 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Realism Metric for Generated LiDAR Point Clouds
Aug 31, 2022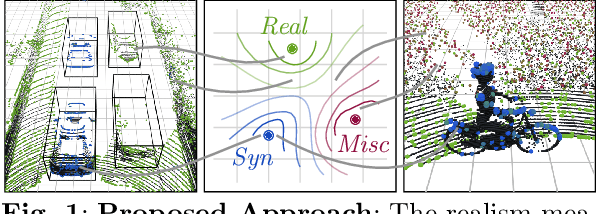
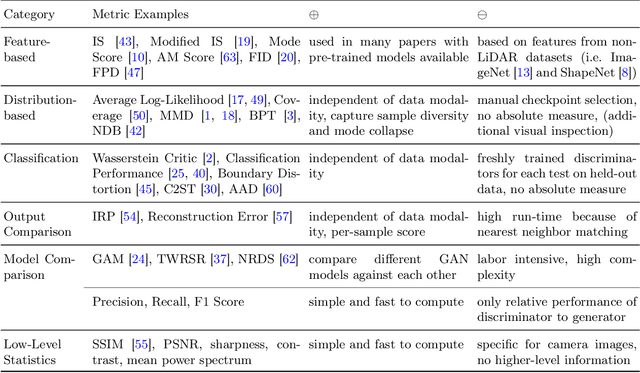
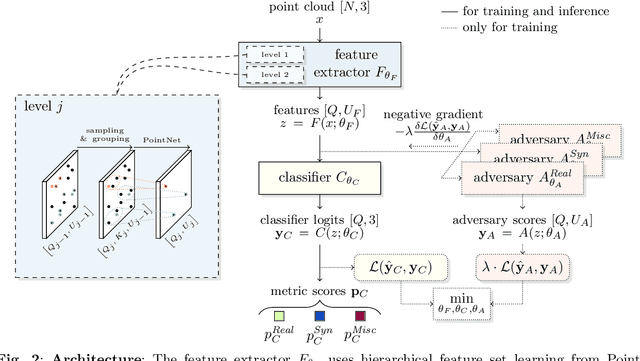
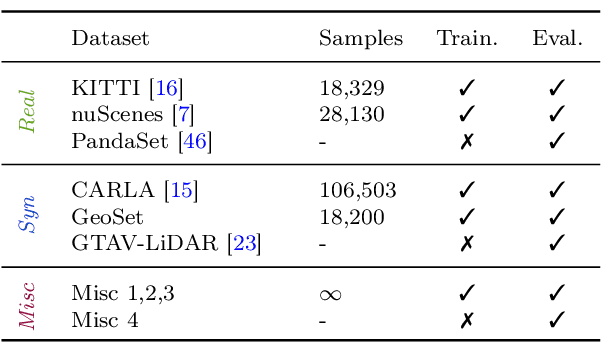
A considerable amount of research is concerned with the generation of realistic sensor data. LiDAR point clouds are generated by complex simulations or learned generative models. The generated data is usually exploited to enable or improve downstream perception algorithms. Two major questions arise from these procedures: First, how to evaluate the realism of the generated data? Second, does more realistic data also lead to better perception performance? This paper addresses both questions and presents a novel metric to quantify the realism of LiDAR point clouds. Relevant features are learned from real-world and synthetic point clouds by training on a proxy classification task. In a series of experiments, we demonstrate the application of our metric to determine the realism of generated LiDAR data and compare the realism estimation of our metric to the performance of a segmentation model. We confirm that our metric provides an indication for the downstream segmentation performance.
Point Cloud Generation with Continuous Conditioning
Feb 17, 2022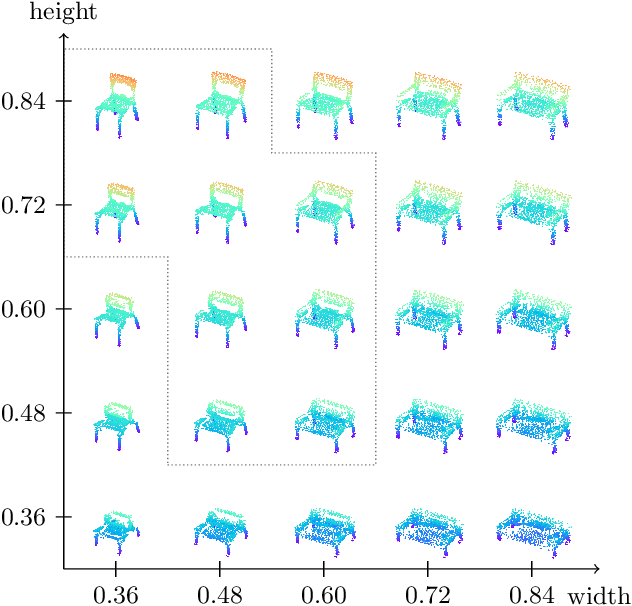
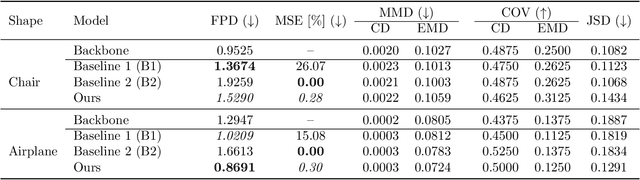
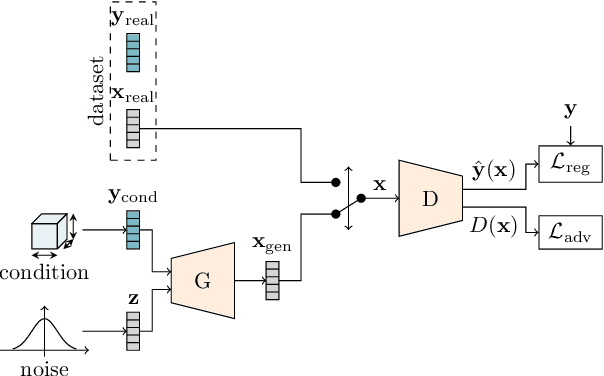

Generative models can be used to synthesize 3D objects of high quality and diversity. However, there is typically no control over the properties of the generated object.This paper proposes a novel generative adversarial network (GAN) setup that generates 3D point cloud shapes conditioned on a continuous parameter. In an exemplary application, we use this to guide the generative process to create a 3D object with a custom-fit shape. We formulate this generation process in a multi-task setting by using the concept of auxiliary classifier GANs. Further, we propose to sample the generator label input for training from a kernel density estimation (KDE) of the dataset. Our ablations show that this leads to significant performance increase in regions with few samples. Extensive quantitative and qualitative experiments show that we gain explicit control over the object dimensions while maintaining good generation quality and diversity.
Semi-Local Convolutions for LiDAR Scan Processing
Nov 30, 2021
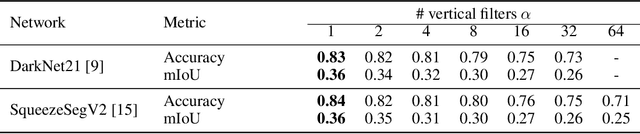

A number of applications, such as mobile robots or automated vehicles, use LiDAR sensors to obtain detailed information about their three-dimensional surroundings. Many methods use image-like projections to efficiently process these LiDAR measurements and use deep convolutional neural networks to predict semantic classes for each point in the scan. The spatial stationary assumption enables the usage of convolutions. However, LiDAR scans exhibit large differences in appearance over the vertical axis. Therefore, we propose semi local convolution (SLC), a convolution layer with reduced amount of weight-sharing along the vertical dimension. We are first to investigate the usage of such a layer independent of any other model changes. Our experiments did not show any improvement over traditional convolution layers in terms of segmentation IoU or accuracy.
* arXiv admin note: text overlap with arXiv:2004.11803
Quantifying point cloud realism through adversarially learned latent representations
Sep 24, 2021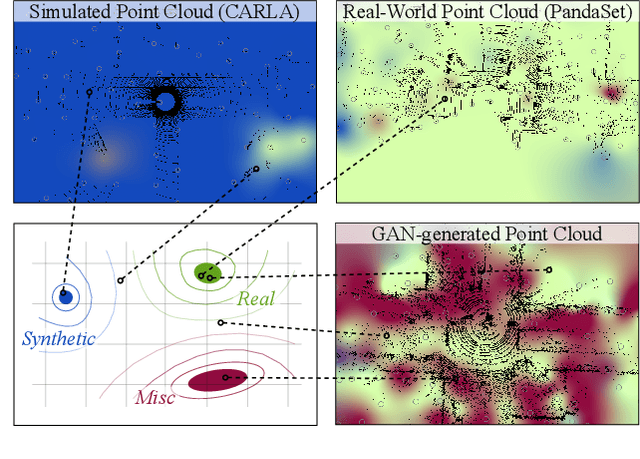
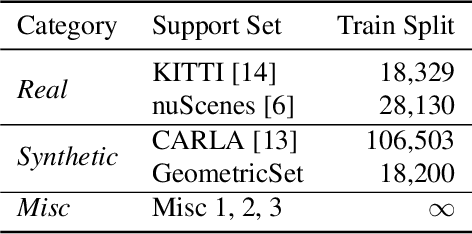
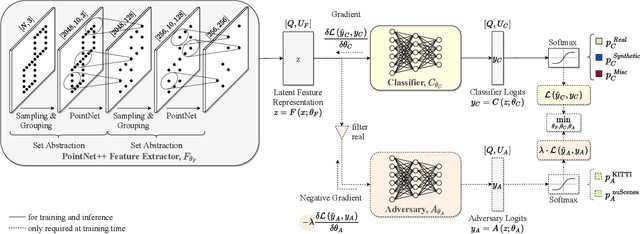
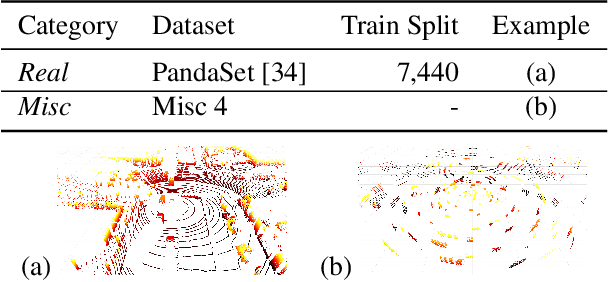
Judging the quality of samples synthesized by generative models can be tedious and time consuming, especially for complex data structures, such as point clouds. This paper presents a novel approach to quantify the realism of local regions in LiDAR point clouds. Relevant features are learned from real-world and synthetic point clouds by training on a proxy classification task. Inspired by fair networks, we use an adversarial technique to discourage the encoding of dataset-specific information. The resulting metric can assign a quality score to samples without requiring any task specific annotations. In a series of experiments, we confirm the soundness of our metric by applying it in controllable task setups and on unseen data. Additional experiments show reliable interpolation capabilities of the metric between data with varying degree of realism. As one important application, we demonstrate how the local realism score can be used for anomaly detection in point clouds.
A Survey on Deep Domain Adaptation for LiDAR Perception
Jun 07, 2021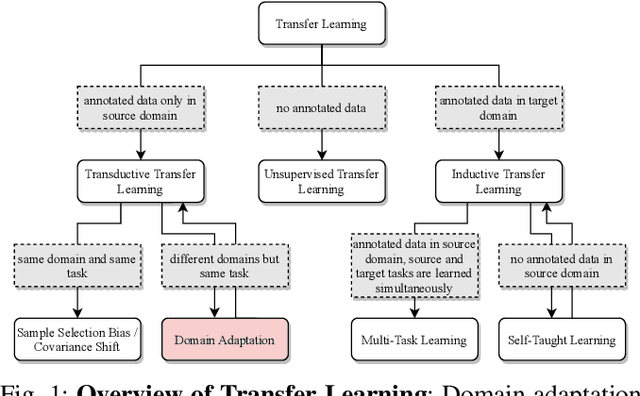
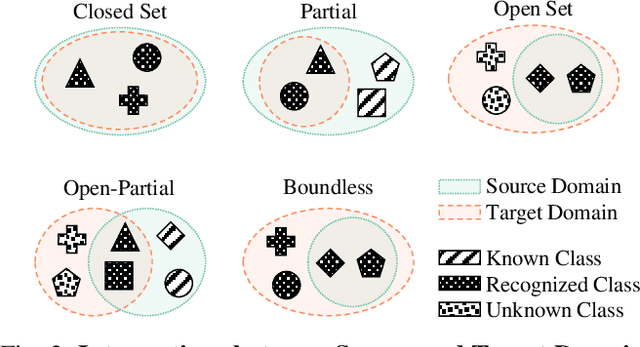
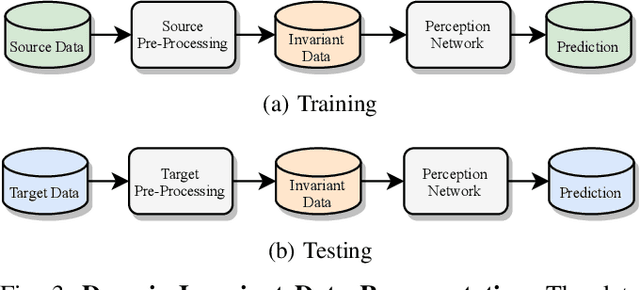
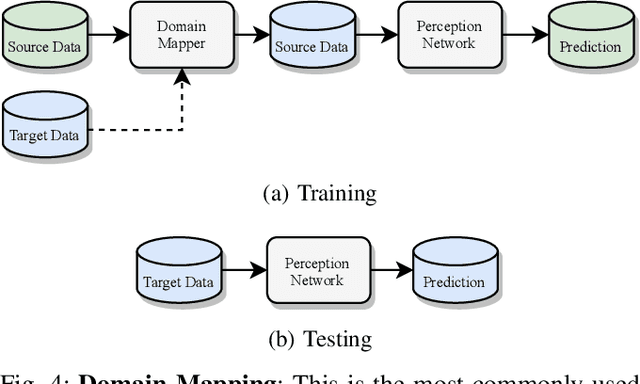
Scalable systems for automated driving have to reliably cope with an open-world setting. This means, the perception systems are exposed to drastic domain shifts, like changes in weather conditions, time-dependent aspects, or geographic regions. Covering all domains with annotated data is impossible because of the endless variations of domains and the time-consuming and expensive annotation process. Furthermore, fast development cycles of the system additionally introduce hardware changes, such as sensor types and vehicle setups, and the required knowledge transfer from simulation. To enable scalable automated driving, it is therefore crucial to address these domain shifts in a robust and efficient manner. Over the last years, a vast amount of different domain adaptation techniques evolved. There already exists a number of survey papers for domain adaptation on camera images, however, a survey for LiDAR perception is absent. Nevertheless, LiDAR is a vital sensor for automated driving that provides detailed 3D scans of the vehicle's surroundings. To stimulate future research, this paper presents a comprehensive review of recent progress in domain adaptation methods and formulates interesting research questions specifically targeted towards LiDAR perception.
Scan-based Semantic Segmentation of LiDAR Point Clouds: An Experimental Study
Apr 28, 2020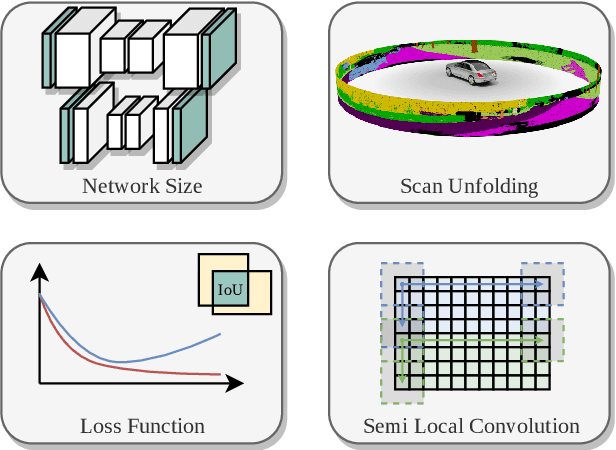
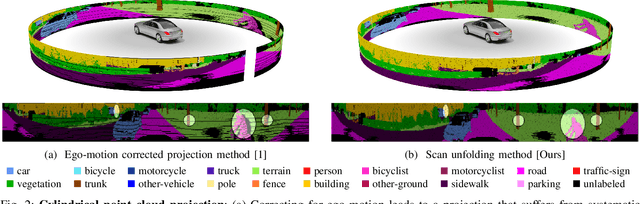
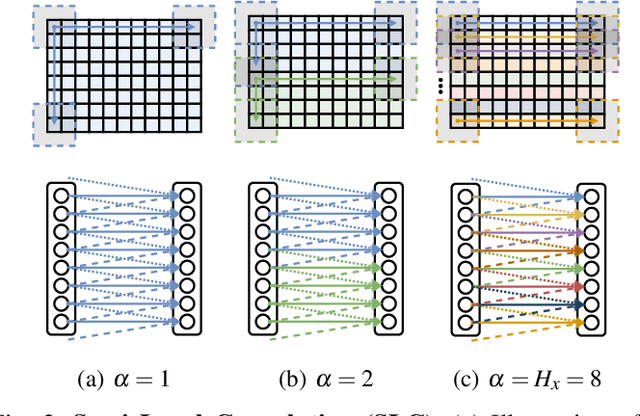
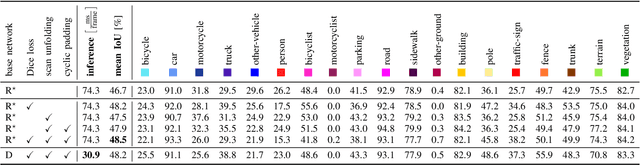
Autonomous vehicles need to have a semantic understanding of the three-dimensional world around them in order to reason about their environment. State of the art methods use deep neural networks to predict semantic classes for each point in a LiDAR scan. A powerful and efficient way to process LiDAR measurements is to use two-dimensional, image-like projections. In this work, we perform a comprehensive experimental study of image-based semantic segmentation architectures for LiDAR point clouds. We demonstrate various techniques to boost the performance and to improve runtime as well as memory constraints. First, we examine the effect of network size and suggest that much faster inference times can be achieved at a very low cost to accuracy. Next, we introduce an improved point cloud projection technique that does not suffer from systematic occlusions. We use a cyclic padding mechanism that provides context at the horizontal field-of-view boundaries. In a third part, we perform experiments with a soft Dice loss function that directly optimizes for the intersection-over-union metric. Finally, we propose a new kind of convolution layer with a reduced amount of weight-sharing along one of the two spatial dimensions, addressing the large difference in appearance along the vertical axis of a LiDAR scan. We propose a final set of the above methods with which the model achieves an increase of 3.2% in mIoU segmentation performance over the baseline while requiring only 42% of the original inference time.
CNN-based synthesis of realistic high-resolution LiDAR data
Jun 28, 2019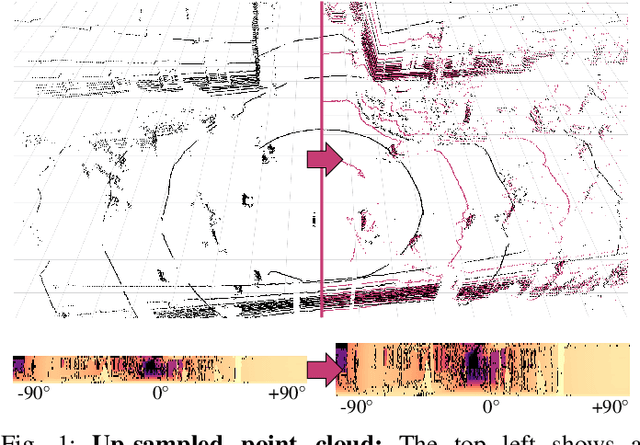
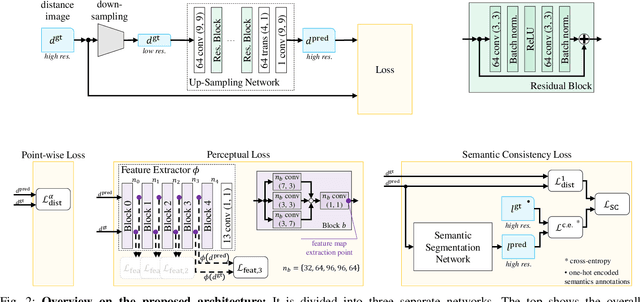
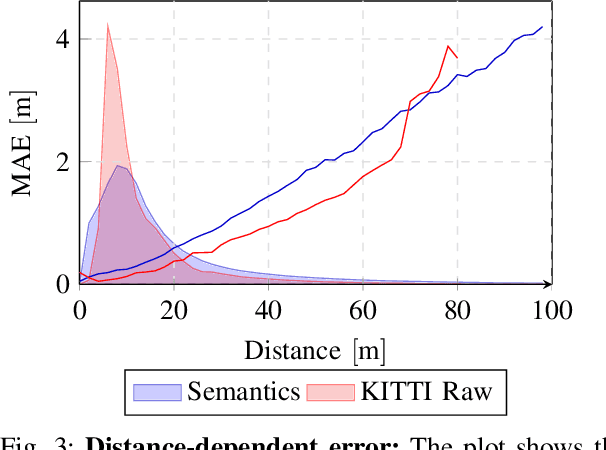
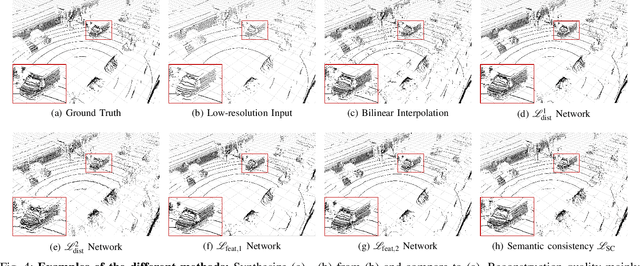
This paper presents a novel CNN-based approach for synthesizing high-resolution LiDAR point cloud data. Our approach generates semantically and perceptually realistic results with guidance from specialized loss-functions. First, we utilize a modified per-point loss that addresses missing LiDAR point measurements. Second, we align the quality of our generated output with real-world sensor data by applying a perceptual loss. In large-scale experiments on real-world datasets, we evaluate both the geometric accuracy and semantic segmentation performance using our generated data vs. ground truth. In a mean opinion score testing we further assess the perceptual quality of our generated point clouds. Our results demonstrate a significant quantitative and qualitative improvement in both geometry and semantics over traditional non CNN-based up-sampling methods.