 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Complexity ADMM-Based Multicast Beamforming in Cell-Free Massive MIMO Systems
Nov 10, 2025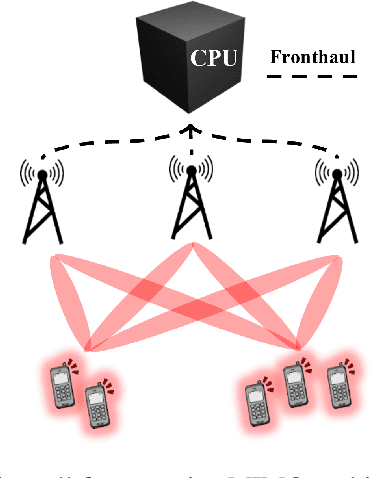



The growing demand for efficient delivery of common content to multiple user equipments (UEs) has motivated significant research in physical-layer multicasting. By exploiting the beamforming capabilities of massive MIMO, multicasting provides a spectrum-efficient solution that avoids unnecessary intra-group interference. A key challenge, however, is solving the max-min fair (MMF) and quality-of-service (QoS) multicast beamforming optimization problems, which are NP-hard due to the non-convex structure and the requirement for rank-1 solutions. Traditional approaches based on semidefinite relaxation (SDR) followed by randomization exhibit poor scalability with system size, while state-of-the-art successive convex approximation (SCA) methods only guarantee convergence to stationary points. In this paper, we propose an alternating direction method of multipliers (ADMM)-based framework for MMF and QoS multicast beamforming in cell-free massive MIMO networks. The algorithm leverages SDR but incorporates a novel iterative elimination strategy within the ADMM updates to efficiently obtain near-global optimal rank-1 beamforming solutions with reduced computational complexity compared to standard SDP solvers and randomization methods. Numerical evaluations demonstrate that the proposed ADMM-based procedure not only achieves superior spectral efficiency but also scales favorably with the number of antennas and UEs compared to state-of-the-art SCA-based algorithms, making it a practical tool for next-generation multicast systems.
Low-Complexity SDP-ADMM for Physical-Layer Multicasting in Massive MIMO Systems
Apr 08, 2025



There is a demand for the same data content from several user equipments (UEs) in many wireless communication applications. Physical-layer multicasting combines the beamforming capability of massive MIMO (multiple-input multiple-output) and the broadcast nature of the wireless channel to efficiently deliver the same data to a group of UEs using a single transmission. This paper tackles the max-min fair (MMF) multicast beamforming optimization, which is an NP-hard problem. We develop an efficient semidefinite program-alternating direction method of multipliers (SDP-ADMM) algorithm to find the near-global optimal rank-1 solution to the MMF multicast problem in a massive MIMO system. Numerical results show that the proposed SDP-ADMM algorithm exhibits similar spectral efficiency performance to state-of-the-art algorithms running on standard SDP solvers at a vastly reduced computational complexity. We highlight that the proposed ADMM elimination procedure can be employed as an effective low-complexity rank reduction method for other problems utilizing semidefinite relaxation.
Near-Optimal Cell-Free Beamforming for Physical Layer Multigroup Multicasting
Dec 18, 2024



Physical layer multicasting is an efficient transmission technique that exploits the beamforming potential at the transmitting nodes and the broadcast nature of the wireless channel, together with the demand for the same content from several UEs. This paper addresses the max-min fair multigroup multicast beamforming optimization, which is an NP-hard problem. We propose a novel iterative elimination procedure coupled with semidefinite relaxation (SDR) to find the near-global optimum rank-1 beamforming vectors in a cell-free massive MIMO (multiple-input multiple-output) network setup. The proposed optimization procedure shows significant improvements in computational complexity and spectral efficiency performance compared to the SDR followed by the commonly used randomization procedure and the state-of-the-art difference-of-convex approximation algorithm. The significance of the proposed procedure is that it can be utilized as a rank reduction method for any problem in conjunction with SDR.
Joint Energy and Latency Optimization in Federated Learning over Cell-Free Massive MIMO Networks
Apr 28, 2024Federated learning (FL) is a distributed learning paradigm wherein users exchange FL models with a server instead of raw datasets, thereby preserving data privacy and reducing communication overhead. However, the increased number of FL users may hinder completing large-scale FL over wireless networks due to high imposed latency. Cell-free massive multiple-input multiple-output~(CFmMIMO) is a promising architecture for implementing FL because it serves many users on the same time/frequency resources. While CFmMIMO enhances energy efficiency through spatial multiplexing and collaborative beamforming, it remains crucial to meticulously allocate uplink transmission powers to the FL users. In this paper, we propose an uplink power allocation scheme in FL over CFmMIMO by considering the effect of each user's power on the energy and latency of other users to jointly minimize the users' uplink energy and the latency of FL training. The proposed solution algorithm is based on the coordinate gradient descent method. Numerical results show that our proposed method outperforms the well-known max-sum rate by increasing up to~$27$\% and max-min energy efficiency of the Dinkelbach method by increasing up to~$21$\% in terms of test accuracy while having limited uplink energy and latency budget for FL over CFmMIMO.
Unknown Interference Modeling for Rate Adaptation in Cell-Free Massive MIMO Networks
Apr 18, 2024



Co-channel interference poses a challenge in any wireless communication network where the time-frequency resources are reused over different geographical areas. The interference is particularly diverse in cell-free massive multiple-input multiple-output (MIMO) networks, where a large number of user equipments (UEs) are multiplexed by a multitude of access points (APs) on the same time-frequency resources. For realistic and scalable network operation, only the interference from UEs belonging to the same serving cluster of APs can be estimated in real-time and suppressed by precoding/combining. As a result, the unknown interference arising from scheduling variations in neighboring clusters makes the rate adaptation hard and can lead to outages. This paper aims to model the unknown interference power in the uplink of a cell-free massive MIMO network. The results show that the proposed method effectively describes the distribution of the unknown interference power and provides a tool for rate adaptation with guaranteed target outage.
A Bayesian Approach to Characterize Unknown Interference Power in Wireless Networks
May 12, 2023The existence of unknown interference is a prevalent problem in wireless communication networks. Especially in multi-user multiple-input multiple-output (MIMO) networks, where a large number of user equipments are served on the same time-frequency resources, the outage performance may be dominated by the unknown interference arising from scheduling variations in neighboring cells. In this letter, we propose a Bayesian method for modeling the unknown interference power in the uplink of a cellular network. Numerical results show that our method accurately models the distribution of the unknown interference power and can be effectively used for rate adaptation with guaranteed target outage performance.
Soft Handover Procedures in mmWave Cell-Free Massive MIMO Networks
Sep 06, 2022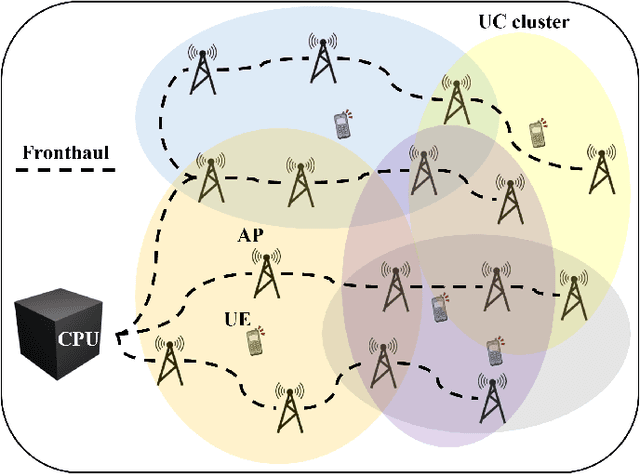
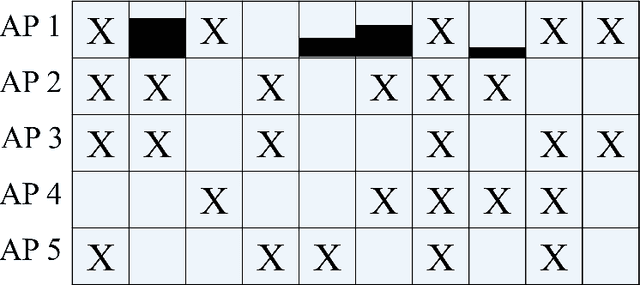
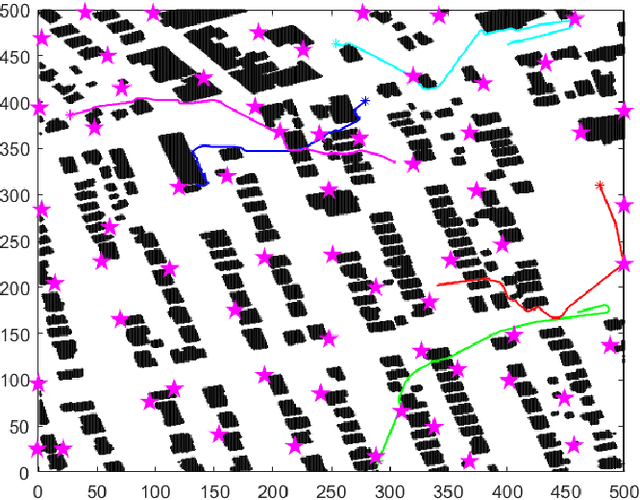
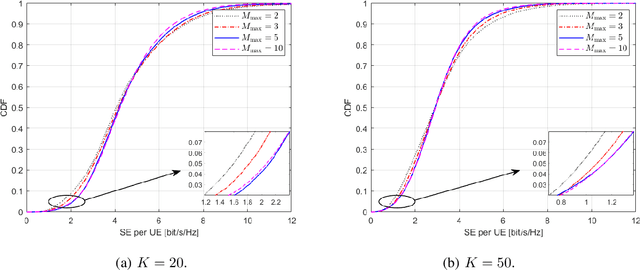
This paper considers a mmWave cell-free massive MIMO (multiple-input multiple-output) network composed of a large number of geographically distributed access points (APs) simultaneously serving multiple user equipments (UEs) via coherent joint transmission. We address UE mobility in the downlink (DL) with imperfect channel state information (CSI) and pilot training. Aiming at extending traditional handover concepts to the challenging AP-UE association strategies of cell-free networks, distributed algorithms for joint pilot assignment and cluster formation are proposed in a dynamic environment considering UE mobility. The algorithms provide a systematic procedure for initial access and update of the serving set of APs and assigned pilot sequence to each UE. The principal goal is to limit the necessary number of AP and pilot changes, while limiting computational complexity. The performance of the system is evaluated, with maximum ratio and regularized zero-forcing precoding, in terms of spectral efficiency (SE). The results show that our proposed distributed algorithms effectively identify the essential AP-UE association refinements. It also provides a significantly lower average number of pilot changes compared to an ultra-dense network (UDN). Moreover, we develop an improved pilot assignment procedure that facilitates massive access to the network in highly loaded scenarios.
Learning-Based Downlink Power Allocation in Cell-Free Massive MIMO Systems
Sep 07, 2021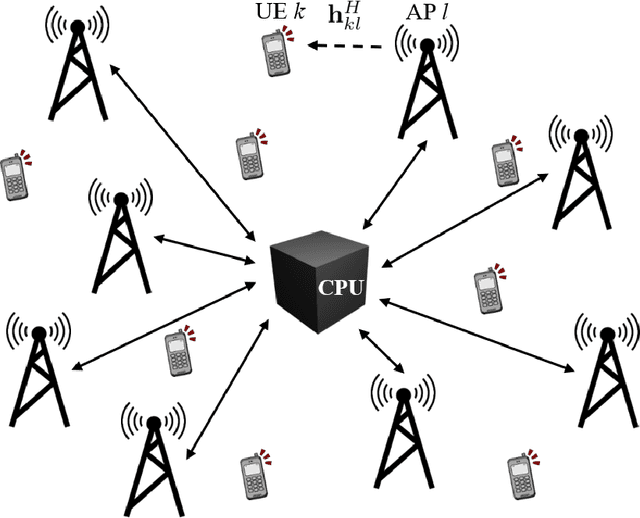
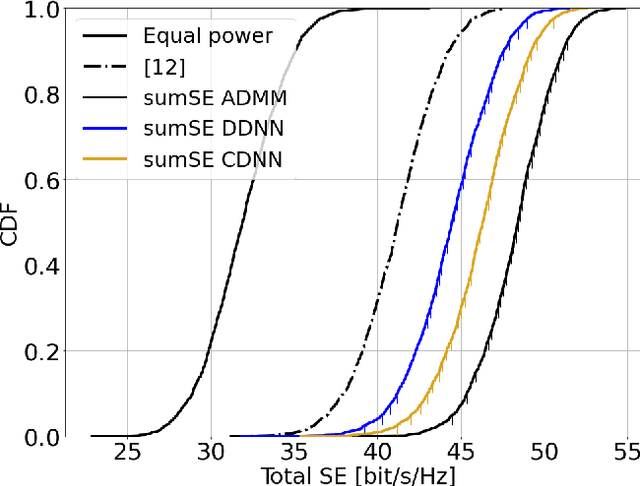
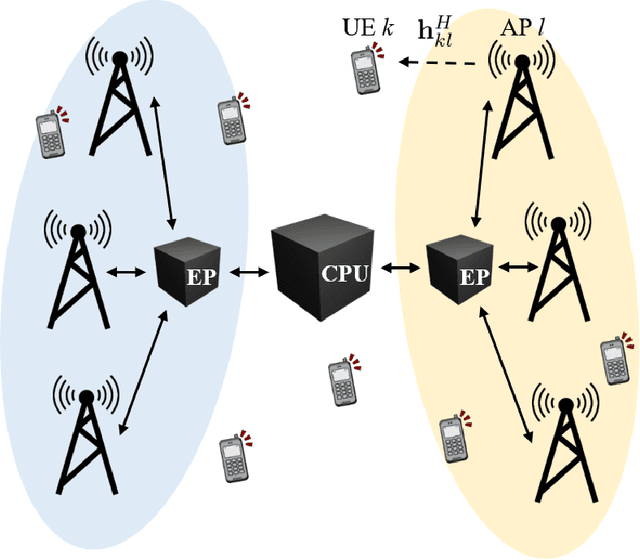
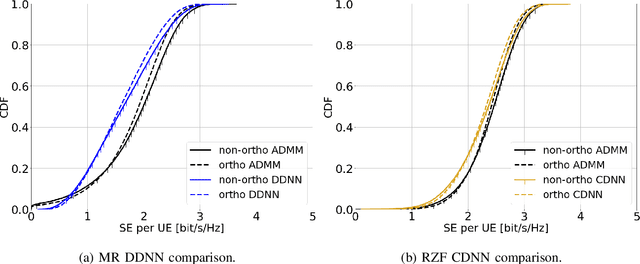
This paper considers a cell-free massive multiple-input multiple-output (MIMO) system that consists of a large number of geographically distributed access points (APs) serving multiple users via coherent joint transmission. The downlink performance of the system is evaluated, with maximum ratio and regularized zero-forcing precoding, under two optimization objectives for power allocation: sum spectral efficiency (SE) maximization and proportional fairness. We present iterative centralized algorithms for solving these problems. Aiming at a less computationally complex and also distributed scalable solution, we train a deep neural network (DNN) to approximate the same network-wide power allocation. Instead of training our DNN to mimic the actual optimization procedure, we use a heuristic power allocation, based on large-scale fading (LSF) parameters, as the pre-processed input to the DNN. We train the DNN to refine the heuristic scheme, thereby providing higher SE, using only local information at each AP. Another distributed DNN that exploits side information assumed to be available at the central processing unit is designed for improved performance. Further, we develop a clustered DNN model where the LSF parameters of a small number of APs, forming a cluster within a relatively large network, are used to jointly approximate the power coefficients of the cluster.