Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPUAS : Fully Parallel UFANS-based End-to-End Acoustic System with 10x Speed Up
Paper and Code
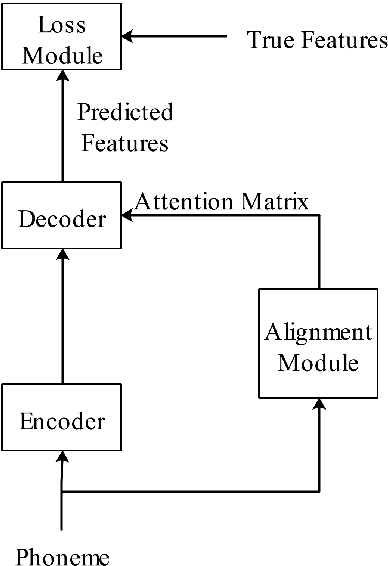
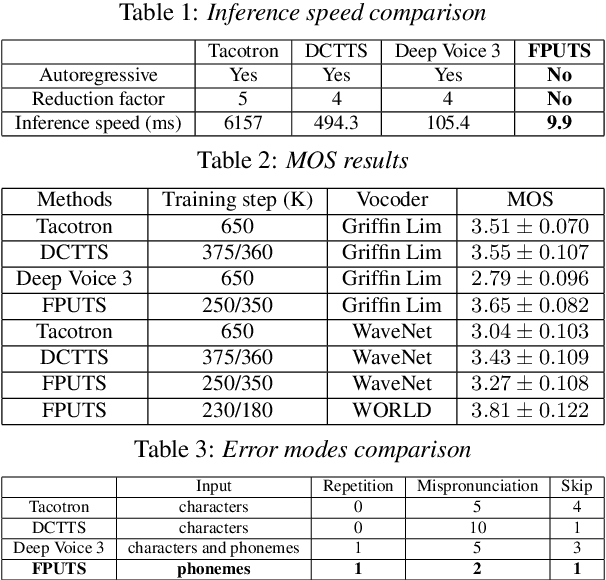
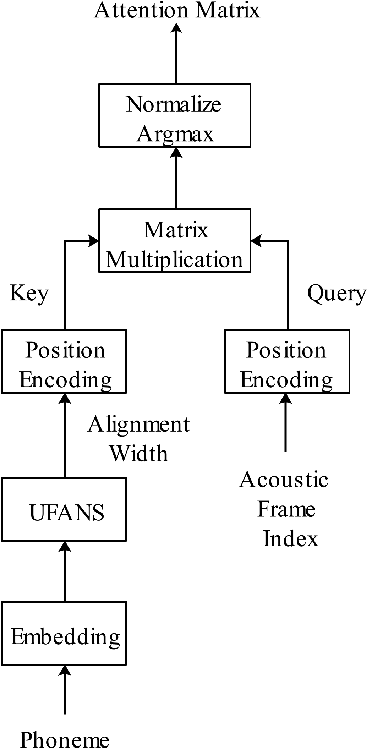
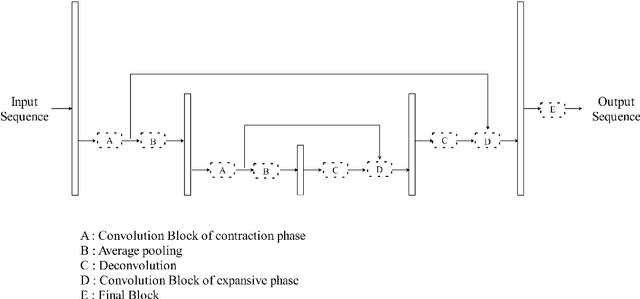
A lightweight end-to-end acoustic system is crucial in the deployment of text-to-speech tasks. Finding one that produces good audios with small time latency and fewer errors remains a problem. In this paper, we propose a new non-autoregressive, fully parallel acoustic system that utilizes a new attention structure and a recently proposed convolutional structure. Compared with the most popular end-to-end text-to-speech systems, our acoustic system can produce equal or better quality audios with fewer errors and reach at least 10 times speed up of inference.
View paper on