 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline learnability of Statistical Relational Learning in anomaly detection
May 18, 2017
Statistical Relational Learning (SRL) methods for anomaly detection are introduced via a security-related application. Operational requirements for online learning stability are outlined and compared to mathematical definitions as applied to the learning process of a representative SRL method - Bayesian Logic Programs (BLP). Since a formal proof of online stability appears to be impossible, tentative common sense requirements are formulated and tested by theoretical and experimental analysis of a simple and analytically tractable BLP model. It is found that learning algorithms in initial stages of online learning can lock on unstable false predictors that nevertheless comply with our tentative stability requirements and thus masquerade as bona fide solutions. The very expressiveness of SRL seems to cause significant stability issues in settings with many variables and scarce data. We conclude that reliable anomaly detection with SRL-methods requires monitoring by an overarching framework that may involve a comprehensive context knowledge base or human supervision.
* 8 pages. Author contact xpontus@gmail.com
Ensemble approaches for improving community detection methods
Sep 01, 2013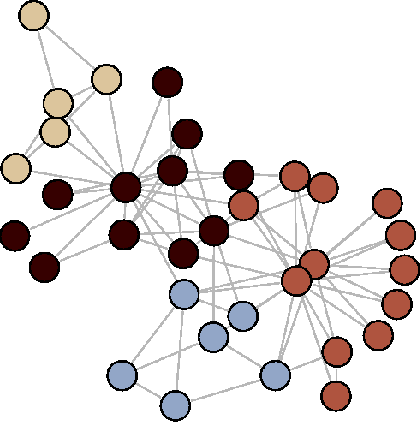
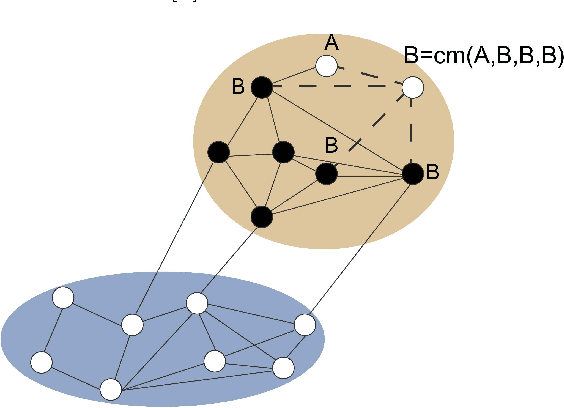
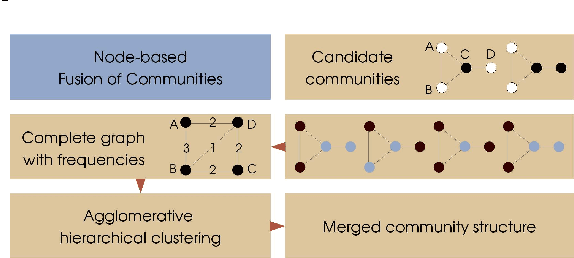
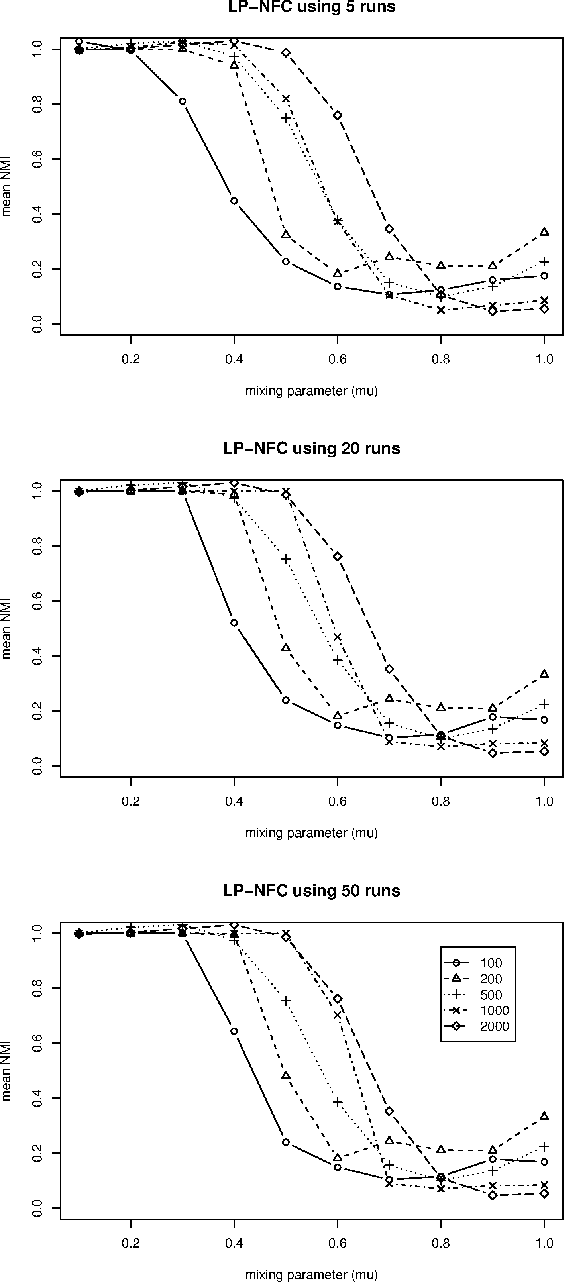
Statistical estimates can often be improved by fusion of data from several different sources. One example is so-called ensemble methods which have been successfully applied in areas such as machine learning for classification and clustering. In this paper, we present an ensemble method to improve community detection by aggregating the information found in an ensemble of community structures. This ensemble can found by re-sampling methods, multiple runs of a stochastic community detection method, or by several different community detection algorithms applied to the same network. The proposed method is evaluated using random networks with community structures and compared with two commonly used community detection methods. The proposed method when applied on a stochastic community detection algorithm performs well with low computational complexity, thus offering both a new approach to community detection and an additional community detection method.
Extremal optimization for sensor report pre-processing
Nov 19, 2004We describe the recently introduced extremal optimization algorithm and apply it to target detection and association problems arising in pre-processing for multi-target tracking. Here we consider the problem of pre-processing for multiple target tracking when the number of sensor reports received is very large and arrives in large bursts. In this case, it is sometimes necessary to pre-process reports before sending them to tracking modules in the fusion system. The pre-processing step associates reports to known tracks (or initializes new tracks for reports on objects that have not been seen before). It could also be used as a pre-process step before clustering, e.g., in order to test how many clusters to use. The pre-processing is done by solving an approximate version of the original problem. In this approximation, not all pair-wise conflicts are calculated. The approximation relies on knowing how many such pair-wise conflicts that are necessary to compute. To determine this, results on phase-transitions occurring when coloring (or clustering) large random instances of a particular graph ensemble are used.
* 10 pages
Comparing Multi-Target Trackers on Different Force Unit Levels
Nov 19, 2004Consider the problem of tracking a set of moving targets. Apart from the tracking result, it is often important to know where the tracking fails, either to steer sensors to that part of the state-space, or to inform a human operator about the status and quality of the obtained information. An intuitive quality measure is the correlation between two tracking results based on uncorrelated observations. In the case of Bayesian trackers such a correlation measure could be the Kullback-Leibler difference. We focus on a scenario with a large number of military units moving in some terrain. The units are observed by several types of sensors and "meta-sensors" with force aggregation capabilities. The sensors register units of different size. Two separate multi-target probability hypothesis density (PHD) particle filters are used to track some type of units (e.g., companies) and their sub-units (e.g., platoons), respectively, based on observations of units of those sizes. Each observation is used in one filter only. Although the state-space may well be the same in both filters, the posterior PHD distributions are not directly comparable -- one unit might correspond to three or four spatially distributed sub-units. Therefore, we introduce a mapping function between distributions for different unit size, based on doctrine knowledge of unit configuration. The mapped distributions can now be compared -- locally or globally -- using some measure, which gives the correlation between two PHD distributions in a bounded volume of the state-space. To locate areas where the tracking fails, a discretized quality map of the state-space can be generated by applying the measure locally to different parts of the space.
* 9 pages
Determining possible avenues of approach using ANTS
Apr 04, 2003



Threat assessment is an important part of level 3 data fusion. Here we study a subproblem of this, worst-case risk assessment. Inspired by agent-based models used for simulation of trail formation for urban planning, we use ant colony optimization (ANTS) to determine possible avenues of approach for the enemy, given a situation picture. One way of determining such avenues would be to calculate the ``potential field'' caused by placing sources at possible goals for the enemy. This requires postulating a functional form for the potential, and also takes long time. Here we instead seek a method for quickly obtaining an effective potential. ANTS, which has previously been used to obtain approximate solutions to various optimization problems, is well suited for this. The output of our method describes possible avenues of approach for the enemy, i.e, areas where we should be prepared for attack. (The algorithm can also be run ``reversed'' to instead get areas of opportunity for our forces to exploit.) Using real geographical data, we found that our method gives a fast and reliable way of determining such avenues. Our method can be used in a computer-based command and control system to replace the first step of human intelligence analysis.
* 8 pages, 12 figures. Accepted for 6th Int. Conf. Information Fusion, Cairns 2003
Relaxation in graph coloring and satisfiability problems
Jan 26, 1999

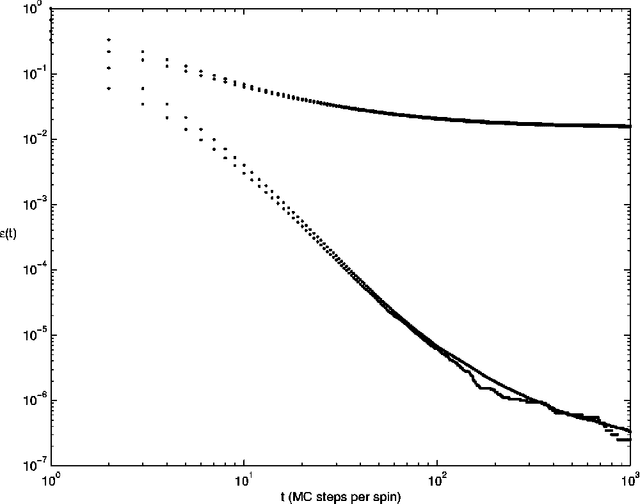

Using T=0 Monte Carlo simulation, we study the relaxation of graph coloring (K-COL) and satisfiability (K-SAT), two hard problems that have recently been shown to possess a phase transition in solvability as a parameter is varied. A change from exponentially fast to power law relaxation, and a transition to freezing behavior are found. These changes take place for smaller values of the parameter than the solvability transition. Results for the coloring problem for colorable and clustered graphs and for the fraction of persistent spins for satisfiability are also presented.
* 13 pages, 22 figures. Several changes to text, figures added, section on feromagnetic model moved to a separate publication. Accepted for publication in Phys Rev. E