 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning for Spectrum Sharing: A Survey
Nov 28, 2024



The 5th generation (5G) of wireless systems is being deployed with the aim to provide many sets of wireless communication services, such as low data rates for a massive amount of devices, broadband, low latency, and industrial wireless access. Such an aim is even more complex in the next generation wireless systems (6G) where wireless connectivity is expected to serve any connected intelligent unit, such as software robots and humans interacting in the metaverse, autonomous vehicles, drones, trains, or smart sensors monitoring cities, buildings, and the environment. Because of the wireless devices will be orders of magnitude denser than in 5G cellular systems, and because of their complex quality of service requirements, the access to the wireless spectrum will have to be appropriately shared to avoid congestion, poor quality of service, or unsatisfactory communication delays. Spectrum sharing methods have been the objective of intense study through model-based approaches, such as optimization or game theories. However, these methods may fail when facing the complexity of the communication environments in 5G, 6G, and beyond. Recently, there has been significant interest in the application and development of data-driven methods, namely machine learning methods, to handle the complex operation of spectrum sharing. In this survey, we provide a complete overview of the state-of-theart of machine learning for spectrum sharing. First, we map the most prominent methods that we encounter in spectrum sharing. Then, we show how these machine learning methods are applied to the numerous dimensions and sub-problems of spectrum sharing, such as spectrum sensing, spectrum allocation, spectrum access, and spectrum handoff. We also highlight several open questions and future trends.
* Published at NOW Foundations and Trends in Networking
Federated Learning Using Three-Operator ADMM
Nov 10, 2022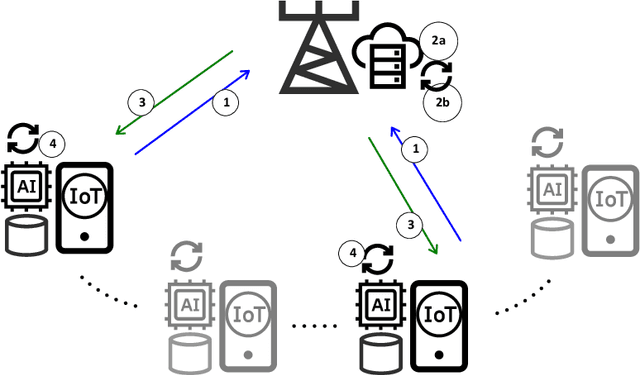
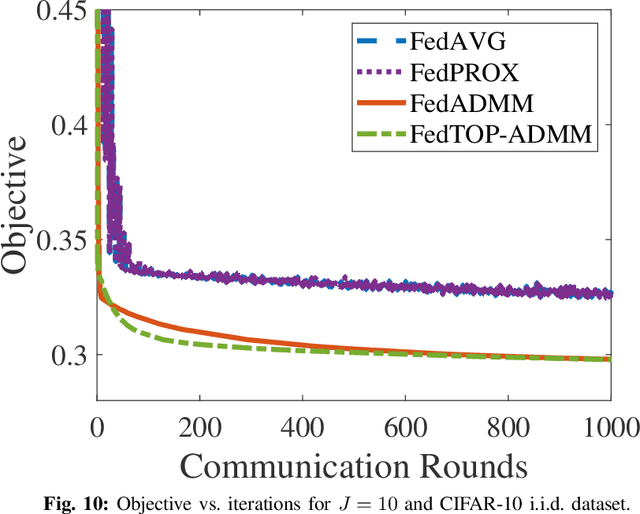
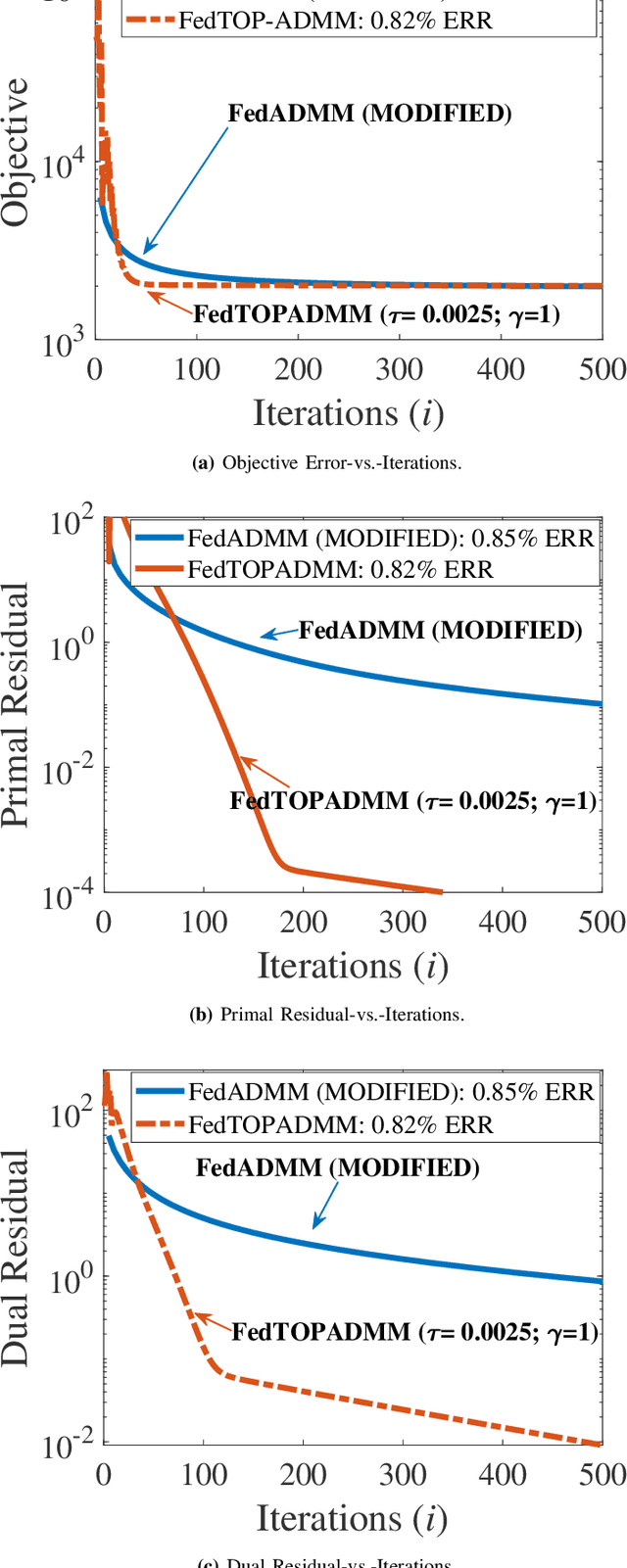

Federated learning (FL) has emerged as an instance of distributed machine learning paradigm that avoids the transmission of data generated on the users' side. Although data are not transmitted, edge devices have to deal with limited communication bandwidths, data heterogeneity, and straggler effects due to the limited computational resources of users' devices. A prominent approach to overcome such difficulties is FedADMM, which is based on the classical two-operator consensus alternating direction method of multipliers (ADMM). The common assumption of FL algorithms, including FedADMM, is that they learn a global model using data only on the users' side and not on the edge server. However, in edge learning, the server is expected to be near the base station and have direct access to rich datasets. In this paper, we argue that leveraging the rich data on the edge server is much more beneficial than utilizing only user datasets. Specifically, we show that the mere application of FL with an additional virtual user node representing the data on the edge server is inefficient. We propose FedTOP-ADMM, which generalizes FedADMM and is based on a three-operator ADMM-type technique that exploits a smooth cost function on the edge server to learn a global model parallel to the edge devices. Our numerical experiments indicate that FedTOP-ADMM has substantial gain up to 33\% in communication efficiency to reach a desired test accuracy with respect to FedADMM, including a virtual user on the edge server.
Simultaneous Wireless Information and Power Transfer for Federated Learning
Apr 26, 2021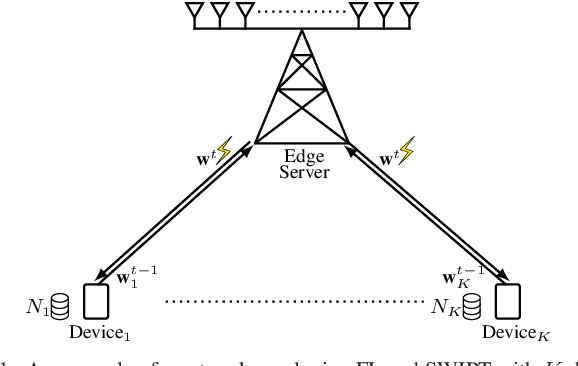
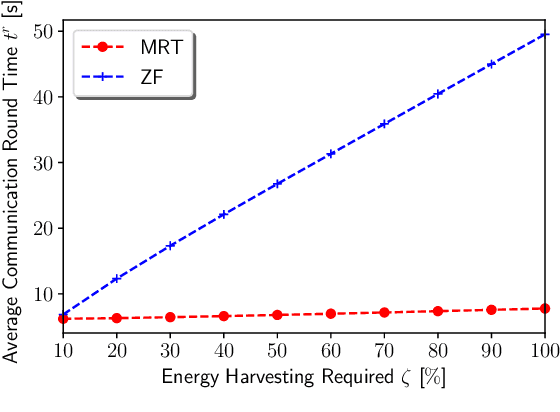
In the Internet of Things, learning is one of most prominent tasks. In this paper, we consider an Internet of Things scenario where federated learning is used with simultaneous transmission of model data and wireless power. We investigate the trade-off between the number of communication rounds and communication round time while harvesting energy to compensate the energy expenditure. We formulate and solve an optimization problem by considering the number of local iterations on devices, the time to transmit-receive the model updates, and to harvest sufficient energy. Numerical results indicate that maximum ratio transmission and zero-forcing beamforming for the optimization of the local iterations on devices substantially boost the test accuracy of the learning task. Moreover, maximum ratio transmission instead of zero-forcing provides the best test accuracy and communication round time trade-off for various energy harvesting percentages. Thus, it is possible to learn a model quickly with few communication rounds without depleting the battery.
Dynamic Clustering in Federated Learning
Dec 07, 2020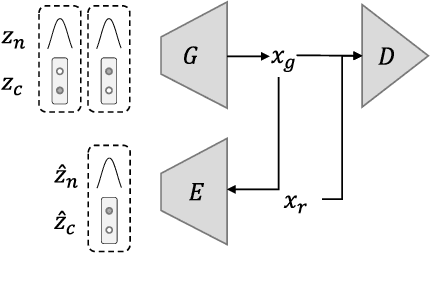
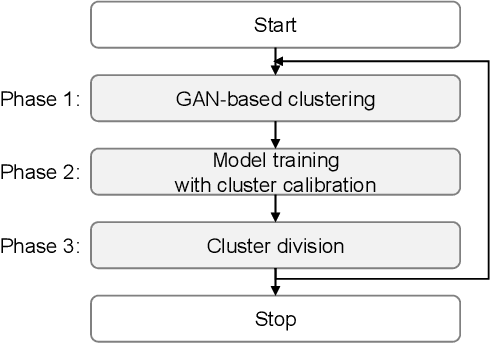
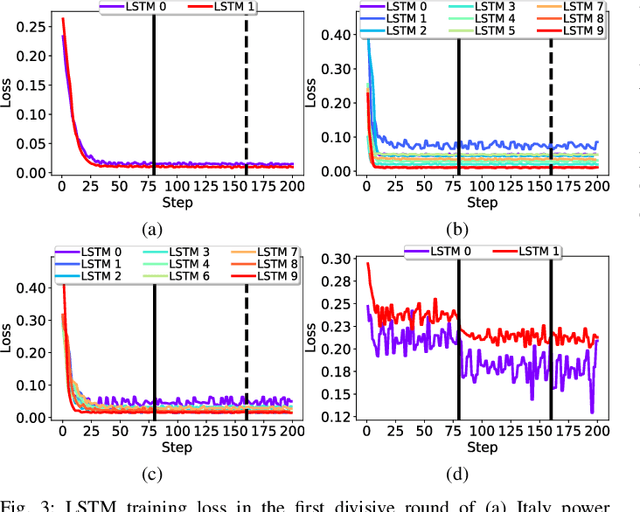
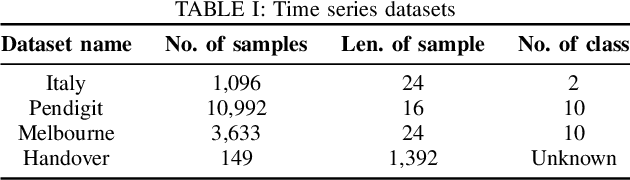
In the resource management of wireless networks, Federated Learning has been used to predict handovers. However, non-independent and identically distributed data degrade the accuracy performance of such predictions. To overcome the problem, Federated Learning can leverage data clustering algorithms and build a machine learning model for each cluster. However, traditional data clustering algorithms, when applied to the handover prediction, exhibit three main limitations: the risk of data privacy breach, the fixed shape of clusters, and the non-adaptive number of clusters. To overcome these limitations, in this paper, we propose a three-phased data clustering algorithm, namely: generative adversarial network-based clustering, cluster calibration, and cluster division. We show that the generative adversarial network-based clustering preserves privacy. The cluster calibration deals with dynamic environments by modifying clusters. Moreover, the divisive clustering explores the different number of clusters by repeatedly selecting and dividing a cluster into multiple clusters. A baseline algorithm and our algorithm are tested on a time series forecasting task. We show that our algorithm improves the performance of forecasting models, including cellular network handover, by 43%.