 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDSOR: Intensity- and Distance-Aware Statistical Outlier Removal for Weather-Robust LiDAR Point Clouds
Feb 05, 2026LiDAR point clouds captured in rain or snow are often corrupted by weather-induced returns, which can degrade perception and safety-critical scene understanding. This paper proposes Intensity- and Distance-Aware Statistical Outlier Removal (IDSOR), a range-adaptive filtering method that jointly exploits intensity cues and neighborhood sparsity. By incorporating an empirical, range-dependent distribution of weather returns into the threshold design, IDSOR suppresses weather-induced points while preserving fine structural details without cumbersome manual parameter tuning. We also propose a variant that uses a previously proposed method to estimate the weather return distribution from data, and integrates it into IDSOR. Experiments on simulation-augmented level-crossing measurements and on the Winter Adverse Driving dataset (WADS) demonstrate that IDSOR achieves a favorable precision-recall trade-off, maintaining both precision and recall above 90% on WADS.
Uncertainty-Weighted Multi-Task CNN for Joint DoA and Rain-Rate Estimation Under Rain-Induced Array Distortions
Feb 02, 2026We investigate joint direction-of-arrival (DoA) and rain-rate estimation for a uniform linear array operating under rain-induced multiplicative distortions. Building on a wavefront fluctuation model whose spatial correlation is governed by the rain-rate, we derive an angle-dependent covariance formulation and use it to synthesize training data. DoA estimation is cast as a multi-label classification problem on a discretized angular grid, while rain-rate estimation is formulated as a multi-class classification task. We then propose a multi-task deep CNN with a shared feature extractor and two task-specific heads, trained using an uncertainty-weighted objective to automatically balance the two losses. Numerical results in a two-source scenario show that the proposed network achieves lower DoA RMSE than classical baselines and provides accurate rain-rate classification at moderate-to-high SNRs.
Obstacle Detection at Level Crossings under Adverse Weather Conditions -- A Survey
Feb 02, 2026Level crossing accidents remain a significant safety concern in modern railway systems, particularly under adverse weather conditions that degrade sensor performance. This review surveys state-of-the-art sensor technologies and fusion strategies for obstacle detection at railway level crossings, with a focus on robustness, detection accuracy, and environmental resilience. Individual sensors such as inductive loops, cameras, radar, and LiDAR offer complementary strengths but involve trade-offs, including material dependence, reduced visibility, and limited resolution in harsh environments. We analyze each modality's working principles, weather-induced vulnerabilities, and mitigation strategies, including signal enhancement and machine-learning-based denoising. We further review multi-sensor fusion approaches, categorized as data-level, feature-level, and decision-level architectures, that integrate complementary information to improve reliability and fault tolerance. The survey concludes with future research directions, including adaptive fusion algorithms, real-time processing pipelines, and weather-resilient datasets to support the deployment of intelligent, fail-safe detection systems for railway safety.
Robust Covariance-Based DoA Estimation under Weather-Induced Distortion
Jan 27, 2026We investigate robust direction-of-arrival (DoA) estimation for sensor arrays operating in adverse weather conditions, where weather-induced distortions degrade estimation accuracy. Building on a physics-based $S$-matrix model established in prior work, we adopt a statistical characterization of random phase and amplitude distortions caused by multiple scattering in rain. Based on this model, we develop a measurement framework for uniform linear arrays (ULAs) that explicitly incorporates such distortions. To mitigate their impact, we exploit the Hermitian Toeplitz (HT) structure of the covariance matrix to reduce the number of parameters to be estimated. We then apply a generalized least squares (GLS) approach for calibration. Simulation results show that the proposed method effectively suppresses rain-induced distortions, improves DoA estimation accuracy, and enhances radar sensing performance in challenging weather conditions.
Machine Learning for Spectrum Sharing: A Survey
Nov 28, 2024



The 5th generation (5G) of wireless systems is being deployed with the aim to provide many sets of wireless communication services, such as low data rates for a massive amount of devices, broadband, low latency, and industrial wireless access. Such an aim is even more complex in the next generation wireless systems (6G) where wireless connectivity is expected to serve any connected intelligent unit, such as software robots and humans interacting in the metaverse, autonomous vehicles, drones, trains, or smart sensors monitoring cities, buildings, and the environment. Because of the wireless devices will be orders of magnitude denser than in 5G cellular systems, and because of their complex quality of service requirements, the access to the wireless spectrum will have to be appropriately shared to avoid congestion, poor quality of service, or unsatisfactory communication delays. Spectrum sharing methods have been the objective of intense study through model-based approaches, such as optimization or game theories. However, these methods may fail when facing the complexity of the communication environments in 5G, 6G, and beyond. Recently, there has been significant interest in the application and development of data-driven methods, namely machine learning methods, to handle the complex operation of spectrum sharing. In this survey, we provide a complete overview of the state-of-theart of machine learning for spectrum sharing. First, we map the most prominent methods that we encounter in spectrum sharing. Then, we show how these machine learning methods are applied to the numerous dimensions and sub-problems of spectrum sharing, such as spectrum sensing, spectrum allocation, spectrum access, and spectrum handoff. We also highlight several open questions and future trends.
* Published at NOW Foundations and Trends in Networking
Train Localization During GNSS Outages: A Minimalist Approach Using Track Geometry And IMU Sensor Data
Jun 04, 2024Train localization during Global Navigation Satellite Systems (GNSS) outages presents challenges for ensuring failsafe and accurate positioning in railway networks. This paper proposes a minimalist approach exploiting track geometry and Inertial Measurement Unit (IMU) sensor data. By integrating a discrete track map as a Look-Up Table (LUT) into a Particle Filter (PF) based solution, accurate train positioning is achieved with only an IMU sensor and track map data. The approach is tested on an open railway positioning data set, showing that accurate positioning (absolute errors below 10 m) can be maintained during GNSS outages up to 30 s in the given data. We simulate outages on different track segments and show that accurate positioning is reached during track curves and curvy railway lines. The approach can be used as a redundant complement to established positioning solutions to increase the position estimate's reliability and robustness.
Federated Learning Using Three-Operator ADMM
Nov 10, 2022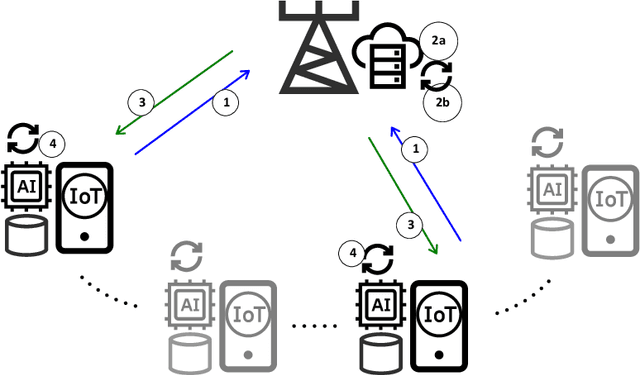
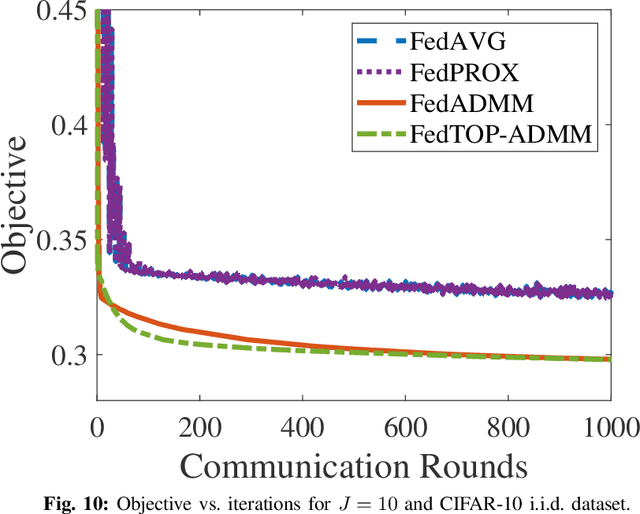
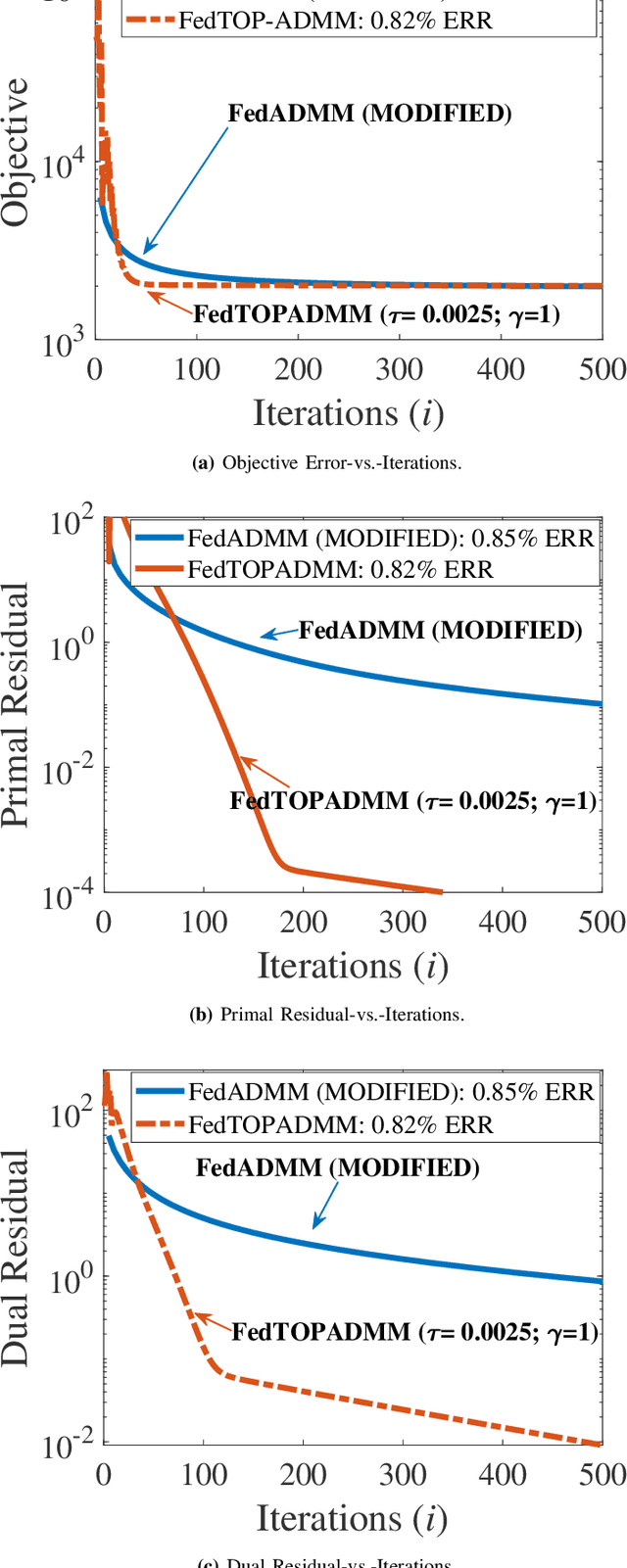

Federated learning (FL) has emerged as an instance of distributed machine learning paradigm that avoids the transmission of data generated on the users' side. Although data are not transmitted, edge devices have to deal with limited communication bandwidths, data heterogeneity, and straggler effects due to the limited computational resources of users' devices. A prominent approach to overcome such difficulties is FedADMM, which is based on the classical two-operator consensus alternating direction method of multipliers (ADMM). The common assumption of FL algorithms, including FedADMM, is that they learn a global model using data only on the users' side and not on the edge server. However, in edge learning, the server is expected to be near the base station and have direct access to rich datasets. In this paper, we argue that leveraging the rich data on the edge server is much more beneficial than utilizing only user datasets. Specifically, we show that the mere application of FL with an additional virtual user node representing the data on the edge server is inefficient. We propose FedTOP-ADMM, which generalizes FedADMM and is based on a three-operator ADMM-type technique that exploits a smooth cost function on the edge server to learn a global model parallel to the edge devices. Our numerical experiments indicate that FedTOP-ADMM has substantial gain up to 33\% in communication efficiency to reach a desired test accuracy with respect to FedADMM, including a virtual user on the edge server.
EVM Mitigation with PAPR and ACLR Constraints in Large-Scale MIMO-OFDM Using TOP-ADMM
May 25, 2022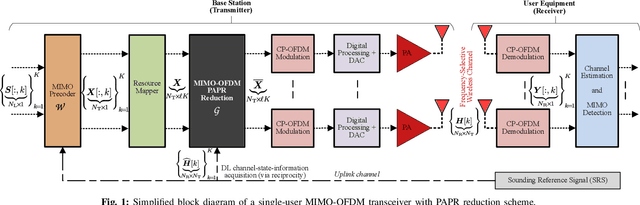
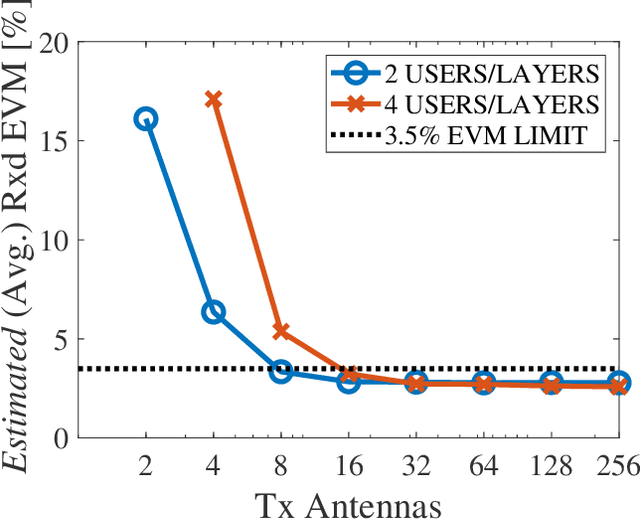
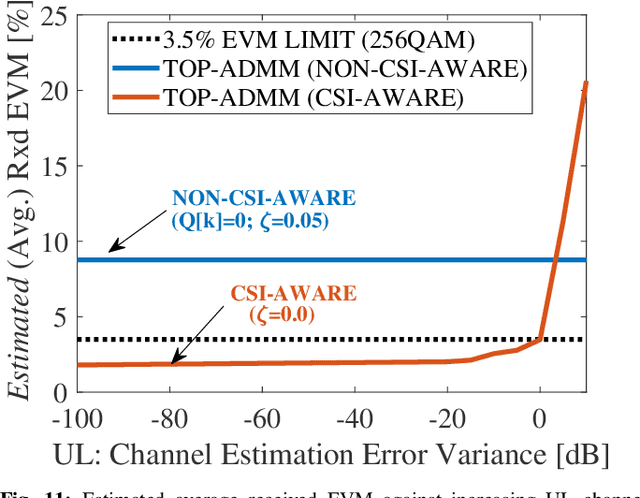
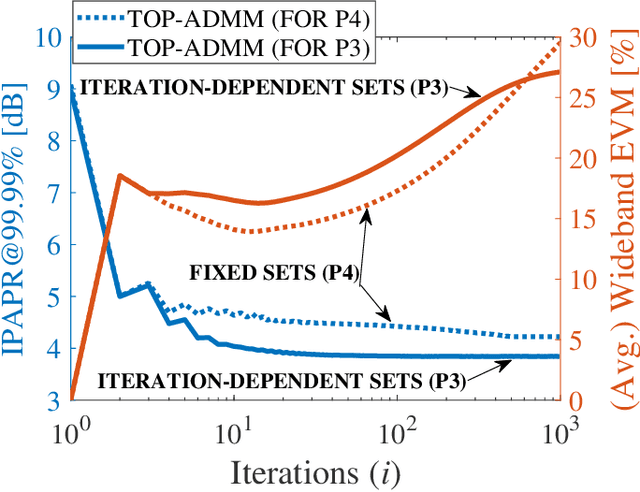
Although signal distortion-based peak-to-average power ratio (PAPR) reduction is a feasible candidate for orthogonal frequency division multiplexing (OFDM) to meet standard/regulatory requirements, the error vector magnitude (EVM) stemming from the PAPR reduction has a deleterious impact on the performance of high data-rate achieving multiple-input multiple-output (MIMO) systems. Moreover, these systems must constrain the adjacent channel leakage ratio (ACLR) to comply with regulatory requirements. Several recent works have investigated the mitigation of the EVM seen at the receivers by capitalizing on the excess spatial dimensions inherent in the large-scale MIMO that assume the availability of perfect channel state information (CSI) with spatially uncorrelated wireless channels. Unfortunately, practical systems operate with erroneous CSI and spatially correlated channels. Additionally, most standards support user-specific/CSI-aware beamformed and cell-specific/non-CSI-aware broadcasting channels. Hence, we formulate a robust EVM mitigation problem under channel uncertainty with nonconvex PAPR and ACLR constraints catering to beamforming/broadcasting. To solve this formidable problem, we develop an efficient scheme using our recently proposed three-operator alternating direction method of multipliers (TOP-ADMM) algorithm and benchmark it against two three-operator algorithms previously presented for machine learning purposes. Numerical results show the efficacy of the proposed algorithm under imperfect CSI and spatially correlated channels.
A Learning-Based Approach to Address Complexity-Reliability Tradeoff in OS Decoders
Mar 05, 2021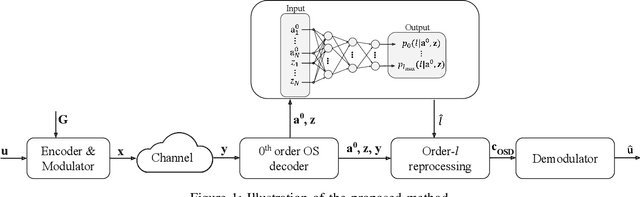
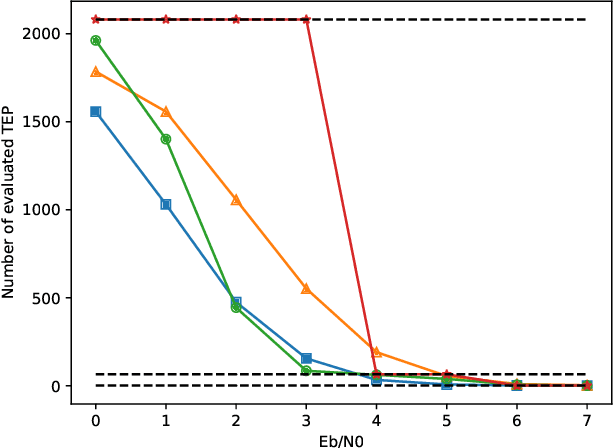
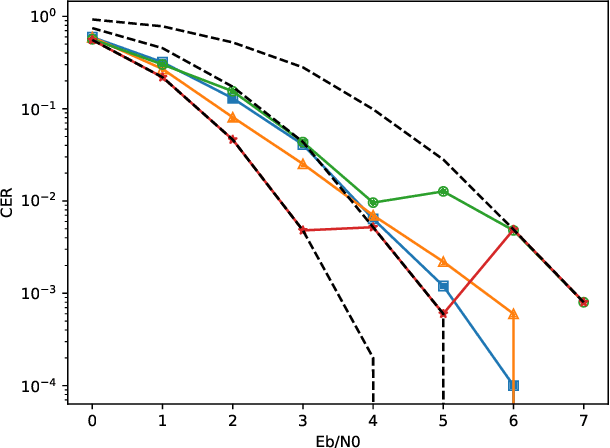
In this paper, we study the tradeoffs between complexity and reliability for decoding large linear block codes. We show that using artificial neural networks to predict the required order of an ordered statistics based decoder helps in reducing the average complexity and hence the latency of the decoder. We numerically validate the approach through Monte Carlo simulations.
Deep unfolding of the weighted MMSE beamforming algorithm
Jun 15, 2020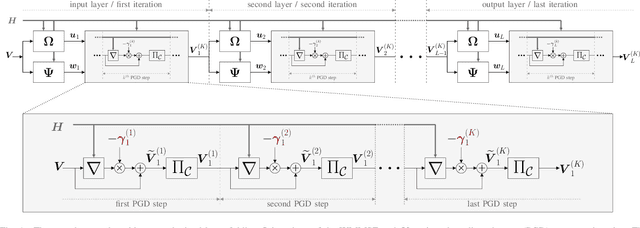
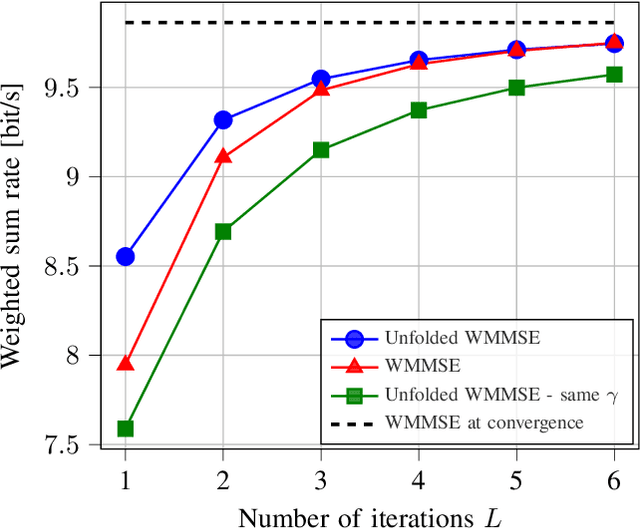
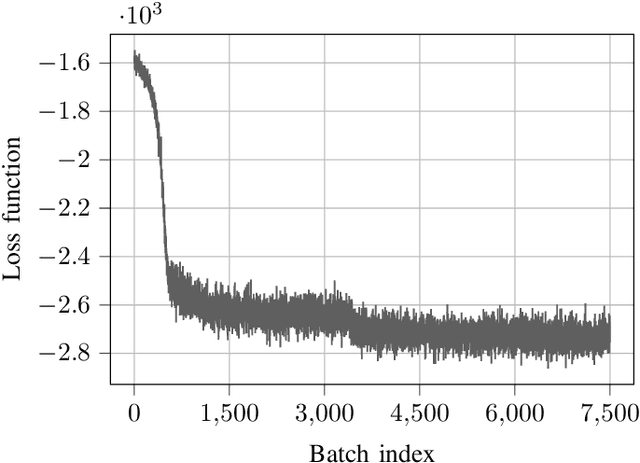
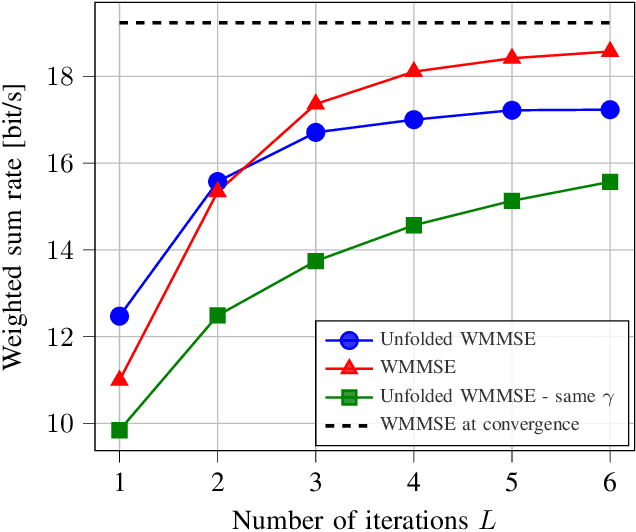
Downlink beamforming is a key technology for cellular networks. However, computing the transmit beamformer that maximizes the weighted sum rate subject to a power constraint is an NP-hard problem. As a result, iterative algorithms that converge to a local optimum are used in practice. Among them, the weighted minimum mean square error (WMMSE) algorithm has gained popularity, but its computational complexity and consequent latency has motivated the need for lower-complexity approximations at the expense of performance. Motivated by the recent success of deep unfolding in the trade-off between complexity and performance, we propose the novel application of deep unfolding to the WMMSE algorithm for a MISO downlink channel. The main idea consists of mapping a fixed number of iterations of the WMMSE algorithm into trainable neural network layers, whose architecture reflects the structure of the original algorithm. With respect to traditional end-to-end learning, deep unfolding naturally incorporates expert knowledge, with the benefits of immediate and well-grounded architecture selection, fewer trainable parameters, and better explainability. However, the formulation of the WMMSE algorithm, as described in Shi et al., is not amenable to be unfolded due to a matrix inversion, an eigendecomposition, and a bisection search performed at each iteration. Therefore, we present an alternative formulation that circumvents these operations by resorting to projected gradient descent. By means of simulations, we show that, in most of the settings, the unfolded WMMSE outperforms or performs equally to the WMMSE for a fixed number of iterations, with the advantage of a lower computational load.