 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-LAQ: Adaptive Lazily Aggregated Quantized Gradient
Oct 31, 2022

Federated Learning (FL) plays a prominent role in solving machine learning problems with data distributed across clients. In FL, to reduce the communication overhead of data between clients and the server, each client communicates the local FL parameters instead of the local data. However, when a wireless network connects clients and the server, the communication resource limitations of the clients may prevent completing the training of the FL iterations. Therefore, communication-efficient variants of FL have been widely investigated. Lazily Aggregated Quantized Gradient (LAQ) is one of the promising communication-efficient approaches to lower resource usage in FL. However, LAQ assigns a fixed number of bits for all iterations, which may be communication-inefficient when the number of iterations is medium to high or convergence is approaching. This paper proposes Adaptive Lazily Aggregated Quantized Gradient (A-LAQ), which is a method that significantly extends LAQ by assigning an adaptive number of communication bits during the FL iterations. We train FL in an energy-constraint condition and investigate the convergence analysis for A-LAQ. The experimental results highlight that A-LAQ outperforms LAQ by up to a $50$% reduction in spent communication energy and an $11$% increase in test accuracy.
Interplay between Distributed AI Workflow and URLLC
Aug 02, 2022
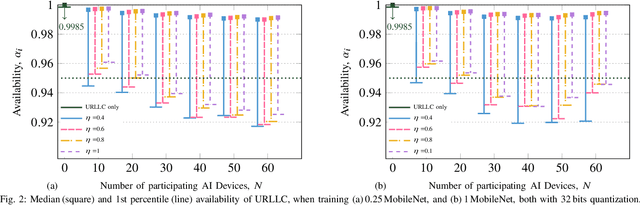
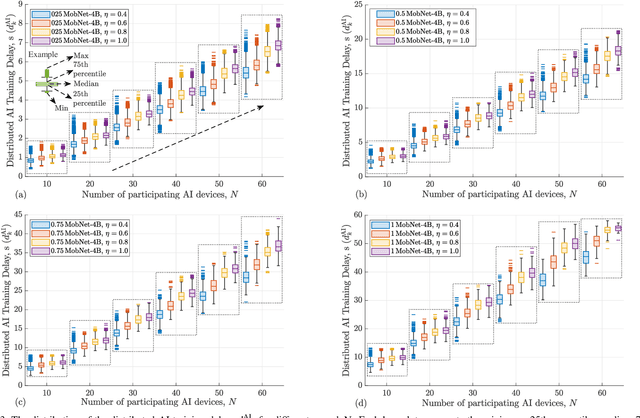

Distributed artificial intelligence (AI) has recently accomplished tremendous breakthroughs in various communication services, ranging from fault-tolerant factory automation to smart cities. When distributed learning is run over a set of wireless connected devices, random channel fluctuations, and the incumbent services simultaneously running on the same network affect the performance of distributed learning. In this paper, we investigate the interplay between distributed AI workflow and ultra-reliable low latency communication (URLLC) services running concurrently over a network. Using 3GPP compliant simulations in a factory automation use case, we show the impact of various distributed AI settings (e.g., model size and the number of participating devices) on the convergence time of distributed AI and the application layer performance of URLLC. Unless we leverage the existing 5G-NR quality of service handling mechanisms to separate the traffic from the two services, our simulation results show that the impact of distributed AI on the availability of the URLLC devices is significant. Moreover, with proper setting of distributed AI (e.g., proper user selection), we can substantially reduce network resource utilization, leading to lower latency for distributed AI and higher availability for the URLLC users. Our results provide important insights for future 6G and AI standardization.
Low Complexity Beam Searching Using Trajectory Information in Mobile Millimeter-wave Networks
Jun 06, 2022



Millimeter-wave and terahertz systems rely on beamforming/combining codebooks for finding the best beam directions during the initial access procedure. Existing approaches suffer from large codebook sizes and high beam searching overhead in the presence of mobile devices. To alleviate this problem, we suggest utilizing the similarity of the channel in adjacent locations to divide the UE trajectory into a set of separate regions and maintain a set of candidate paths for each region in a database. In this paper, we show the tradeoff between the number of regions and the signalling overhead, i.e., higher number of regions corresponds to higher signal-to-noise ratio (SNR) but also higher signalling overhead for the database. We then propose an optimization framework to find the minimum number of regions based on the trajectory of a mobile device. Using realistic ray tracing datasets, we demonstrate that the proposed method reduces the beam searching complexity and latency while providing high SNR.
FedCau: A Proactive Stop Policy for Communication and Computation Efficient Federated Learning
Apr 16, 2022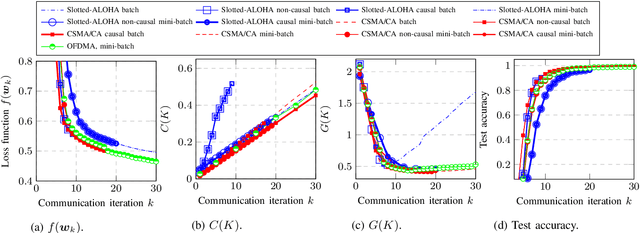
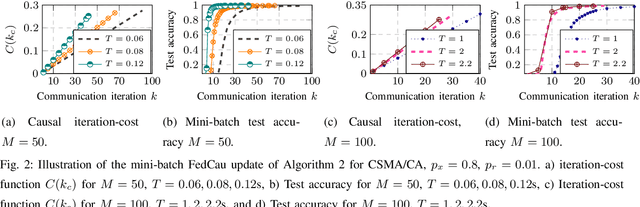
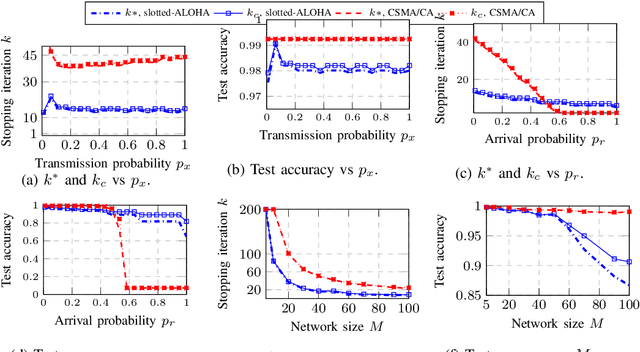
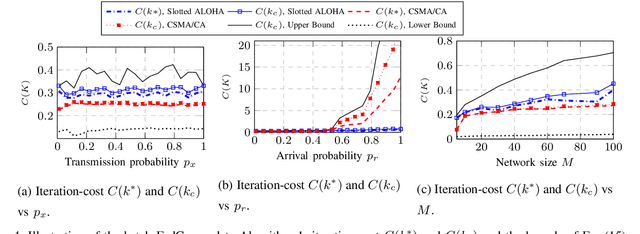
This paper investigates efficient distributed training of a Federated Learning~(FL) model over a wireless network of wireless devices. The communication iterations of the distributed training algorithm may be substantially deteriorated or even blocked by the effects of the devices' background traffic, packet losses, congestion, or latency. We abstract the communication-computation impacts as an `iteration cost' and propose a cost-aware causal FL algorithm~(FedCau) to tackle this problem. We propose an iteration-termination method that trade-offs the training performance and networking costs. We apply our approach when clients use the slotted-ALOHA, the carrier-sense multiple access with collision avoidance~(CSMA/CA), and the orthogonal frequency-division multiple access~(OFDMA) protocols. We show that, given a total cost budget, the training performance degrades as either the background communication traffic or the dimension of the training problem increases. Our results demonstrate the importance of proactively designing optimal cost-efficient stopping criteria to avoid unnecessary communication-computation costs to achieve only a marginal FL training improvement. We validate our method by training and testing FL over the MNIST dataset. Finally, we apply our approach to existing communication efficient FL methods from the literature, achieving further efficiency. We conclude that cost-efficient stopping criteria are essential for the success of practical FL over wireless networks.
A Hybrid Model-based and Data-driven Approach to Spectrum Sharing in mmWave Cellular Networks
Mar 19, 2020
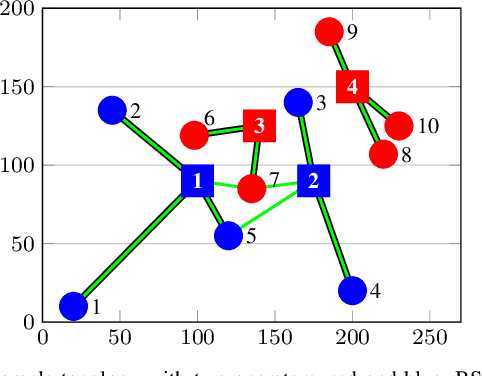
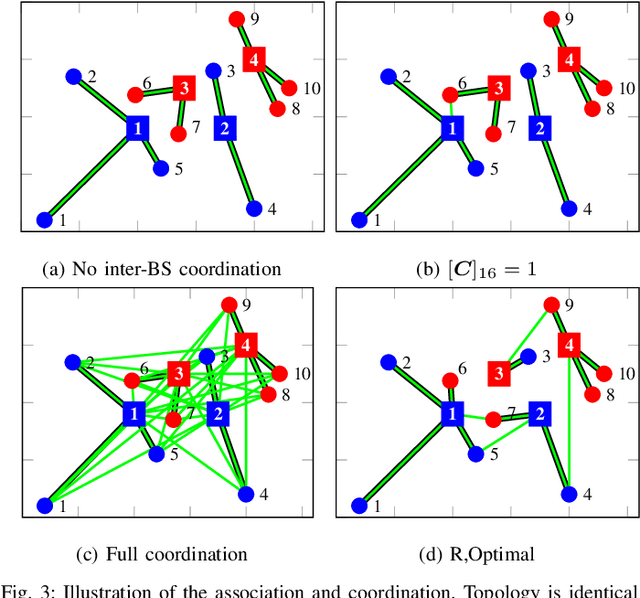
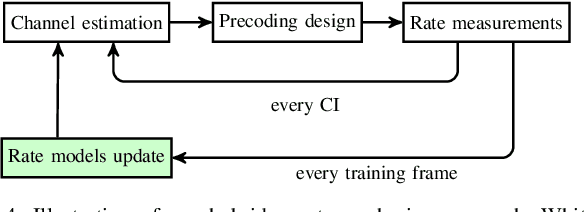
Inter-operator spectrum sharing in millimeter-wave bands has the potential of substantially increasing the spectrum utilization and providing a larger bandwidth to individual user equipment at the expense of increasing inter-operator interference. Unfortunately, traditional model-based spectrum sharing schemes make idealistic assumptions about inter-operator coordination mechanisms in terms of latency and protocol overhead, while being sensitive to missing channel state information. In this paper, we propose hybrid model-based and data-driven multi-operator spectrum sharing mechanisms, which incorporate model-based beamforming and user association complemented by data-driven model refinements. Our solution has the same computational complexity as a model-based approach but has the major advantage of having substantially less signaling overhead. We discuss how limited channel state information and quantized codebook-based beamforming affect the learning and the spectrum sharing performance. We show that the proposed hybrid sharing scheme significantly improves spectrum utilization under realistic assumptions on inter-operator coordination and channel state information acquisition.
Communication-efficient Variance-reduced Stochastic Gradient Descent
Mar 10, 2020
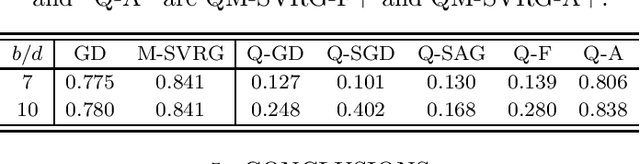
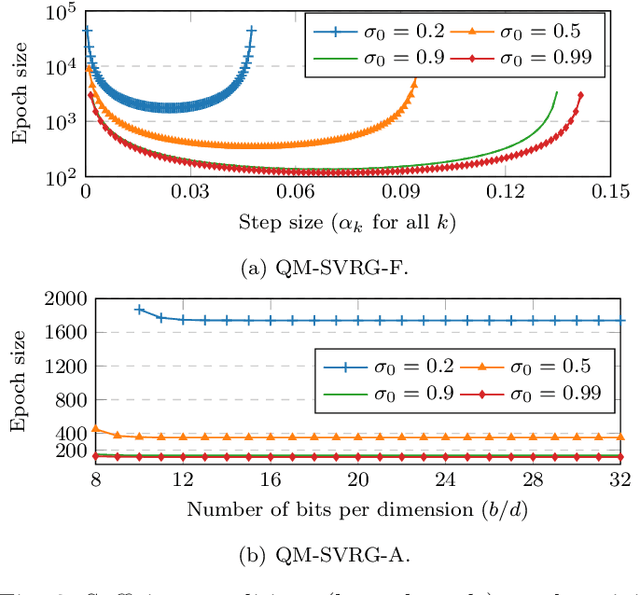
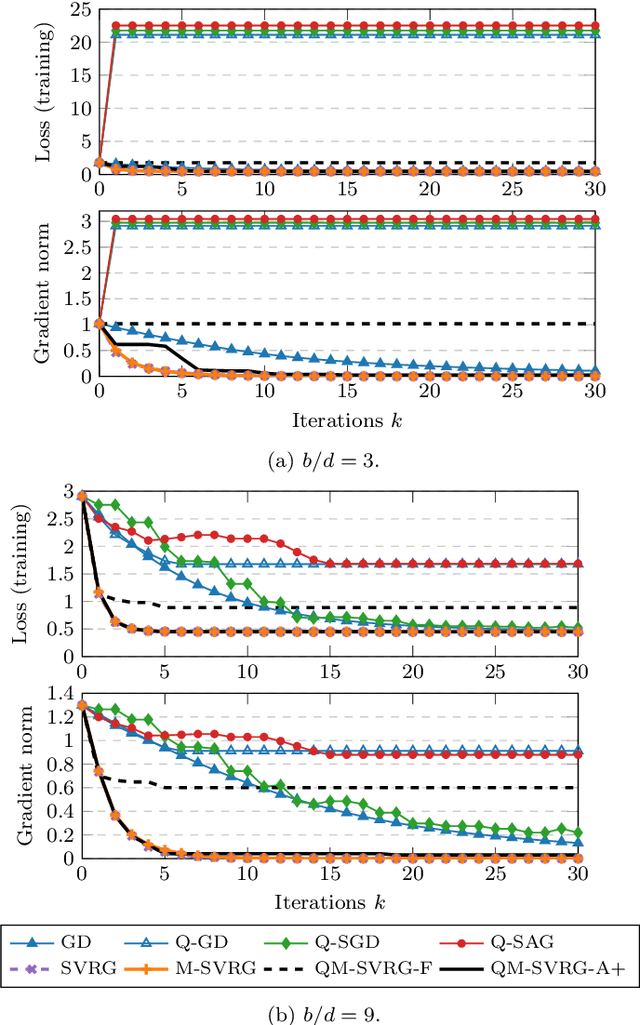
We consider the problem of communication efficient distributed optimization where multiple nodes exchange important algorithm information in every iteration to solve large problems. In particular, we focus on the stochastic variance-reduced gradient and propose a novel approach to make it communication-efficient. That is, we compress the communicated information to a few bits while preserving the linear convergence rate of the original uncompressed algorithm. Comprehensive theoretical and numerical analyses on real datasets reveal that our algorithm can significantly reduce the communication complexity, by as much as 95\%, with almost no noticeable penalty. Moreover, it is much more robust to quantization (in terms of maintaining the true minimizer and the convergence rate) than the state-of-the-art algorithms for solving distributed optimization problems. Our results have important implications for using machine learning over internet-of-things and mobile networks.