 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Feature Alignment and Refinement for Moving Infrared Dim-small Target Detection
Jul 10, 2024



The detection of moving infrared dim-small targets has been a challenging and prevalent research topic. The current state-of-the-art methods are mainly based on ConvLSTM to aggregate information from adjacent frames to facilitate the detection of the current frame. However, these methods implicitly utilize motion information only in the training stage and fail to explicitly explore motion compensation, resulting in poor performance in the case of a video sequence including large motion. In this paper, we propose a Deformable Feature Alignment and Refinement (DFAR) method based on deformable convolution to explicitly use motion context in both the training and inference stages. Specifically, a Temporal Deformable Alignment (TDA) module based on the designed Dilated Convolution Attention Fusion (DCAF) block is developed to explicitly align the adjacent frames with the current frame at the feature level. Then, the feature refinement module adaptively fuses the aligned features and further aggregates useful spatio-temporal information by means of the proposed Attention-guided Deformable Fusion (AGDF) block. In addition, to improve the alignment of adjacent frames with the current frame, we extend the traditional loss function by introducing a new motion compensation loss. Extensive experimental results demonstrate that the proposed DFAR method achieves the state-of-the-art performance on two benchmark datasets including DAUB and IRDST.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022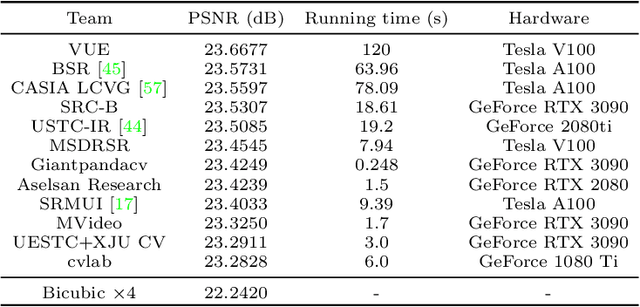
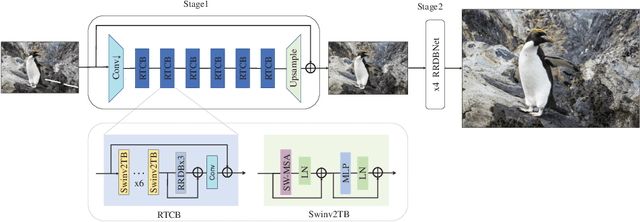

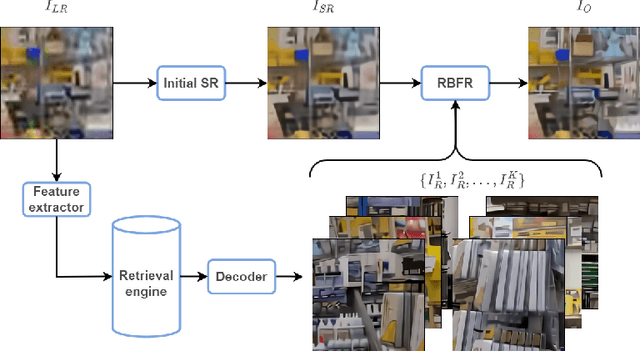
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022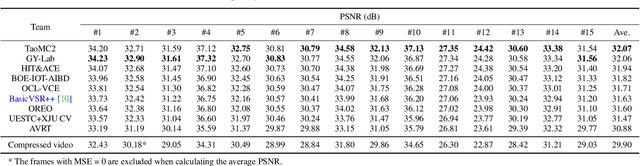
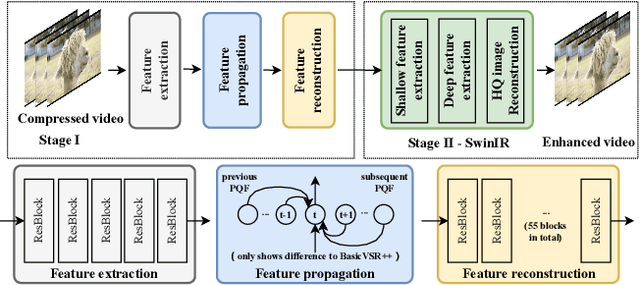
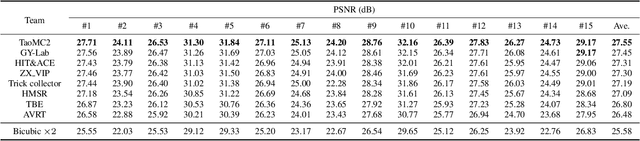

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.