 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterplay between Distributed AI Workflow and URLLC
Aug 02, 2022
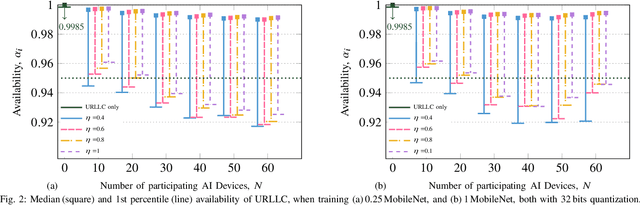
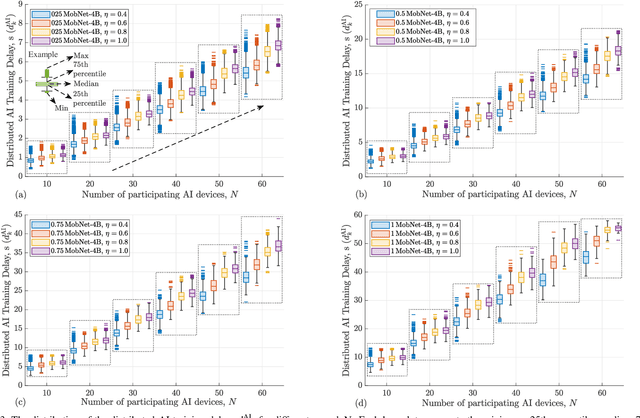

Distributed artificial intelligence (AI) has recently accomplished tremendous breakthroughs in various communication services, ranging from fault-tolerant factory automation to smart cities. When distributed learning is run over a set of wireless connected devices, random channel fluctuations, and the incumbent services simultaneously running on the same network affect the performance of distributed learning. In this paper, we investigate the interplay between distributed AI workflow and ultra-reliable low latency communication (URLLC) services running concurrently over a network. Using 3GPP compliant simulations in a factory automation use case, we show the impact of various distributed AI settings (e.g., model size and the number of participating devices) on the convergence time of distributed AI and the application layer performance of URLLC. Unless we leverage the existing 5G-NR quality of service handling mechanisms to separate the traffic from the two services, our simulation results show that the impact of distributed AI on the availability of the URLLC devices is significant. Moreover, with proper setting of distributed AI (e.g., proper user selection), we can substantially reduce network resource utilization, leading to lower latency for distributed AI and higher availability for the URLLC users. Our results provide important insights for future 6G and AI standardization.
Dynamic Clustering in Federated Learning
Dec 07, 2020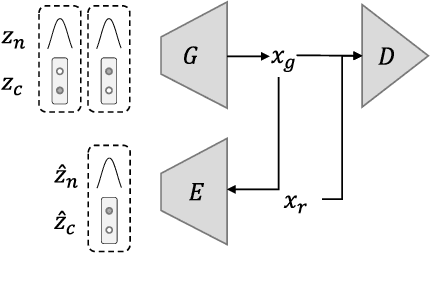
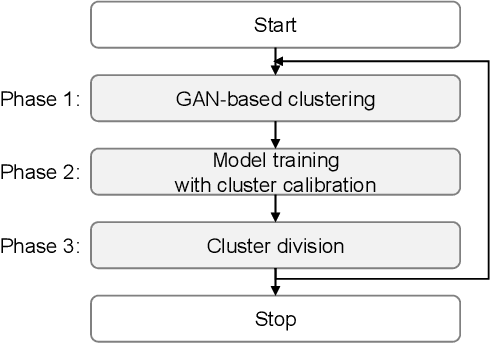
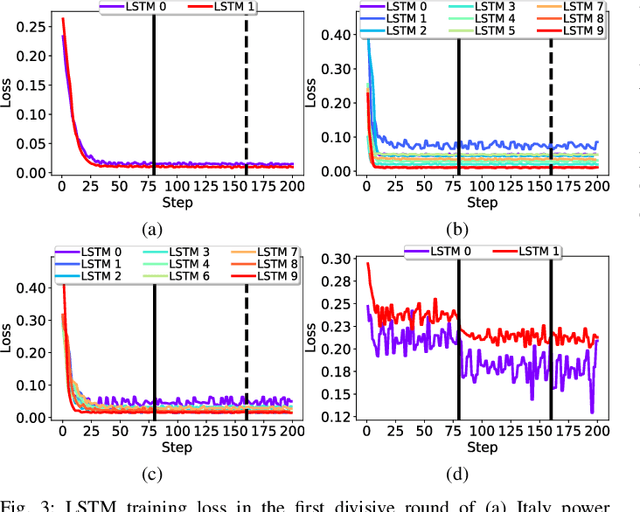
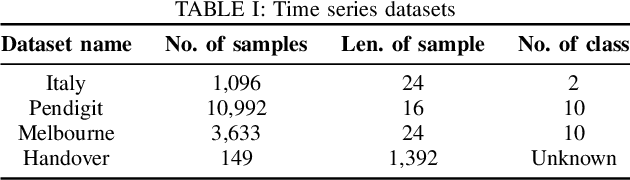
In the resource management of wireless networks, Federated Learning has been used to predict handovers. However, non-independent and identically distributed data degrade the accuracy performance of such predictions. To overcome the problem, Federated Learning can leverage data clustering algorithms and build a machine learning model for each cluster. However, traditional data clustering algorithms, when applied to the handover prediction, exhibit three main limitations: the risk of data privacy breach, the fixed shape of clusters, and the non-adaptive number of clusters. To overcome these limitations, in this paper, we propose a three-phased data clustering algorithm, namely: generative adversarial network-based clustering, cluster calibration, and cluster division. We show that the generative adversarial network-based clustering preserves privacy. The cluster calibration deals with dynamic environments by modifying clusters. Moreover, the divisive clustering explores the different number of clusters by repeatedly selecting and dividing a cluster into multiple clusters. A baseline algorithm and our algorithm are tested on a time series forecasting task. We show that our algorithm improves the performance of forecasting models, including cellular network handover, by 43%.