 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSA: Localized Semantic Alignment for Enhancing Temporal Consistency in Traffic Video Generation
Feb 05, 2026Controllable video generation has emerged as a versatile tool for autonomous driving, enabling realistic synthesis of traffic scenarios. However, existing methods depend on control signals at inference time to guide the generative model towards temporally consistent generation of dynamic objects, limiting their utility as scalable and generalizable data engines. In this work, we propose Localized Semantic Alignment (LSA), a simple yet effective framework for fine-tuning pre-trained video generation models. LSA enhances temporal consistency by aligning semantic features between ground-truth and generated video clips. Specifically, we compare the output of an off-the-shelf feature extraction model between the ground-truth and generated video clips localized around dynamic objects inducing a semantic feature consistency loss. We fine-tune the base model by combining this loss with the standard diffusion loss. The model fine-tuned for a single epoch with our novel loss outperforms the baselines in common video generation evaluation metrics. To further test the temporal consistency in generated videos we adapt two additional metrics from object detection task, namely mAP and mIoU. Extensive experiments on nuScenes and KITTI datasets show the effectiveness of our approach in enhancing temporal consistency in video generation without the need for external control signals during inference and any computational overheads.
TQD-Track: Temporal Query Denoising for 3D Multi-Object Tracking
Apr 04, 2025Query denoising has become a standard training strategy for DETR-based detectors by addressing the slow convergence issue. Besides that, query denoising can be used to increase the diversity of training samples for modeling complex scenarios which is critical for Multi-Object Tracking (MOT), showing its potential in MOT application. Existing approaches integrate query denoising within the tracking-by-attention paradigm. However, as the denoising process only happens within the single frame, it cannot benefit the tracker to learn temporal-related information. In addition, the attention mask in query denoising prevents information exchange between denoising and object queries, limiting its potential in improving association using self-attention. To address these issues, we propose TQD-Track, which introduces Temporal Query Denoising (TQD) tailored for MOT, enabling denoising queries to carry temporal information and instance-specific feature representation. We introduce diverse noise types onto denoising queries that simulate real-world challenges in MOT. We analyze our proposed TQD for different tracking paradigms, and find out the paradigm with explicit learned data association module, e.g. tracking-by-detection or alternating detection and association, benefit from TQD by a larger margin. For these paradigms, we further design an association mask in the association module to ensure the consistent interaction between track and detection queries as during inference. Extensive experiments on the nuScenes dataset demonstrate that our approach consistently enhances different tracking methods by only changing the training process, especially the paradigms with explicit association module.
SVS-GAN: Leveraging GANs for Semantic Video Synthesis
Sep 09, 2024


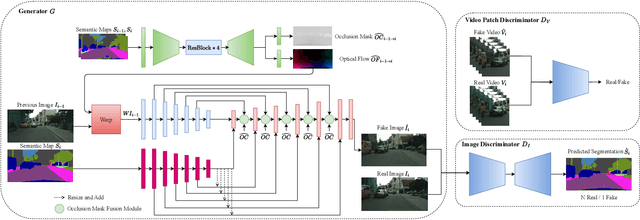
In recent years, there has been a growing interest in Semantic Image Synthesis (SIS) through the use of Generative Adversarial Networks (GANs) and diffusion models. This field has seen innovations such as the implementation of specialized loss functions tailored for this task, diverging from the more general approaches in Image-to-Image (I2I) translation. While the concept of Semantic Video Synthesis (SVS)$\unicode{x2013}$the generation of temporally coherent, realistic sequences of images from semantic maps$\unicode{x2013}$is newly formalized in this paper, some existing methods have already explored aspects of this field. Most of these approaches rely on generic loss functions designed for video-to-video translation or require additional data to achieve temporal coherence. In this paper, we introduce the SVS-GAN, a framework specifically designed for SVS, featuring a custom architecture and loss functions. Our approach includes a triple-pyramid generator that utilizes SPADE blocks. Additionally, we employ a U-Net-based network for the image discriminator, which performs semantic segmentation for the OASIS loss. Through this combination of tailored architecture and objective engineering, our framework aims to bridge the existing gap between SIS and SVS, outperforming current state-of-the-art models on datasets like Cityscapes and KITTI-360.
The EuroCity Persons Dataset: A Novel Benchmark for Object Detection
Jun 05, 2018
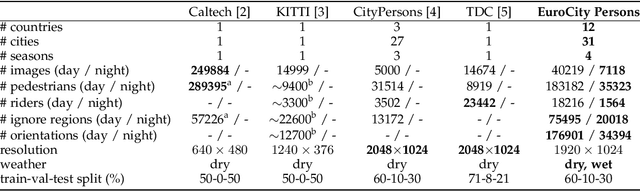

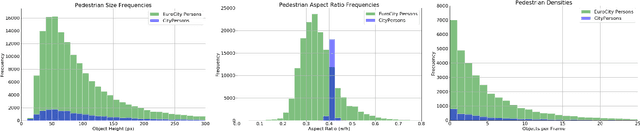
Big data has had a great share in the success of deep learning in computer vision. Recent works suggest that there is significant further potential to increase object detection performance by utilizing even bigger datasets. In this paper, we introduce the EuroCity Persons dataset, which provides a large number of highly diverse, accurate and detailed annotations of pedestrians, cyclists and other riders in urban traffic scenes. The images for this dataset were collected on-board a moving vehicle in 31 cities of 12 European countries. With over 238200 person instances manually labeled in over 47300 images, EuroCity Persons is nearly one order of magnitude larger than person datasets used previously for benchmarking. The dataset furthermore contains a large number of person orientation annotations (over 211200). We optimize four state-of-the-art deep learning approaches (Faster R-CNN, R-FCN, SSD and YOLOv3) to serve as baselines for the new object detection benchmark. In experiments with previous datasets we analyze the generalization capabilities of these detectors when trained with the new dataset. We furthermore study the effect of the training set size, the dataset diversity (day- vs. night-time, geographical region), the dataset detail (i.e. availability of object orientation information) and the annotation quality on the detector performance. Finally, we analyze error sources and discuss the road ahead.