 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVS-GAN: Leveraging GANs for Semantic Video Synthesis
Sep 09, 2024


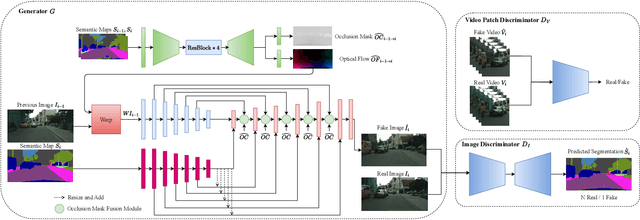
In recent years, there has been a growing interest in Semantic Image Synthesis (SIS) through the use of Generative Adversarial Networks (GANs) and diffusion models. This field has seen innovations such as the implementation of specialized loss functions tailored for this task, diverging from the more general approaches in Image-to-Image (I2I) translation. While the concept of Semantic Video Synthesis (SVS)$\unicode{x2013}$the generation of temporally coherent, realistic sequences of images from semantic maps$\unicode{x2013}$is newly formalized in this paper, some existing methods have already explored aspects of this field. Most of these approaches rely on generic loss functions designed for video-to-video translation or require additional data to achieve temporal coherence. In this paper, we introduce the SVS-GAN, a framework specifically designed for SVS, featuring a custom architecture and loss functions. Our approach includes a triple-pyramid generator that utilizes SPADE blocks. Additionally, we employ a U-Net-based network for the image discriminator, which performs semantic segmentation for the OASIS loss. Through this combination of tailored architecture and objective engineering, our framework aims to bridge the existing gap between SIS and SVS, outperforming current state-of-the-art models on datasets like Cityscapes and KITTI-360.