 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised Contrastive Learning with Quantity Prompts for Moving Infrared Small Target Detection
Jul 03, 2025Different from general object detection, moving infrared small target detection faces huge challenges due to tiny target size and weak background contrast.Currently, most existing methods are fully-supervised, heavily relying on a large number of manual target-wise annotations. However, manually annotating video sequences is often expensive and time-consuming, especially for low-quality infrared frame images. Inspired by general object detection, non-fully supervised strategies ($e.g.$, weakly supervised) are believed to be potential in reducing annotation requirements. To break through traditional fully-supervised frameworks, as the first exploration work, this paper proposes a new weakly-supervised contrastive learning (WeCoL) scheme, only requires simple target quantity prompts during model training.Specifically, in our scheme, based on the pretrained segment anything model (SAM), a potential target mining strategy is designed to integrate target activation maps and multi-frame energy accumulation.Besides, contrastive learning is adopted to further improve the reliability of pseudo-labels, by calculating the similarity between positive and negative samples in feature subspace.Moreover, we propose a long-short term motion-aware learning scheme to simultaneously model the local motion patterns and global motion trajectory of small targets.The extensive experiments on two public datasets (DAUB and ITSDT-15K) verify that our weakly-supervised scheme could often outperform early fully-supervised methods. Even, its performance could reach over 90\% of state-of-the-art (SOTA) fully-supervised ones.
Mining In-distribution Attributes in Outliers for Out-of-distribution Detection
Dec 16, 2024Out-of-distribution (OOD) detection is indispensable for deploying reliable machine learning systems in real-world scenarios. Recent works, using auxiliary outliers in training, have shown good potential. However, they seldom concern the intrinsic correlations between in-distribution (ID) and OOD data. In this work, we discover an obvious correlation that OOD data usually possesses significant ID attributes. These attributes should be factored into the training process, rather than blindly suppressed as in previous approaches. Based on this insight, we propose a structured multi-view-based out-of-distribution detection learning (MVOL) framework, which facilitates rational handling of the intrinsic in-distribution attributes in outliers. We provide theoretical insights on the effectiveness of MVOL for OOD detection. Extensive experiments demonstrate the superiority of our framework to others. MVOL effectively utilizes both auxiliary OOD datasets and even wild datasets with noisy in-distribution data. Code is available at https://github.com/UESTC-nnLab/MVOL.
LGU-SLAM: Learnable Gaussian Uncertainty Matching with Deformable Correlation Sampling for Deep Visual SLAM
Oct 30, 2024Deep visual Simultaneous Localization and Mapping (SLAM) techniques, e.g., DROID, have made significant advancements by leveraging deep visual odometry on dense flow fields. In general, they heavily rely on global visual similarity matching. However, the ambiguous similarity interference in uncertain regions could often lead to excessive noise in correspondences, ultimately misleading SLAM in geometric modeling. To address this issue, we propose a Learnable Gaussian Uncertainty (LGU) matching. It mainly focuses on precise correspondence construction. In our scheme, a learnable 2D Gaussian uncertainty model is designed to associate matching-frame pairs. It could generate input-dependent Gaussian distributions for each correspondence map. Additionally, a multi-scale deformable correlation sampling strategy is devised to adaptively fine-tune the sampling of each direction by a priori look-up ranges, enabling reliable correlation construction. Furthermore, a KAN-bias GRU component is adopted to improve a temporal iterative enhancement for accomplishing sophisticated spatio-temporal modeling with limited parameters. The extensive experiments on real-world and synthetic datasets are conducted to validate the effectiveness and superiority of our method.
Queryable Prototype Multiple Instance Learning with Vision-Language Models for Incremental Whole Slide Image Classification
Oct 14, 2024

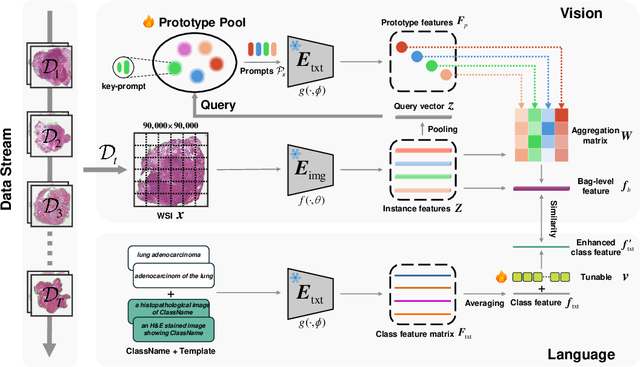

Whole Slide Image (WSI) classification has very significant applications in clinical pathology, e.g., tumor identification and cancer diagnosis. Currently, most research attention is focused on Multiple Instance Learning (MIL) using static datasets. One of the most obvious weaknesses of these methods is that they cannot efficiently preserve and utilize previously learned knowledge. With any new data arriving, classification models are required to be re-trained on both previous and current new data. To overcome this shortcoming and break through traditional vision modality, this paper proposes the first Vision-Language-based framework with Queryable Prototype Multiple Instance Learning (QPMIL-VL) specially designed for incremental WSI classification. This framework mainly consists of two information processing branches. One is for generating the bag-level feature by prototype-guided aggregating on the instance features. While the other is for enhancing the class feature through class ensemble, tunable vector and class similarity loss. The experiments on four TCGA datasets demonstrate that our QPMIL-VL framework is effective for incremental WSI classification and often significantly outperforms other compared methods, achieving state-of-the-art (SOTA) performance.
Interpretable Vision-Language Survival Analysis with Ordinal Inductive Bias for Computational Pathology
Sep 14, 2024



Histopathology Whole-Slide Images (WSIs) provide an important tool to assess cancer prognosis in computational pathology (CPATH). While existing survival analysis (SA) approaches have made exciting progress, they are generally limited to adopting highly-expressive architectures and only coarse-grained patient-level labels to learn prognostic visual representations from gigapixel WSIs. Such learning paradigm suffers from important performance bottlenecks, when facing present scarce training data and standard multi-instance learning (MIL) framework in CPATH. To break through it, this paper, for the first time, proposes a new Vision-Language-based SA (VLSA) paradigm. Concretely, (1) VLSA is driven by pathology VL foundation models. It no longer relies on high-capability networks and shows the advantage of data efficiency. (2) In vision-end, VLSA encodes prognostic language prior and then employs it as auxiliary signals to guide the aggregating of prognostic visual features at instance level, thereby compensating for the weak supervision in MIL. Moreover, given the characteristics of SA, we propose i) ordinal survival prompt learning to transform continuous survival labels into textual prompts; and ii) ordinal incidence function as prediction target to make SA compatible with VL-based prediction. VLSA's predictions can be interpreted intuitively by our Shapley values-based method. The extensive experiments on five datasets confirm the effectiveness of our scheme. Our VLSA could pave a new way for SA in CPATH by offering weakly-supervised MIL an effective means to learn valuable prognostic clues from gigapixel WSIs. Our source code is available at https://github.com/liupei101/VLSA.
Deformable Feature Alignment and Refinement for Moving Infrared Dim-small Target Detection
Jul 10, 2024



The detection of moving infrared dim-small targets has been a challenging and prevalent research topic. The current state-of-the-art methods are mainly based on ConvLSTM to aggregate information from adjacent frames to facilitate the detection of the current frame. However, these methods implicitly utilize motion information only in the training stage and fail to explicitly explore motion compensation, resulting in poor performance in the case of a video sequence including large motion. In this paper, we propose a Deformable Feature Alignment and Refinement (DFAR) method based on deformable convolution to explicitly use motion context in both the training and inference stages. Specifically, a Temporal Deformable Alignment (TDA) module based on the designed Dilated Convolution Attention Fusion (DCAF) block is developed to explicitly align the adjacent frames with the current frame at the feature level. Then, the feature refinement module adaptively fuses the aligned features and further aggregates useful spatio-temporal information by means of the proposed Attention-guided Deformable Fusion (AGDF) block. In addition, to improve the alignment of adjacent frames with the current frame, we extend the traditional loss function by introducing a new motion compensation loss. Extensive experimental results demonstrate that the proposed DFAR method achieves the state-of-the-art performance on two benchmark datasets including DAUB and IRDST.
Triple-domain Feature Learning with Frequency-aware Memory Enhancement for Moving Infrared Small Target Detection
Jun 11, 2024Moving infrared small target detection presents significant challenges due to tiny target sizes and low contrast against backgrounds. Currently-existing methods primarily focus on extracting target features only from the spatial-temporal domain. For further enhancing feature representation, more information domains such as frequency are believed to be potentially valuable. To extend target feature learning, we propose a new Triple-domain Strategy (Tridos) with the frequency-aware memory enhancement on the spatial-temporal domain. In our scheme, it effectively detaches and enhances frequency features by a local-global frequency-aware module with Fourier transform. Inspired by the human visual system, our memory enhancement aims to capture the target spatial relations between video frames. Furthermore, it encodes temporal dynamics motion features via differential learning and residual enhancing. Additionally, we further design a residual compensation unit to reconcile possible cross-domain feature mismatches. To our best knowledge, our Tridos is the first work to explore target feature learning comprehensively in spatial-temporal-frequency domains. The extensive experiments on three datasets (DAUB, ITSDT-15K, and IRDST) validate that our triple-domain learning scheme could be obviously superior to state-of-the-art ones. Source codes are available at https://github.com/UESTC-nnLab/Tridos.
Weakly-Supervised Residual Evidential Learning for Multi-Instance Uncertainty Estimation
May 07, 2024Uncertainty estimation (UE), as an effective means of quantifying predictive uncertainty, is crucial for safe and reliable decision-making, especially in high-risk scenarios. Existing UE schemes usually assume that there are completely-labeled samples to support fully-supervised learning. In practice, however, many UE tasks often have no sufficiently-labeled data to use, such as the Multiple Instance Learning (MIL) with only weak instance annotations. To bridge this gap, this paper, for the first time, addresses the weakly-supervised issue of Multi-Instance UE (MIUE) and proposes a new baseline scheme, Multi-Instance Residual Evidential Learning (MIREL). Particularly, at the fine-grained instance UE with only weak supervision, we derive a multi-instance residual operator through the Fundamental Theorem of Symmetric Functions. On this operator derivation, we further propose MIREL to jointly model the high-order predictive distribution at bag and instance levels for MIUE. Extensive experiments empirically demonstrate that our MIREL not only could often make existing MIL networks perform better in MIUE, but also could surpass representative UE methods by large margins, especially in instance-level UE tasks.
Pseudo-Bag Mixup Augmentation for Multiple Instance Learning-Based Whole Slide Image Classification
Jul 03, 2023



Given the special situation of modeling gigapixel images, multiple instance learning (MIL) has become one of the most important frameworks for Whole Slide Image (WSI) classification. In current practice, most MIL networks often face two unavoidable problems in training: i) insufficient WSI data, and ii) the sample memorization inclination inherent in neural networks. These problems may hinder MIL models from adequate and efficient training, suppressing the continuous performance promotion of classification models on WSIs. Inspired by the basic idea of Mixup, this paper proposes a new Pseudo-bag Mixup (PseMix) data augmentation scheme to improve the training of MIL models. This scheme generalizes the Mixup strategy for general images to special WSIs via pseudo-bags so as to be applied in MIL-based WSI classification. Cooperated by pseudo-bags, our PseMix fulfills the critical size alignment and semantic alignment in Mixup strategy. Moreover, it is designed as an efficient and decoupled method, neither involving time-consuming operations nor relying on MIL model predictions. Comparative experiments and ablation studies are specially designed to evaluate the effectiveness and advantages of our PseMix. Experimental results show that PseMix could often assist state-of-the-art MIL networks to refresh the classification performance on WSIs. Besides, it could also boost the generalization ability of MIL models, and promote their robustness to patch occlusion and noisy labels. Our source code is available at https://github.com/liupei101/PseMix.
ProtoDiv: Prototype-guided Division of Consistent Pseudo-bags for Whole-slide Image Classification
Apr 13, 2023
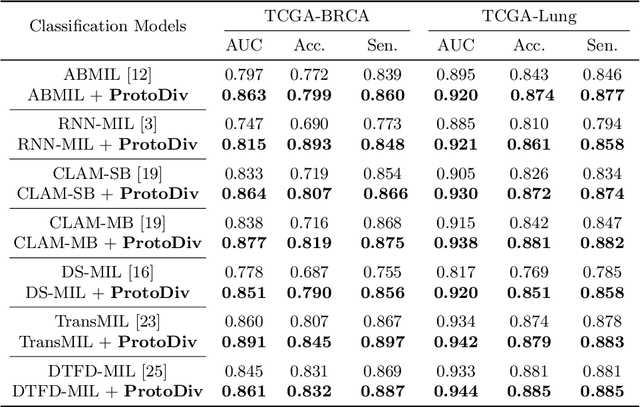

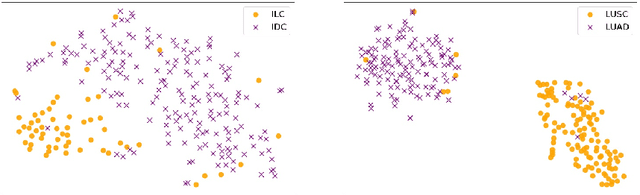
Due to the limitations of inadequate Whole-Slide Image (WSI) samples with weak labels, pseudo-bag-based multiple instance learning (MIL) appears as a vibrant prospect in WSI classification. However, the pseudo-bag dividing scheme, often crucial for classification performance, is still an open topic worth exploring. Therefore, this paper proposes a novel scheme, ProtoDiv, using a bag prototype to guide the division of WSI pseudo-bags. Rather than designing complex network architecture, this scheme takes a plugin-and-play approach to safely augment WSI data for effective training while preserving sample consistency. Furthermore, we specially devise an attention-based prototype that could be optimized dynamically in training to adapt to a classification task. We apply our ProtoDiv scheme on seven baseline models, and then carry out a group of comparison experiments on two public WSI datasets. Experiments confirm our ProtoDiv could usually bring obvious performance improvements to WSI classification.