 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning Using Three-Operator ADMM
Paper and Code
Nov 10, 2022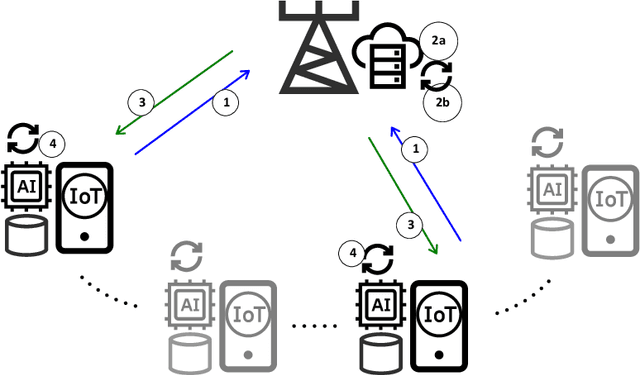
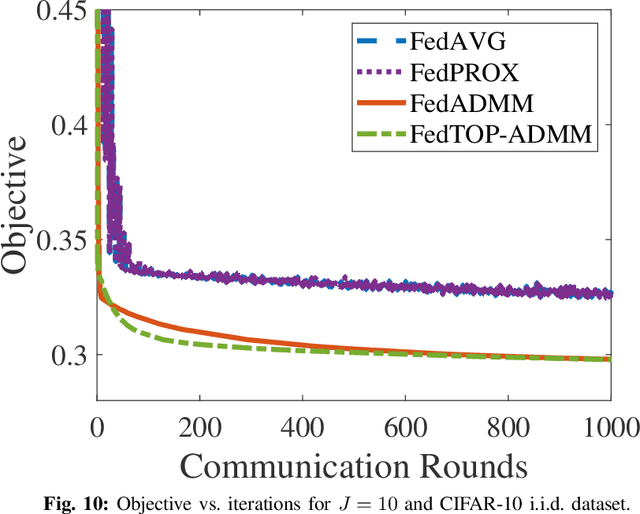
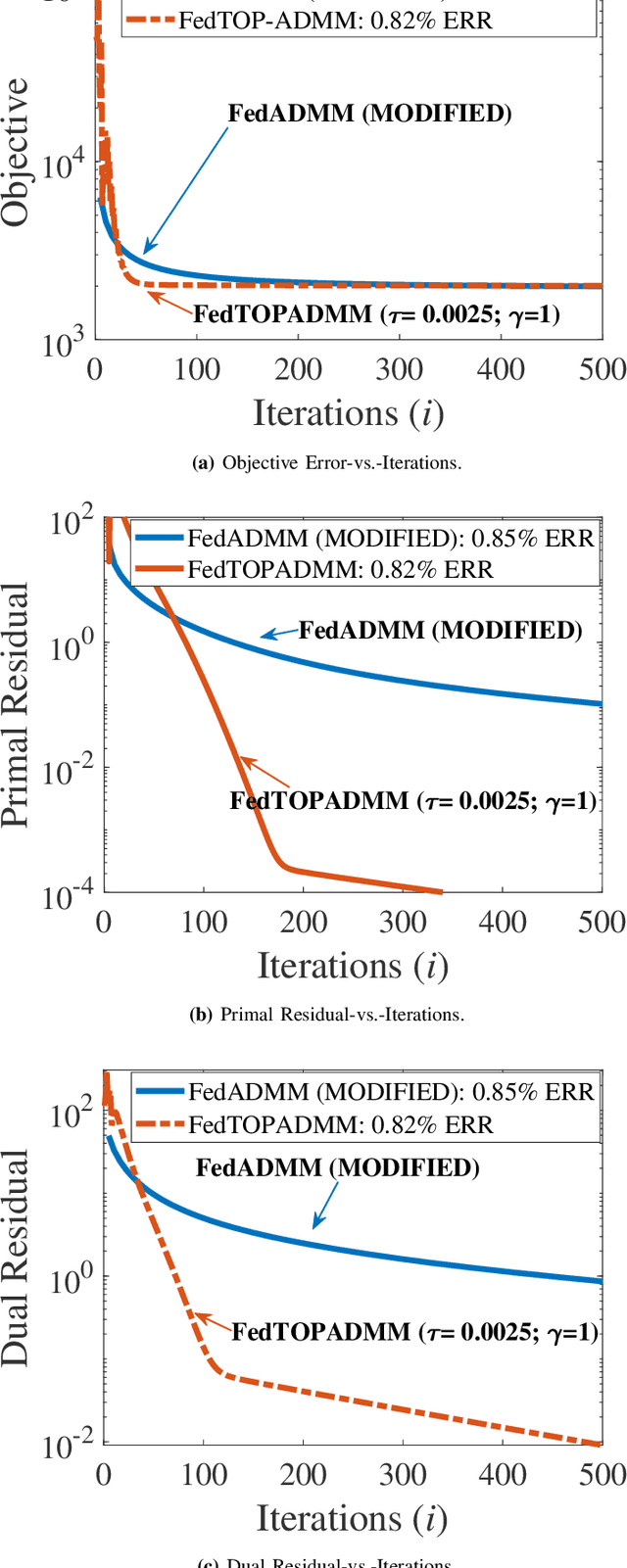

Federated learning (FL) has emerged as an instance of distributed machine learning paradigm that avoids the transmission of data generated on the users' side. Although data are not transmitted, edge devices have to deal with limited communication bandwidths, data heterogeneity, and straggler effects due to the limited computational resources of users' devices. A prominent approach to overcome such difficulties is FedADMM, which is based on the classical two-operator consensus alternating direction method of multipliers (ADMM). The common assumption of FL algorithms, including FedADMM, is that they learn a global model using data only on the users' side and not on the edge server. However, in edge learning, the server is expected to be near the base station and have direct access to rich datasets. In this paper, we argue that leveraging the rich data on the edge server is much more beneficial than utilizing only user datasets. Specifically, we show that the mere application of FL with an additional virtual user node representing the data on the edge server is inefficient. We propose FedTOP-ADMM, which generalizes FedADMM and is based on a three-operator ADMM-type technique that exploits a smooth cost function on the edge server to learn a global model parallel to the edge devices. Our numerical experiments indicate that FedTOP-ADMM has substantial gain up to 33\% in communication efficiency to reach a desired test accuracy with respect to FedADMM, including a virtual user on the edge server.