 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexusSplats: Efficient 3D Gaussian Splatting in the Wild
Nov 26, 2024While 3D Gaussian Splatting (3DGS) has recently demonstrated remarkable rendering quality and efficiency in 3D scene reconstruction, it struggles with varying lighting conditions and incidental occlusions in real-world scenarios. To accommodate varying lighting conditions, existing 3DGS extensions apply color mapping to the massive Gaussian primitives with individually optimized appearance embeddings. To handle occlusions, they predict pixel-wise uncertainties via 2D image features for occlusion capture. Nevertheless, such massive color mapping and pixel-wise uncertainty prediction strategies suffer from not only additional computational costs but also coarse-grained lighting and occlusion handling. In this work, we propose a nexus kernel-driven approach, termed NexusSplats, for efficient and finer 3D scene reconstruction under complex lighting and occlusion conditions. In particular, NexusSplats leverages a novel light decoupling strategy where appearance embeddings are optimized based on nexus kernels instead of massive Gaussian primitives, thus accelerating reconstruction speeds while ensuring local color consistency for finer textures. Additionally, a Gaussian-wise uncertainty mechanism is developed, aligning 3D structures with 2D image features for fine-grained occlusion handling. Experimental results demonstrate that NexusSplats achieves state-of-the-art rendering quality while reducing reconstruction time by up to 70.4% compared to the current best in quality.
Phys4DGen: A Physics-Driven Framework for Controllable and Efficient 4D Content Generation from a Single Image
Nov 25, 2024
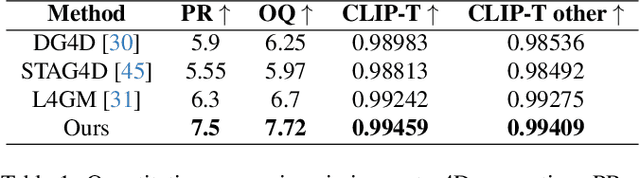
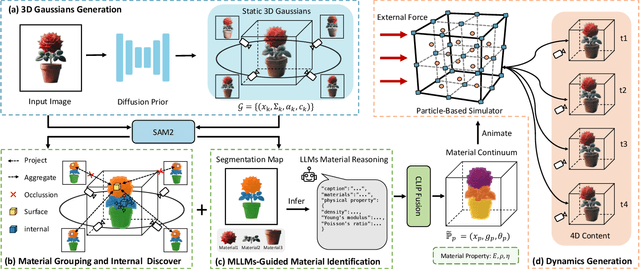
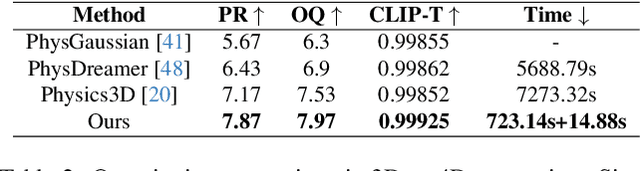
The task of 4D content generation involves creating dynamic 3D models that evolve over time in response to specific input conditions, such as images. Existing methods rely heavily on pre-trained video diffusion models to guide 4D content dynamics, but these approaches often fail to capture essential physical principles, as video diffusion models lack a robust understanding of real-world physics. Moreover, these models face challenges in providing fine-grained control over dynamics and exhibit high computational costs. In this work, we propose Phys4DGen, a novel, high-efficiency framework that generates physics-compliant 4D content from a single image with enhanced control capabilities. Our approach uniquely integrates physical simulations into the 4D generation pipeline, ensuring adherence to fundamental physical laws. Inspired by the human ability to infer physical properties visually, we introduce a Physical Perception Module (PPM) that discerns the material properties and structural components of the 3D object from the input image, facilitating accurate downstream simulations. Phys4DGen significantly accelerates the 4D generation process by eliminating iterative optimization steps in the dynamics modeling phase. It allows users to intuitively control the movement speed and direction of generated 4D content by adjusting external forces, achieving finely tunable, physically plausible animations. Extensive evaluations show that Phys4DGen outperforms existing methods in both inference speed and physical realism, producing high-quality, controllable 4D content.
Phy124: Fast Physics-Driven 4D Content Generation from a Single Image
Sep 11, 20244D content generation focuses on creating dynamic 3D objects that change over time. Existing methods primarily rely on pre-trained video diffusion models, utilizing sampling processes or reference videos. However, these approaches face significant challenges. Firstly, the generated 4D content often fails to adhere to real-world physics since video diffusion models do not incorporate physical priors. Secondly, the extensive sampling process and the large number of parameters in diffusion models result in exceedingly time-consuming generation processes. To address these issues, we introduce Phy124, a novel, fast, and physics-driven method for controllable 4D content generation from a single image. Phy124 integrates physical simulation directly into the 4D generation process, ensuring that the resulting 4D content adheres to natural physical laws. Phy124 also eliminates the use of diffusion models during the 4D dynamics generation phase, significantly speeding up the process. Phy124 allows for the control of 4D dynamics, including movement speed and direction, by manipulating external forces. Extensive experiments demonstrate that Phy124 generates high-fidelity 4D content with significantly reduced inference times, achieving stateof-the-art performance. The code and generated 4D content are available at the provided link: https://anonymous.4open.science/r/BBF2/.
Adversarial Learning for Neural PDE Solvers with Sparse Data
Sep 04, 2024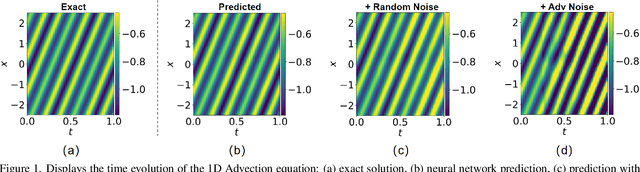
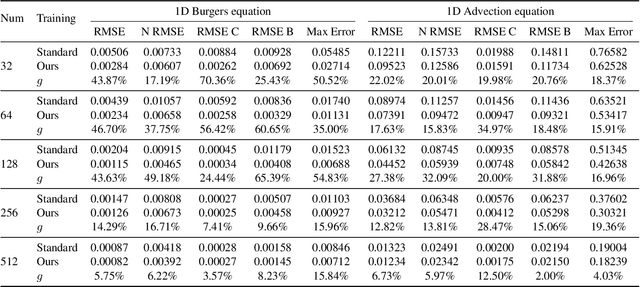
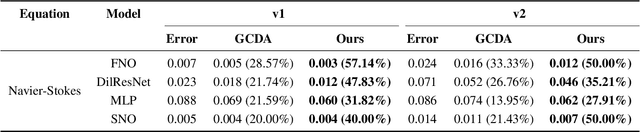
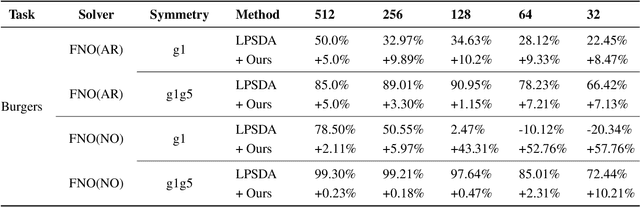
Neural network solvers for partial differential equations (PDEs) have made significant progress, yet they continue to face challenges related to data scarcity and model robustness. Traditional data augmentation methods, which leverage symmetry or invariance, impose strong assumptions on physical systems that often do not hold in dynamic and complex real-world applications. To address this research gap, this study introduces a universal learning strategy for neural network PDEs, named Systematic Model Augmentation for Robust Training (SMART). By focusing on challenging and improving the model's weaknesses, SMART reduces generalization error during training under data-scarce conditions, leading to significant improvements in prediction accuracy across various PDE scenarios. The effectiveness of the proposed method is demonstrated through both theoretical analysis and extensive experimentation. The code will be available.
Beyond Augmentation: Empowering Model Robustness under Extreme Capture Environments
Jul 18, 2024



Person Re-identification (re-ID) in computer vision aims to recognize and track individuals across different cameras. While previous research has mainly focused on challenges like pose variations and lighting changes, the impact of extreme capture conditions is often not adequately addressed. These extreme conditions, including varied lighting, camera styles, angles, and image distortions, can significantly affect data distribution and re-ID accuracy. Current research typically improves model generalization under normal shooting conditions through data augmentation techniques such as adjusting brightness and contrast. However, these methods pay less attention to the robustness of models under extreme shooting conditions. To tackle this, we propose a multi-mode synchronization learning (MMSL) strategy . This approach involves dividing images into grids, randomly selecting grid blocks, and applying data augmentation methods like contrast and brightness adjustments. This process introduces diverse transformations without altering the original image structure, helping the model adapt to extreme variations. This method improves the model's generalization under extreme conditions and enables learning diverse features, thus better addressing the challenges in re-ID. Extensive experiments on a simulated test set under extreme conditions have demonstrated the effectiveness of our method. This approach is crucial for enhancing model robustness and adaptability in real-world scenarios, supporting the future development of person re-identification technology.
Beyond Dropout: Robust Convolutional Neural Networks Based on Local Feature Masking
Jul 18, 2024In the contemporary of deep learning, where models often grapple with the challenge of simultaneously achieving robustness against adversarial attacks and strong generalization capabilities, this study introduces an innovative Local Feature Masking (LFM) strategy aimed at fortifying the performance of Convolutional Neural Networks (CNNs) on both fronts. During the training phase, we strategically incorporate random feature masking in the shallow layers of CNNs, effectively alleviating overfitting issues, thereby enhancing the model's generalization ability and bolstering its resilience to adversarial attacks. LFM compels the network to adapt by leveraging remaining features to compensate for the absence of certain semantic features, nurturing a more elastic feature learning mechanism. The efficacy of LFM is substantiated through a series of quantitative and qualitative assessments, collectively showcasing a consistent and significant improvement in CNN's generalization ability and resistance against adversarial attacks--a phenomenon not observed in current and prior methodologies. The seamless integration of LFM into established CNN frameworks underscores its potential to advance both generalization and adversarial robustness within the deep learning paradigm. Through comprehensive experiments, including robust person re-identification baseline generalization experiments and adversarial attack experiments, we demonstrate the substantial enhancements offered by LFM in addressing the aforementioned challenges. This contribution represents a noteworthy stride in advancing robust neural network architectures.