 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Detection Based on Total Variation Estimation
Jan 22, 2026This paper introduces a novel approach to securing machine learning model deployments against potential distribution shifts in practical applications, the Total Variation Out-of-Distribution (TV-OOD) detection method. Existing methods have produced satisfactory results, but TV-OOD improves upon these by leveraging the Total Variation Network Estimator to calculate each input's contribution to the overall total variation. By defining this as the total variation score, TV-OOD discriminates between in- and out-of-distribution data. The method's efficacy was tested across a range of models and datasets, consistently yielding results in image classification tasks that were either comparable or superior to those achieved by leading-edge out-of-distribution detection techniques across all evaluation metrics.
NSR-Boost: A Neuro-Symbolic Residual Boosting Framework for Industrial Legacy Models
Jan 15, 2026Although the Gradient Boosted Decision Trees (GBDTs) dominate industrial tabular applications, upgrading legacy models in high-concurrency production environments still faces prohibitive retraining costs and systemic risks. To address this problem, we present NSR-Boost, a neuro-symbolic residual boosting framework designed specifically for industrial scenarios. Its core advantage lies in being "non-intrusive". It treats the legacy model as a frozen model and performs targeted repairs on "hard regions" where predictions fail. The framework comprises three key stages: first, finding hard regions through residuals, then generating interpretable experts by generating symbolic code structures using Large Language Model (LLM) and fine-tuning parameters using Bayesian optimization, and finally dynamically integrating experts with legacy model output through a lightweight aggregator. We report on the successful deployment of NSR-Boost within the core financial risk control system at Qfin Holdings. This framework not only significantly outperforms state-of-the-art (SOTA) baselines across six public datasets and one private dataset, more importantly, shows excellent performance gains on real-world online data. In conclusion, it effectively captures long-tail risks missed by traditional models and offers a safe, low-cost evolutionary paradigm for industry.
MHTTS: Fast multi-head text-to-speech for spontaneous speech with imperfect transcription
Feb 04, 2022Neural network based end-to-end Text-to-Speech (TTS) has greatly improved the quality of synthesized speech. While how to use massive spontaneous speech without transcription efficiently still remains an open problem. In this paper, we propose MHTTS, a fast multi-speaker TTS system that is robust to transcription errors and speaking style speech data. Specifically, we introduce a multi-head model and transfer text information from high-quality corpus with manual transcription to spontaneous speech with imperfectly recognized transcription by jointly training them. MHTTS has three advantages: 1) Our system synthesizes better quality multi-speaker voice with faster inference speed. 2) Our system is capable of transferring correct text information to data with imperfect transcription, simulated using corruption, or provided by an Automatic Speech Recogniser (ASR). 3) Our system can utilize massive real spontaneous speech with imperfect transcription and synthesize expressive voice.
FPUAS : Fully Parallel UFANS-based End-to-End Acoustic System with 10x Speed Up
Dec 18, 2018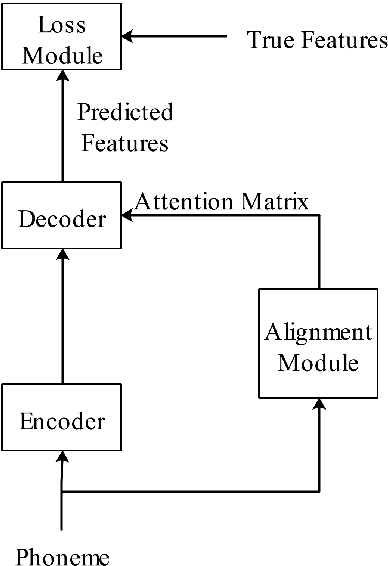
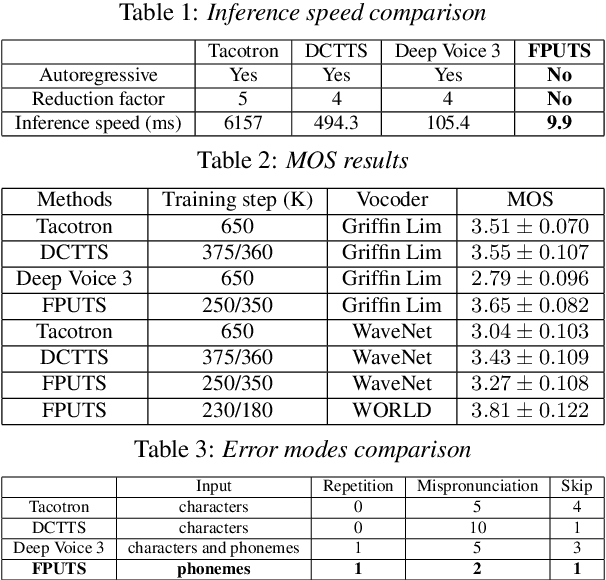
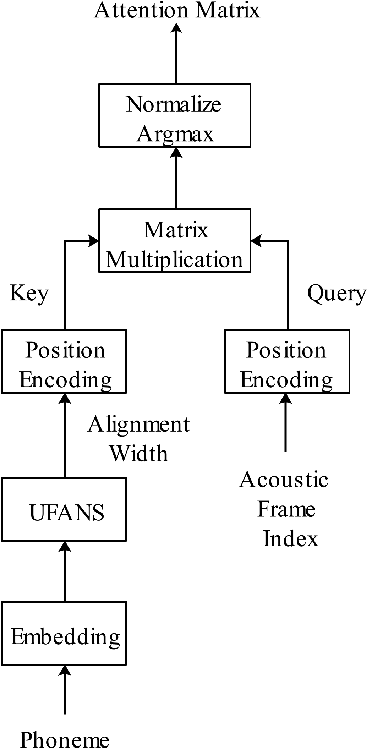
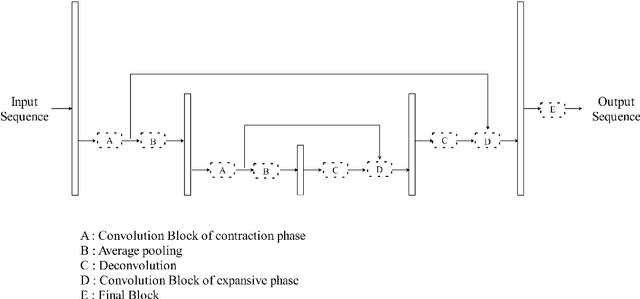
A lightweight end-to-end acoustic system is crucial in the deployment of text-to-speech tasks. Finding one that produces good audios with small time latency and fewer errors remains a problem. In this paper, we propose a new non-autoregressive, fully parallel acoustic system that utilizes a new attention structure and a recently proposed convolutional structure. Compared with the most popular end-to-end text-to-speech systems, our acoustic system can produce equal or better quality audios with fewer errors and reach at least 10 times speed up of inference.