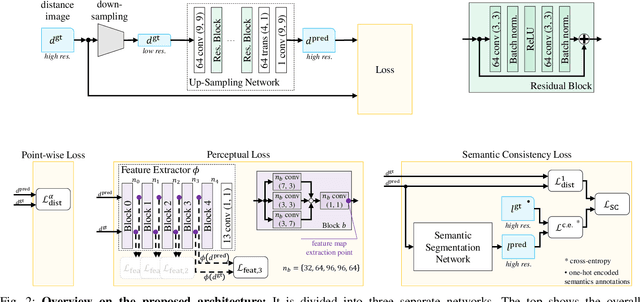
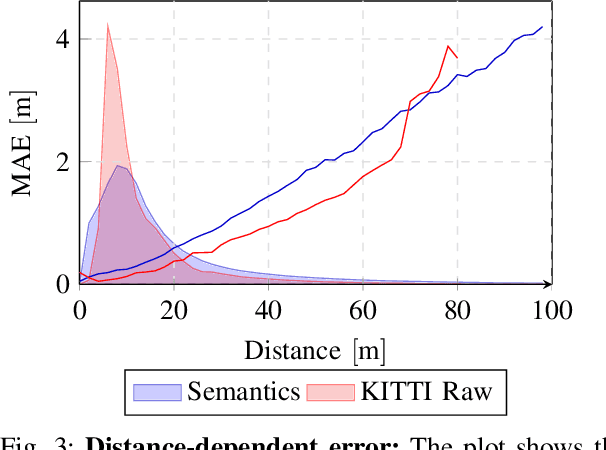
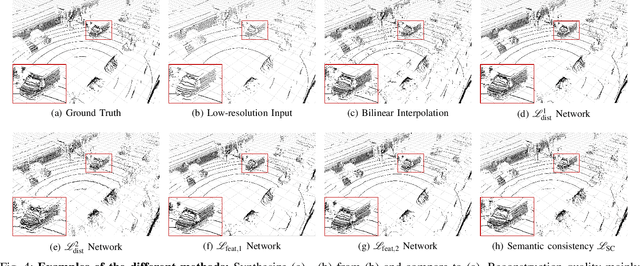
This paper presents a novel CNN-based approach for synthesizing high-resolution LiDAR point cloud data. Our approach generates semantically and perceptually realistic results with guidance from specialized loss-functions. First, we utilize a modified per-point loss that addresses missing LiDAR point measurements. Second, we align the quality of our generated output with real-world sensor data by applying a perceptual loss. In large-scale experiments on real-world datasets, we evaluate both the geometric accuracy and semantic segmentation performance using our generated data vs. ground truth. In a mean opinion score testing we further assess the perceptual quality of our generated point clouds. Our results demonstrate a significant quantitative and qualitative improvement in both geometry and semantics over traditional non CNN-based up-sampling methods.