 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Energy-Efficient Federated Learning in Cell-Free Networks with Adaptive Quantization
Dec 30, 2024



Federated Learning (FL) enables clients to share learning parameters instead of local data, reducing communication overhead. Traditional wireless networks face latency challenges with FL. In contrast, Cell-Free Massive MIMO (CFmMIMO) can serve multiple clients on shared resources, boosting spectral efficiency and reducing latency for large-scale FL. However, clients' communication resource limitations can hinder the completion of the FL training. To address this challenge, we propose an energy-efficient, low-latency FL framework featuring optimized uplink power allocation for seamless client-server collaboration. Our framework employs an adaptive quantization scheme, dynamically adjusting bit allocation for local gradient updates to reduce communication costs. We formulate a joint optimization problem covering FL model updates, local iterations, and power allocation, solved using sequential quadratic programming (SQP) to balance energy and latency. Additionally, clients use the AdaDelta method for local FL model updates, enhancing local model convergence compared to standard SGD, and we provide a comprehensive analysis of FL convergence with AdaDelta local updates. Numerical results show that, within the same energy and latency budgets, our power allocation scheme outperforms the Dinkelbach and max-sum rate methods by increasing the test accuracy up to $7$\% and $19$\%, respectively. Moreover, for the three power allocation methods, our proposed quantization scheme outperforms AQUILA and LAQ by increasing test accuracy by up to $36$\% and $35$\%, respectively.
Adaptive Quantization Resolution and Power Control for Federated Learning over Cell-free Networks
Dec 14, 2024Federated learning (FL) is a distributed learning framework where users train a global model by exchanging local model updates with a server instead of raw datasets, preserving data privacy and reducing communication overhead. However, the latency grows with the number of users and the model size, impeding the successful FL over traditional wireless networks with orthogonal access. Cell-free massive multiple-input multipleoutput (CFmMIMO) is a promising solution to serve numerous users on the same time/frequency resource with similar rates. This architecture greatly reduces uplink latency through spatial multiplexing but does not take application characteristics into account. In this paper, we co-optimize the physical layer with the FL application to mitigate the straggler effect. We introduce a novel adaptive mixed-resolution quantization scheme of the local gradient vector updates, where only the most essential entries are given high resolution. Thereafter, we propose a dynamic uplink power control scheme to manage the varying user rates and mitigate the straggler effect. The numerical results demonstrate that the proposed method achieves test accuracy comparable to classic FL while reducing communication overhead by at least 93% on the CIFAR-10, CIFAR-100, and Fashion-MNIST datasets. We compare our methods against AQUILA, Top-q, and LAQ, using the max-sum rate and Dinkelbach power control schemes. Our approach reduces the communication overhead by 75% and achieves 10% higher test accuracy than these benchmarks within a constrained total latency budget.
Joint Energy and Latency Optimization in Federated Learning over Cell-Free Massive MIMO Networks
Apr 28, 2024Federated learning (FL) is a distributed learning paradigm wherein users exchange FL models with a server instead of raw datasets, thereby preserving data privacy and reducing communication overhead. However, the increased number of FL users may hinder completing large-scale FL over wireless networks due to high imposed latency. Cell-free massive multiple-input multiple-output~(CFmMIMO) is a promising architecture for implementing FL because it serves many users on the same time/frequency resources. While CFmMIMO enhances energy efficiency through spatial multiplexing and collaborative beamforming, it remains crucial to meticulously allocate uplink transmission powers to the FL users. In this paper, we propose an uplink power allocation scheme in FL over CFmMIMO by considering the effect of each user's power on the energy and latency of other users to jointly minimize the users' uplink energy and the latency of FL training. The proposed solution algorithm is based on the coordinate gradient descent method. Numerical results show that our proposed method outperforms the well-known max-sum rate by increasing up to~$27$\% and max-min energy efficiency of the Dinkelbach method by increasing up to~$21$\% in terms of test accuracy while having limited uplink energy and latency budget for FL over CFmMIMO.
A-LAQ: Adaptive Lazily Aggregated Quantized Gradient
Oct 31, 2022

Federated Learning (FL) plays a prominent role in solving machine learning problems with data distributed across clients. In FL, to reduce the communication overhead of data between clients and the server, each client communicates the local FL parameters instead of the local data. However, when a wireless network connects clients and the server, the communication resource limitations of the clients may prevent completing the training of the FL iterations. Therefore, communication-efficient variants of FL have been widely investigated. Lazily Aggregated Quantized Gradient (LAQ) is one of the promising communication-efficient approaches to lower resource usage in FL. However, LAQ assigns a fixed number of bits for all iterations, which may be communication-inefficient when the number of iterations is medium to high or convergence is approaching. This paper proposes Adaptive Lazily Aggregated Quantized Gradient (A-LAQ), which is a method that significantly extends LAQ by assigning an adaptive number of communication bits during the FL iterations. We train FL in an energy-constraint condition and investigate the convergence analysis for A-LAQ. The experimental results highlight that A-LAQ outperforms LAQ by up to a $50$% reduction in spent communication energy and an $11$% increase in test accuracy.
FedCau: A Proactive Stop Policy for Communication and Computation Efficient Federated Learning
Apr 16, 2022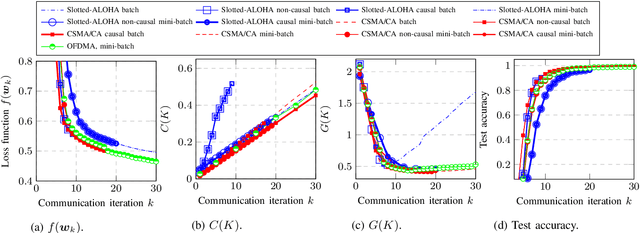
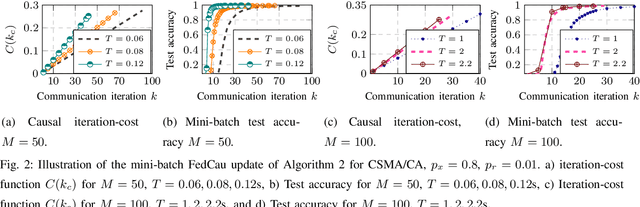
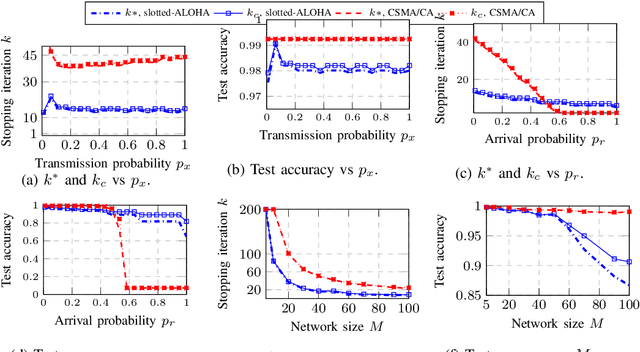
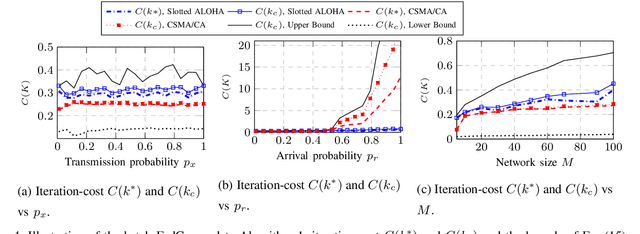
This paper investigates efficient distributed training of a Federated Learning~(FL) model over a wireless network of wireless devices. The communication iterations of the distributed training algorithm may be substantially deteriorated or even blocked by the effects of the devices' background traffic, packet losses, congestion, or latency. We abstract the communication-computation impacts as an `iteration cost' and propose a cost-aware causal FL algorithm~(FedCau) to tackle this problem. We propose an iteration-termination method that trade-offs the training performance and networking costs. We apply our approach when clients use the slotted-ALOHA, the carrier-sense multiple access with collision avoidance~(CSMA/CA), and the orthogonal frequency-division multiple access~(OFDMA) protocols. We show that, given a total cost budget, the training performance degrades as either the background communication traffic or the dimension of the training problem increases. Our results demonstrate the importance of proactively designing optimal cost-efficient stopping criteria to avoid unnecessary communication-computation costs to achieve only a marginal FL training improvement. We validate our method by training and testing FL over the MNIST dataset. Finally, we apply our approach to existing communication efficient FL methods from the literature, achieving further efficiency. We conclude that cost-efficient stopping criteria are essential for the success of practical FL over wireless networks.