 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBikeActions: An Open Platform and Benchmark for Cyclist-Centric VRU Action Recognition
Jan 15, 2026Anticipating the intentions of Vulnerable Road Users (VRUs) is a critical challenge for safe autonomous driving (AD) and mobile robotics. While current research predominantly focuses on pedestrian crossing behaviors from a vehicle's perspective, interactions within dense shared spaces remain underexplored. To bridge this gap, we introduce FUSE-Bike, the first fully open perception platform of its kind. Equipped with two LiDARs, a camera, and GNSS, it facilitates high-fidelity, close-range data capture directly from a cyclist's viewpoint. Leveraging this platform, we present BikeActions, a novel multi-modal dataset comprising 852 annotated samples across 5 distinct action classes, specifically tailored to improve VRU behavior modeling. We establish a rigorous benchmark by evaluating state-of-the-art graph convolution and transformer-based models on our publicly released data splits, establishing the first performance baselines for this challenging task. We release the full dataset together with data curation tools, the open hardware design, and the benchmark code to foster future research in VRU action understanding under https://iv.ee.hm.edu/bikeactions/.
SatMap: Revisiting Satellite Maps as Prior for Online HD Map Construction
Jan 15, 2026Online high-definition (HD) map construction is an essential part of a safe and robust end-to-end autonomous driving (AD) pipeline. Onboard camera-based approaches suffer from limited depth perception and degraded accuracy due to occlusion. In this work, we propose SatMap, an online vectorized HD map estimation method that integrates satellite maps with multi-view camera observations and directly predicts a vectorized HD map for downstream prediction and planning modules. Our method leverages lane-level semantics and texture from satellite imagery captured from a Bird's Eye View (BEV) perspective as a global prior, effectively mitigating depth ambiguity and occlusion. In our experiments on the nuScenes dataset, SatMap achieves 34.8% mAP performance improvement over the camera-only baseline and 8.5% mAP improvement over the camera-LiDAR fusion baseline. Moreover, we evaluate our model in long-range and adverse weather conditions to demonstrate the advantages of using a satellite prior map. Source code will be available at https://iv.ee.hm.edu/satmap/.
DeepUrban: Interaction-Aware Trajectory Prediction and Planning for Automated Driving by Aerial Imagery
Jan 15, 2026The efficacy of autonomous driving systems hinges critically on robust prediction and planning capabilities. However, current benchmarks are impeded by a notable scarcity of scenarios featuring dense traffic, which is essential for understanding and modeling complex interactions among road users. To address this gap, we collaborated with our industrial partner, DeepScenario, to develop DeepUrban-a new drone dataset designed to enhance trajectory prediction and planning benchmarks focusing on dense urban settings. DeepUrban provides a rich collection of 3D traffic objects, extracted from high-resolution images captured over urban intersections at approximately 100 meters altitude. The dataset is further enriched with comprehensive map and scene information to support advanced modeling and simulation tasks. We evaluate state-of-the-art (SOTA) prediction and planning methods, and conducted experiments on generalization capabilities. Our findings demonstrate that adding DeepUrban to nuScenes can boost the accuracy of vehicle predictions and planning, achieving improvements up to 44.1 % / 44.3% on the ADE / FDE metrics. Website: https://iv.ee.hm.edu/deepurban
Context-based Motion Retrieval using Open Vocabulary Methods for Autonomous Driving
Aug 01, 2025Autonomous driving systems must operate reliably in safety-critical scenarios, particularly those involving unusual or complex behavior by Vulnerable Road Users (VRUs). Identifying these edge cases in driving datasets is essential for robust evaluation and generalization, but retrieving such rare human behavior scenarios within the long tail of large-scale datasets is challenging. To support targeted evaluation of autonomous driving systems in diverse, human-centered scenarios, we propose a novel context-aware motion retrieval framework. Our method combines Skinned Multi-Person Linear (SMPL)-based motion sequences and corresponding video frames before encoding them into a shared multimodal embedding space aligned with natural language. Our approach enables the scalable retrieval of human behavior and their context through text queries. This work also introduces our dataset WayMoCo, an extension of the Waymo Open Dataset. It contains automatically labeled motion and scene context descriptions derived from generated pseudo-ground-truth SMPL sequences and corresponding image data. Our approach outperforms state-of-the-art models by up to 27.5% accuracy in motion-context retrieval, when evaluated on the WayMoCo dataset.
Generative AI for Autonomous Driving: A Review
May 21, 2025Generative AI (GenAI) is rapidly advancing the field of Autonomous Driving (AD), extending beyond traditional applications in text, image, and video generation. We explore how generative models can enhance automotive tasks, such as static map creation, dynamic scenario generation, trajectory forecasting, and vehicle motion planning. By examining multiple generative approaches ranging from Variational Autoencoder (VAEs) over Generative Adversarial Networks (GANs) and Invertible Neural Networks (INNs) to Generative Transformers (GTs) and Diffusion Models (DMs), we highlight and compare their capabilities and limitations for AD-specific applications. Additionally, we discuss hybrid methods integrating conventional techniques with generative approaches, and emphasize their improved adaptability and robustness. We also identify relevant datasets and outline open research questions to guide future developments in GenAI. Finally, we discuss three core challenges: safety, interpretability, and realtime capabilities, and present recommendations for image generation, dynamic scenario generation, and planning.
BEVDriver: Leveraging BEV Maps in LLMs for Robust Closed-Loop Driving
Mar 05, 2025



Autonomous driving has the potential to set the stage for more efficient future mobility, requiring the research domain to establish trust through safe, reliable and transparent driving. Large Language Models (LLMs) possess reasoning capabilities and natural language understanding, presenting the potential to serve as generalized decision-makers for ego-motion planning that can interact with humans and navigate environments designed for human drivers. While this research avenue is promising, current autonomous driving approaches are challenged by combining 3D spatial grounding and the reasoning and language capabilities of LLMs. We introduce BEVDriver, an LLM-based model for end-to-end closed-loop driving in CARLA that utilizes latent BEV features as perception input. BEVDriver includes a BEV encoder to efficiently process multi-view images and 3D LiDAR point clouds. Within a common latent space, the BEV features are propagated through a Q-Former to align with natural language instructions and passed to the LLM that predicts and plans precise future trajectories while considering navigation instructions and critical scenarios. On the LangAuto benchmark, our model reaches up to 18.9% higher performance on the Driving Score compared to SoTA methods.
Weakly Supervised Multi-Modal 3D Human Body Pose Estimation for Autonomous Driving
Jul 27, 2023



Accurate 3D human pose estimation (3D HPE) is crucial for enabling autonomous vehicles (AVs) to make informed decisions and respond proactively in critical road scenarios. Promising results of 3D HPE have been gained in several domains such as human-computer interaction, robotics, sports and medical analytics, often based on data collected in well-controlled laboratory environments. Nevertheless, the transfer of 3D HPE methods to AVs has received limited research attention, due to the challenges posed by obtaining accurate 3D pose annotations and the limited suitability of data from other domains. We present a simple yet efficient weakly supervised approach for 3D HPE in the AV context by employing a high-level sensor fusion between camera and LiDAR data. The weakly supervised setting enables training on the target datasets without any 2D/3D keypoint labels by using an off-the-shelf 2D joint extractor and pseudo labels generated from LiDAR to image projections. Our approach outperforms state-of-the-art results by up to $\sim$ 13% on the Waymo Open Dataset in the weakly supervised setting and achieves state-of-the-art results in the supervised setting.
Point Cloud Generation with Continuous Conditioning
Feb 17, 2022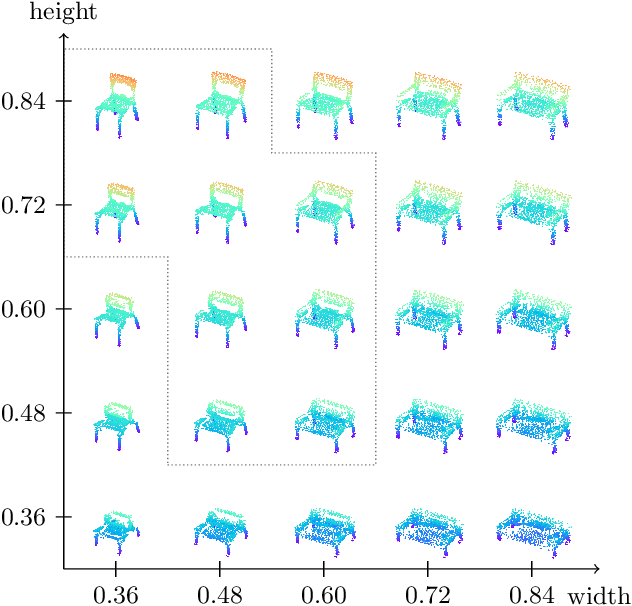
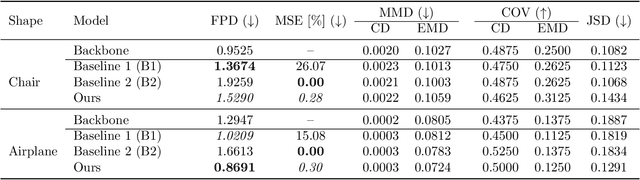
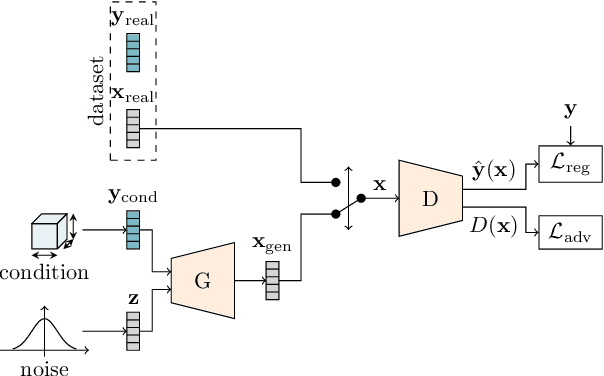

Generative models can be used to synthesize 3D objects of high quality and diversity. However, there is typically no control over the properties of the generated object.This paper proposes a novel generative adversarial network (GAN) setup that generates 3D point cloud shapes conditioned on a continuous parameter. In an exemplary application, we use this to guide the generative process to create a 3D object with a custom-fit shape. We formulate this generation process in a multi-task setting by using the concept of auxiliary classifier GANs. Further, we propose to sample the generator label input for training from a kernel density estimation (KDE) of the dataset. Our ablations show that this leads to significant performance increase in regions with few samples. Extensive quantitative and qualitative experiments show that we gain explicit control over the object dimensions while maintaining good generation quality and diversity.