 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScan-based Semantic Segmentation of LiDAR Point Clouds: An Experimental Study
Paper and Code
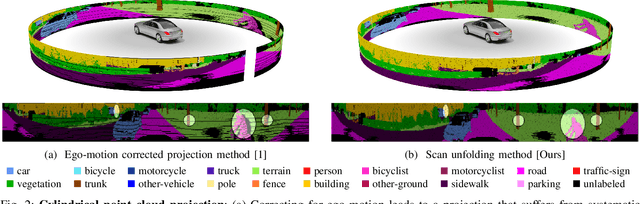
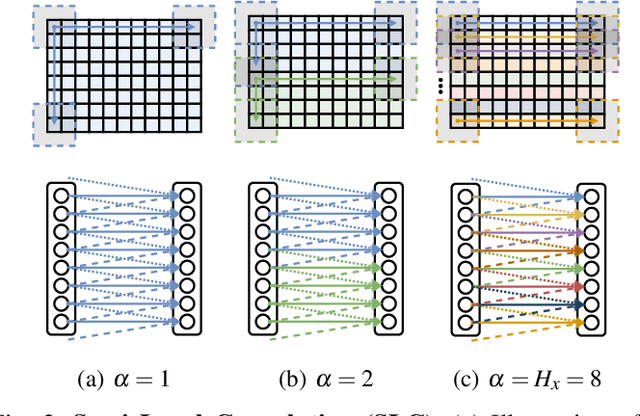
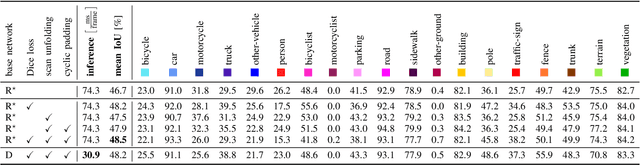
Autonomous vehicles need to have a semantic understanding of the three-dimensional world around them in order to reason about their environment. State of the art methods use deep neural networks to predict semantic classes for each point in a LiDAR scan. A powerful and efficient way to process LiDAR measurements is to use two-dimensional, image-like projections. In this work, we perform a comprehensive experimental study of image-based semantic segmentation architectures for LiDAR point clouds. We demonstrate various techniques to boost the performance and to improve runtime as well as memory constraints. First, we examine the effect of network size and suggest that much faster inference times can be achieved at a very low cost to accuracy. Next, we introduce an improved point cloud projection technique that does not suffer from systematic occlusions. We use a cyclic padding mechanism that provides context at the horizontal field-of-view boundaries. In a third part, we perform experiments with a soft Dice loss function that directly optimizes for the intersection-over-union metric. Finally, we propose a new kind of convolution layer with a reduced amount of weight-sharing along one of the two spatial dimensions, addressing the large difference in appearance along the vertical axis of a LiDAR scan. We propose a final set of the above methods with which the model achieves an increase of 3.2% in mIoU segmentation performance over the baseline while requiring only 42% of the original inference time.