 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueryable Prototype Multiple Instance Learning with Vision-Language Models for Incremental Whole Slide Image Classification
Oct 14, 2024

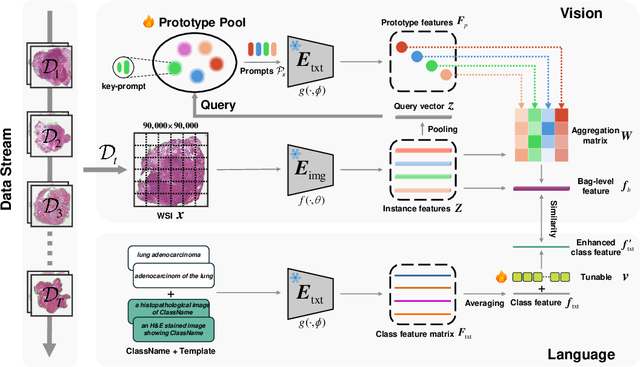

Whole Slide Image (WSI) classification has very significant applications in clinical pathology, e.g., tumor identification and cancer diagnosis. Currently, most research attention is focused on Multiple Instance Learning (MIL) using static datasets. One of the most obvious weaknesses of these methods is that they cannot efficiently preserve and utilize previously learned knowledge. With any new data arriving, classification models are required to be re-trained on both previous and current new data. To overcome this shortcoming and break through traditional vision modality, this paper proposes the first Vision-Language-based framework with Queryable Prototype Multiple Instance Learning (QPMIL-VL) specially designed for incremental WSI classification. This framework mainly consists of two information processing branches. One is for generating the bag-level feature by prototype-guided aggregating on the instance features. While the other is for enhancing the class feature through class ensemble, tunable vector and class similarity loss. The experiments on four TCGA datasets demonstrate that our QPMIL-VL framework is effective for incremental WSI classification and often significantly outperforms other compared methods, achieving state-of-the-art (SOTA) performance.
Interpretable Vision-Language Survival Analysis with Ordinal Inductive Bias for Computational Pathology
Sep 14, 2024



Histopathology Whole-Slide Images (WSIs) provide an important tool to assess cancer prognosis in computational pathology (CPATH). While existing survival analysis (SA) approaches have made exciting progress, they are generally limited to adopting highly-expressive architectures and only coarse-grained patient-level labels to learn prognostic visual representations from gigapixel WSIs. Such learning paradigm suffers from important performance bottlenecks, when facing present scarce training data and standard multi-instance learning (MIL) framework in CPATH. To break through it, this paper, for the first time, proposes a new Vision-Language-based SA (VLSA) paradigm. Concretely, (1) VLSA is driven by pathology VL foundation models. It no longer relies on high-capability networks and shows the advantage of data efficiency. (2) In vision-end, VLSA encodes prognostic language prior and then employs it as auxiliary signals to guide the aggregating of prognostic visual features at instance level, thereby compensating for the weak supervision in MIL. Moreover, given the characteristics of SA, we propose i) ordinal survival prompt learning to transform continuous survival labels into textual prompts; and ii) ordinal incidence function as prediction target to make SA compatible with VL-based prediction. VLSA's predictions can be interpreted intuitively by our Shapley values-based method. The extensive experiments on five datasets confirm the effectiveness of our scheme. Our VLSA could pave a new way for SA in CPATH by offering weakly-supervised MIL an effective means to learn valuable prognostic clues from gigapixel WSIs. Our source code is available at https://github.com/liupei101/VLSA.