 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous generation of different courses of action in mechanized combat operations
Nov 07, 2025In this paper, we propose a methodology designed to support decision-making during the execution phase of military ground combat operations, with a focus on one's actions. This methodology generates and evaluates recommendations for various courses of action for a mechanized battalion, commencing with an initial set assessed by their anticipated outcomes. It systematically produces thousands of individual action alternatives, followed by evaluations aimed at identifying alternative courses of action with superior outcomes. These alternatives are appraised in light of the opponent's status and actions, considering unit composition, force ratios, types of offense and defense, and anticipated advance rates. Field manuals evaluate battle outcomes and advancement rates. The processes of generation and evaluation work concurrently, yielding a variety of alternative courses of action. This approach facilitates the management of new course generation based on previously evaluated actions. As the combat unfolds and conditions evolve, revised courses of action are formulated for the decision-maker within a sequential decision-making framework.
Comparing Multi-Target Trackers on Different Force Unit Levels
Nov 19, 2004Consider the problem of tracking a set of moving targets. Apart from the tracking result, it is often important to know where the tracking fails, either to steer sensors to that part of the state-space, or to inform a human operator about the status and quality of the obtained information. An intuitive quality measure is the correlation between two tracking results based on uncorrelated observations. In the case of Bayesian trackers such a correlation measure could be the Kullback-Leibler difference. We focus on a scenario with a large number of military units moving in some terrain. The units are observed by several types of sensors and "meta-sensors" with force aggregation capabilities. The sensors register units of different size. Two separate multi-target probability hypothesis density (PHD) particle filters are used to track some type of units (e.g., companies) and their sub-units (e.g., platoons), respectively, based on observations of units of those sizes. Each observation is used in one filter only. Although the state-space may well be the same in both filters, the posterior PHD distributions are not directly comparable -- one unit might correspond to three or four spatially distributed sub-units. Therefore, we introduce a mapping function between distributions for different unit size, based on doctrine knowledge of unit configuration. The mapped distributions can now be compared -- locally or globally -- using some measure, which gives the correlation between two PHD distributions in a bounded volume of the state-space. To locate areas where the tracking fails, a discretized quality map of the state-space can be generated by applying the measure locally to different parts of the space.
* 9 pages
Evidential Force Aggregation
Sep 15, 2003


In this paper we develop an evidential force aggregation method intended for classification of evidential intelligence into recognized force structures. We assume that the intelligence has already been partitioned into clusters and use the classification method individually in each cluster. The classification is based on a measure of fitness between template and fused intelligence that makes it possible to handle intelligence reports with multiple nonspecific and uncertain propositions. With this measure we can aggregate on a level-by-level basis, starting from general intelligence to achieve a complete force structure with recognized units on all hierarchical levels.
* 7 pages, 2 figures
Beslutstödssystemet Dezzy - en översikt
May 16, 2003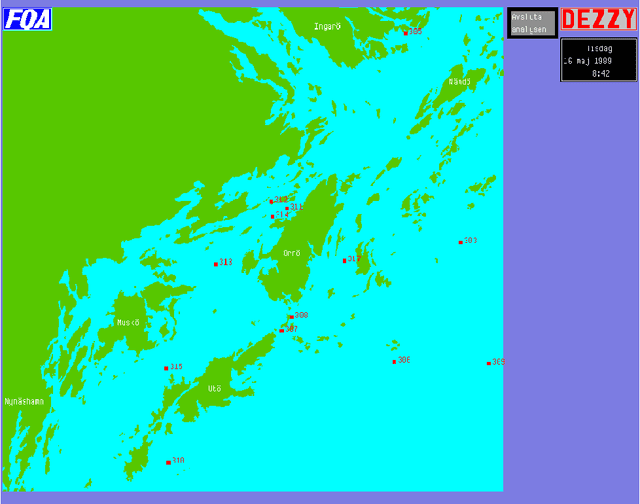

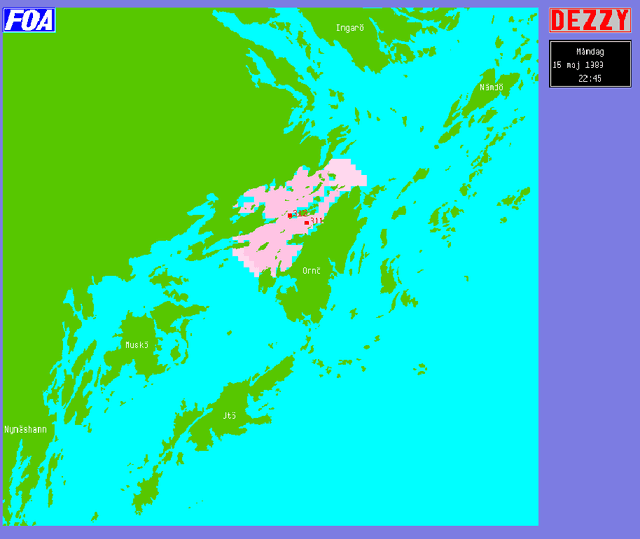
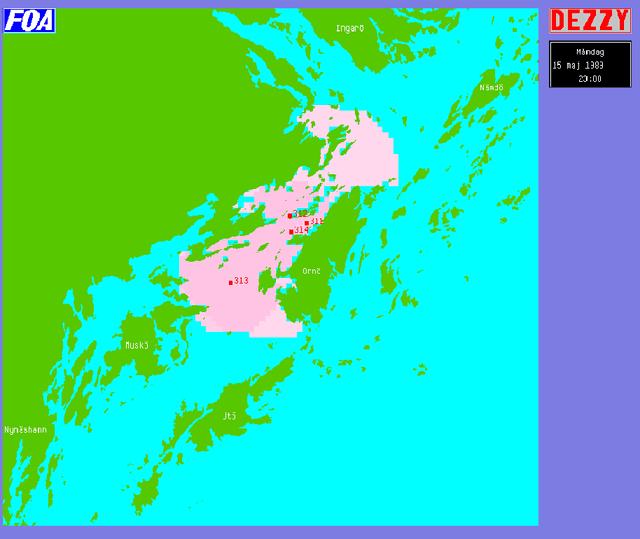
Within the scope of the three-year ANTI-SUBMARINE WARFARE project of the National Defence Research Establishment, the INFORMATION SYSTEMS subproject has developed the demonstration prototype Dezzy for handling and analysis of intelligence reports concerning foreign underwater activities. ----- Inom ramen f\"or FOA:s tre{\aa}riga huvudprojekt UB{\AA}TSSKYDD har delprojekt INFORMATIONSSYSTEM utvecklat demonstrationsprototypen Dezzy till ett beslutsst\"odsystem f\"or hantering och analys av underr\"attelser om fr\"ammande undervattensverksamhet.
* 18 pages, 8 figures, in Swedish, with appendix in English
Robust Report Level Cluster-to-Track Fusion
May 16, 2003



In this paper we develop a method for report level tracking based on Dempster-Shafer clustering using Potts spin neural networks where clusters of incoming reports are gradually fused into existing tracks, one cluster for each track. Incoming reports are put into a cluster and continuous reclustering of older reports is made in order to obtain maximum association fit within the cluster and towards the track. Over time, the oldest reports of the cluster leave the cluster for the fixed track at the same rate as new incoming reports are put into it. Fusing reports to existing tracks in this fashion allows us to take account of both existing tracks and the probable future of each track, as represented by younger reports within the corresponding cluster. This gives us a robust report-to-track association. Compared to clustering of all available reports this approach is computationally faster and has a better report-to-track association than simple step-by-step association.
* 6 pages, 5 figures
Clustering belief functions based on attracting and conflicting metalevel evidence
May 16, 2003


In this paper we develop a method for clustering belief functions based on attracting and conflicting metalevel evidence. Such clustering is done when the belief functions concern multiple events, and all belief functions are mixed up. The clustering process is used as the means for separating the belief functions into subsets that should be handled independently. While the conflicting metalevel evidence is generated internally from pairwise conflicts of all belief functions, the attracting metalevel evidence is assumed given by some external source.
* 8 pages, 3 figures
Reliable Force Aggregation Using a Refined Evidence Specification from Dempster-Shafer Clustering
May 16, 2003



In this paper we develop methods for selection of templates and use these templates to recluster an already performed Dempster-Shafer clustering taking into account intelligence to template fit during the reclustering phase. By this process the risk of erroneous force aggregation based on some misplace pieces of evidence from the first clustering process is greatly reduced. Finally, a more reliable force aggregation is performed using the result of the second clustering. These steps are taken in order to maintain most of the excellent computational performance of Dempster-Shafer clustering, while at the same time improve on the clustering result by including some higher relations among intelligence reports described by the templates. The new improved algorithm has a computational complexity of O(n**3 log**2 n) compared to O(n**2 log**2 n) of standard Dempster-Shafer clustering using Potts spin mean field theory.
* 8 pages, 5 figures
Conflict-based Force Aggregation
May 16, 2003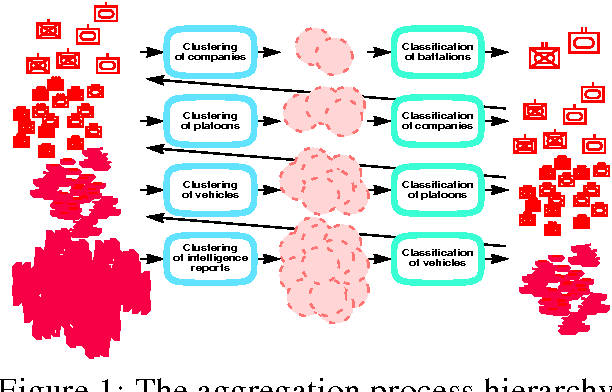
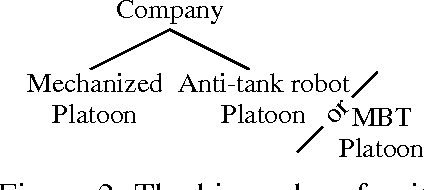

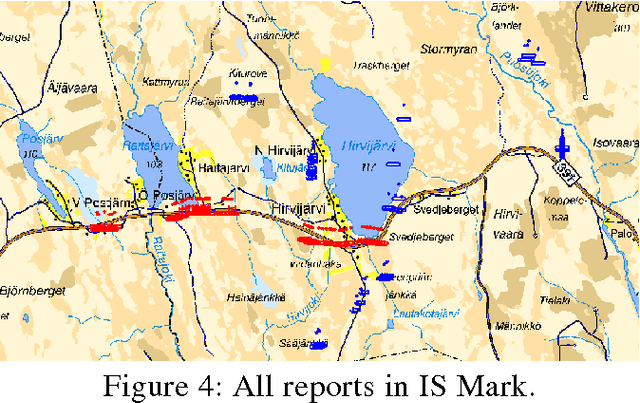
In this paper we present an application where we put together two methods for clustering and classification into a force aggregation method. Both methods are based on conflicts between elements. These methods work with different type of elements (intelligence reports, vehicles, military units) on different hierarchical levels using specific conflict assessment methods on each level. We use Dempster-Shafer theory for conflict calculation between elements, Dempster-Shafer clustering for clustering these elements, and templates for classification. The result of these processes is a complete force aggregation on all levels handled.
* 15 pages, 17 figures
Dempster-Shafer clustering using Potts spin mean field theory
May 16, 2003In this article we investigate a problem within Dempster-Shafer theory where 2**q - 1 pieces of evidence are clustered into q clusters by minimizing a metaconflict function, or equivalently, by minimizing the sum of weight of conflict over all clusters. Previously one of us developed a method based on a Hopfield and Tank model. However, for very large problems we need a method with lower computational complexity. We demonstrate that the weight of conflict of evidence can, as an approximation, be linearized and mapped to an antiferromagnetic Potts Spin model. This facilitates efficient numerical solution, even for large problem sizes. Optimal or nearly optimal solutions are found for Dempster-Shafer clustering benchmark tests with a time complexity of approximately O(N**2 log**2 N). Furthermore, an isomorphism between the antiferromagnetic Potts spin model and a graph optimization problem is shown. The graph model has dynamic variables living on the links, which have a priori probabilities that are directly related to the pairwise conflict between pieces of evidence. Hence, the relations between three different models are shown.
* 14 pages, 9 figures
Managing Inconsistent Intelligence
May 16, 2003

In this paper we demonstrate that it is possible to manage intelligence in constant time as a pre-process to information fusion through a series of processes dealing with issues such as clustering reports, ranking reports with respect to importance, extraction of prototypes from clusters and immediate classification of newly arriving intelligence reports. These methods are used when intelligence reports arrive which concerns different events which should be handled independently, when it is not known a priori to which event each intelligence report is related. We use clustering that runs as a back-end process to partition the intelligence into subsets representing the events, and in parallel, a fast classification that runs as a front-end process in order to put the newly arriving intelligence into its correct information fusion process.
* 7 pages, 3 figures