 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAN-BERT do it? Controller Area Network Intrusion Detection System based on BERT Language Model
Oct 17, 2022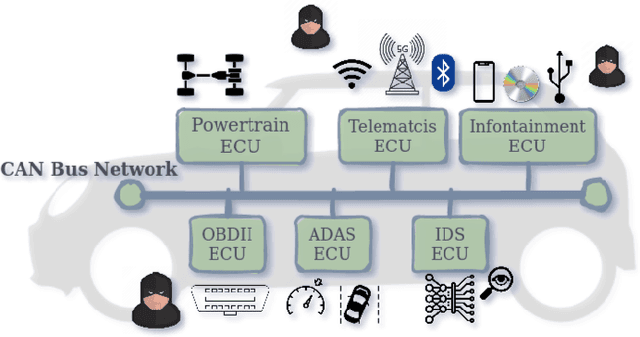

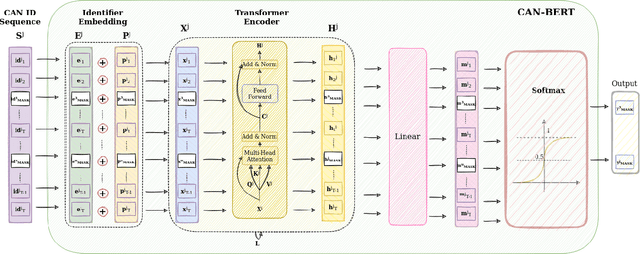
Due to the rising number of sophisticated customer functionalities, electronic control units (ECUs) are increasingly integrated into modern automotive systems. However, the high connectivity between the in-vehicle and the external networks paves the way for hackers who could exploit in-vehicle network protocols' vulnerabilities. Among these protocols, the Controller Area Network (CAN), known as the most widely used in-vehicle networking technology, lacks encryption and authentication mechanisms, making the communications delivered by distributed ECUs insecure. Inspired by the outstanding performance of bidirectional encoder representations from transformers (BERT) for improving many natural language processing tasks, we propose in this paper ``CAN-BERT", a deep learning based network intrusion detection system, to detect cyber attacks on CAN bus protocol. We show that the BERT model can learn the sequence of arbitration identifiers (IDs) in the CAN bus for anomaly detection using the ``masked language model" unsupervised training objective. The experimental results on the ``Car Hacking: Attack \& Defense Challenge 2020" dataset show that ``CAN-BERT" outperforms state-of-the-art approaches. In addition to being able to identify in-vehicle intrusions in real-time within 0.8 ms to 3 ms w.r.t CAN ID sequence length, it can also detect a wide variety of cyberattacks with an F1-score of between 0.81 and 0.99.
AVTPnet: Convolutional Autoencoder for AVTP anomaly detection in Automotive Ethernet Networks
Jan 31, 2022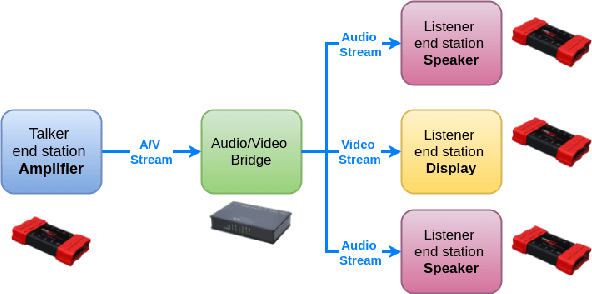
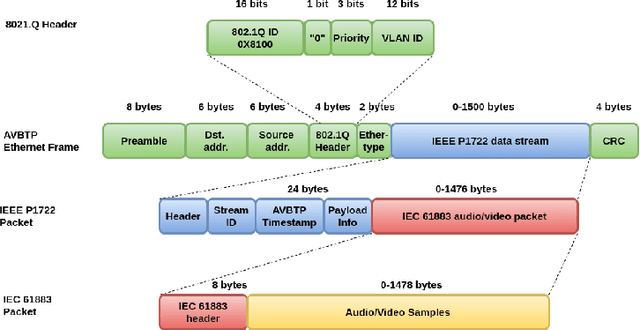
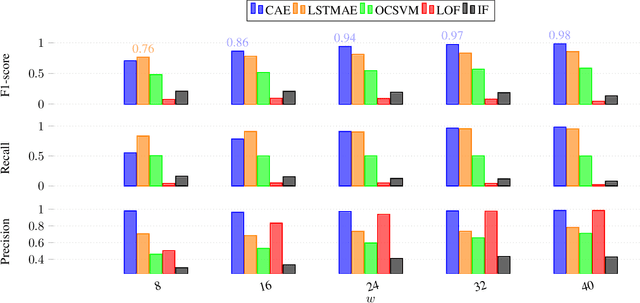
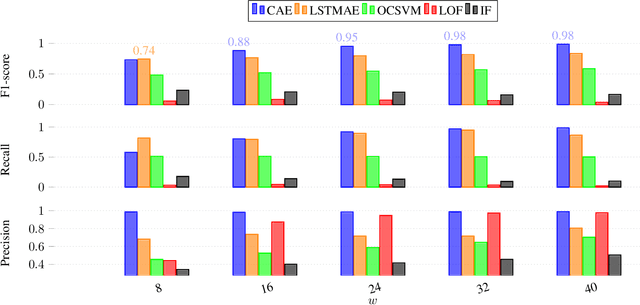
Network Intrusion Detection Systems are well considered as efficient tools for securing in-vehicle networks against diverse cyberattacks. However, since cyberattack are always evolving, signature-based intrusion detection systems are no longer adopted. An alternative solution can be the deployment of deep learning based intrusion detection system (IDS) which play an important role in detecting unknown attack patterns in network traffic. To our knowledge, no previous research work has been done to detect anomalies on automotive ethernet based in-vehicle networks using anomaly based approaches. Hence, in this paper, we propose a convolutional autoencoder (CAE) for offline detection of anomalies on the Audio Video Transport Protocol (AVTP), an application layer protocol implemented in the recent in-vehicle network Automotive Ethernet. The CAE consists of an encoder and a decoder with CNN structures that are asymmetrical. Anomalies in AVTP packet stream, which may lead to critical interruption of media streams, are therefore detected by measuring the reconstruction error of each sliding window of AVTP packets. Our proposed approach is evaluated on the recently published "Automotive Ethernet Intrusion Dataset", and is also compared with other state-of-the art traditional anomaly detection and signature based models in machine learning. The numerical results show that our proposed model outperfoms the other methods and excel at predicting unknown in-vehicle intrusions, with 0.94 accuracy. Moreover, our model has a low level of false alarm and miss detection rates for different AVTP attack types.
SOME/IP Intrusion Detection using Deep Learning-based Sequential Models in Automotive Ethernet Networks
Aug 04, 2021
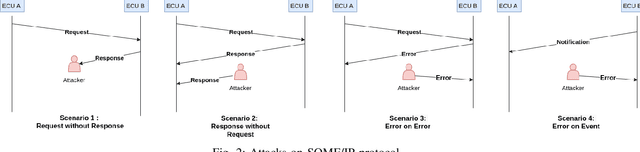
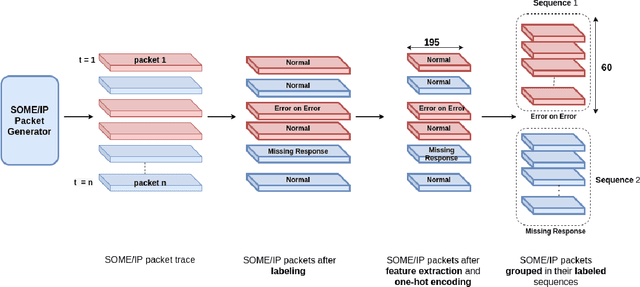
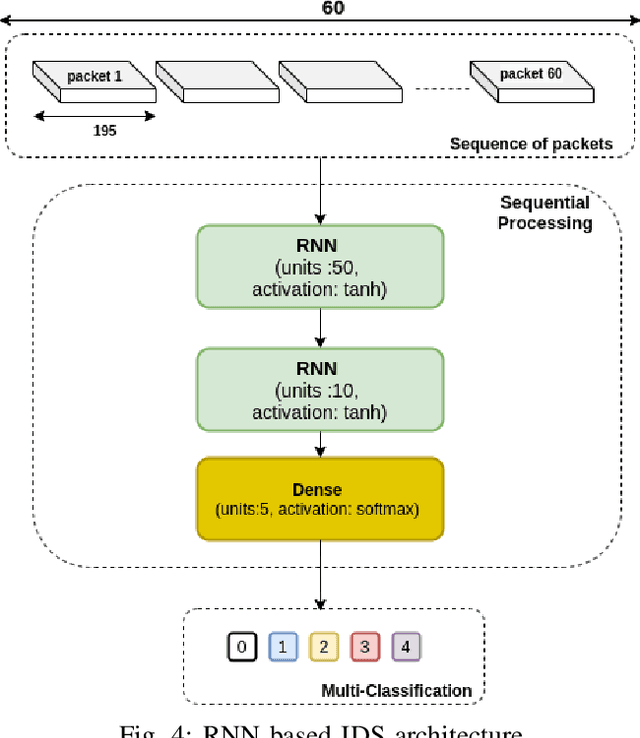
Intrusion Detection Systems are widely used to detect cyberattacks, especially on protocols vulnerable to hacking attacks such as SOME/IP. In this paper, we present a deep learning-based sequential model for offline intrusion detection on SOME/IP application layer protocol. To assess our intrusion detection system, we have generated and labeled a dataset with several classes representing realistic intrusions, and a normal class - a significant contribution due to the absence of such publicly available datasets. Furthermore, we also propose a simple recurrent neural network (RNN), as an instance of deep learning-based sequential model, that we apply to our generated dataset. The numerical results show that RNN excel at predicting in-vehicle intrusions, with F1 Scores and AUC values of 0.99 for each type of intrusion.
Dual Optimization for Kolmogorov Model Learning Using Enhanced Gradient Descent
Jul 11, 2021
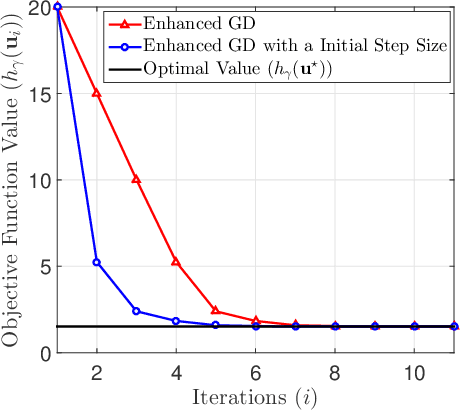
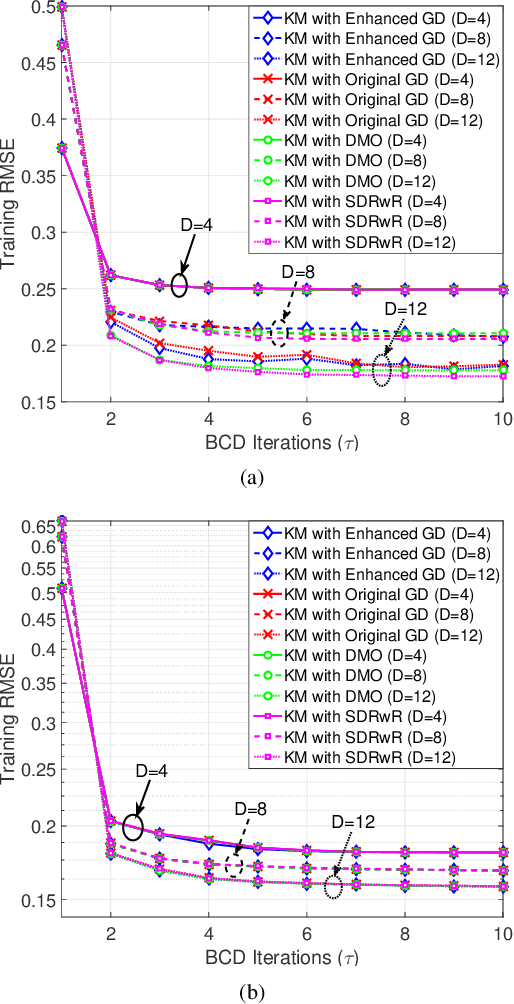
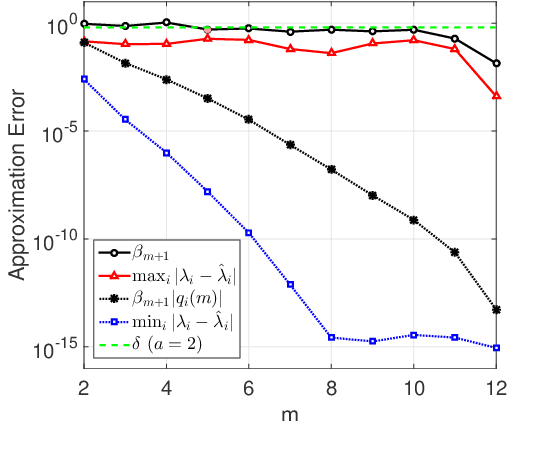
Data representation techniques have made a substantial contribution to advancing data processing and machine learning (ML). Improving predictive power was the focus of previous representation techniques, which unfortunately perform rather poorly on the interpretability in terms of extracting underlying insights of the data. Recently, Kolmogorov model (KM) was studied, which is an interpretable and predictable representation approach to learning the underlying probabilistic structure of a set of random variables. The existing KM learning algorithms using semi-definite relaxation with randomization (SDRwR) or discrete monotonic optimization (DMO) have, however, limited utility to big data applications because they do not scale well computationally. In this paper, we propose a computationally scalable KM learning algorithm, based on the regularized dual optimization combined with enhanced gradient descent (GD) method. To make our method more scalable to large-dimensional problems, we propose two acceleration schemes, namely, eigenvalue decomposition (EVD) elimination strategy and proximal EVD algorithm. Furthermore, a thresholding technique by exploiting the approximation error analysis and leveraging the normalized Minkowski $\ell_1$-norm and its bounds, is provided for the selection of the number of iterations of the proximal EVD algorithm. When applied to big data applications, it is demonstrated that the proposed method can achieve compatible training/prediction performance with significantly reduced computational complexity; roughly two orders of magnitude improvement in terms of the time overhead, compared to the existing KM learning algorithms. Furthermore, it is shown that the accuracy of logical relation mining for interpretability by using the proposed KM learning algorithm exceeds $80\%$.
Enhanced Beam Alignment for Millimeter Wave MIMO Systems: A Kolmogorov Model
Jul 27, 2020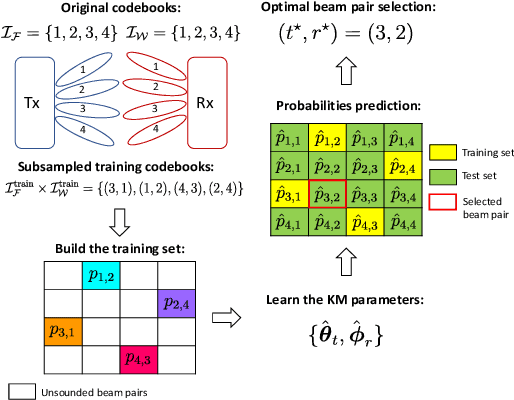
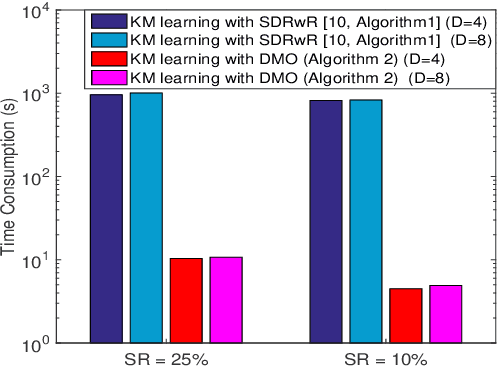
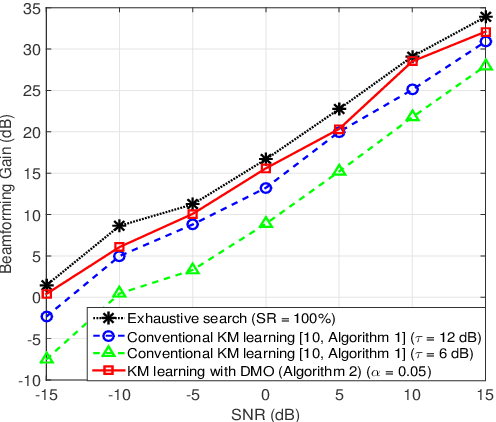
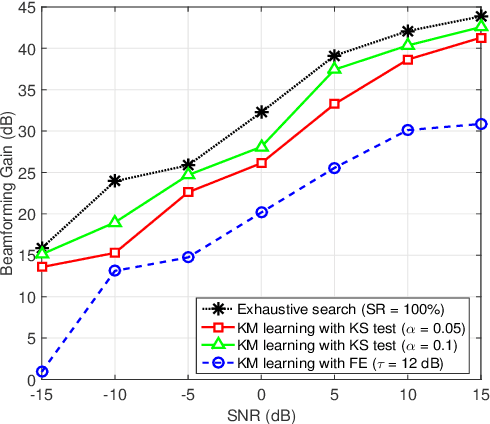
We present an enhancement to the problem of beam alignment in millimeter wave (mmWave) multiple-input multiple-output (MIMO) systems, based on a modification of the machine learning-based criterion, called Kolmogorov model (KM), previously applied to the beam alignment problem. Unlike the previous KM, whose computational complexity is not scalable with the size of the problem, a new approach, centered on discrete monotonic optimization (DMO), is proposed, leading to significantly reduced complexity. We also present a Kolmogorov-Smirnov (KS) criterion for the advanced hypothesis testing, which does not require any subjective threshold setting compared to the frequency estimation (FE) method developed for the conventional KM. Simulation results that demonstrate the efficacy of the proposed KM learning for mmWave beam alignment are presented.
A Hybrid Model-based and Data-driven Approach to Spectrum Sharing in mmWave Cellular Networks
Mar 19, 2020
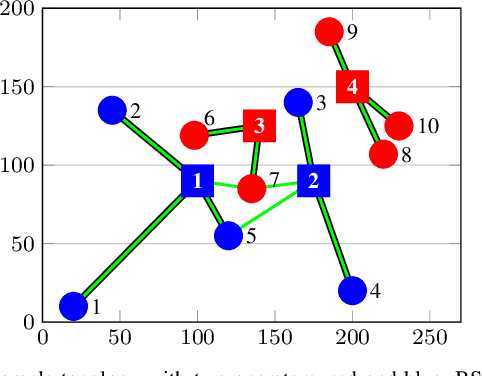
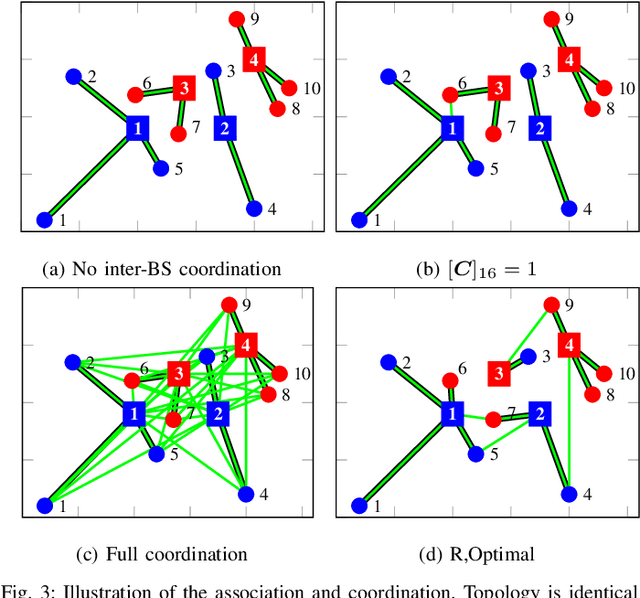
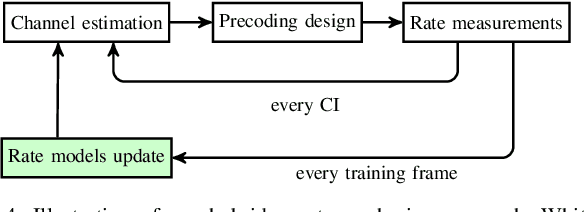
Inter-operator spectrum sharing in millimeter-wave bands has the potential of substantially increasing the spectrum utilization and providing a larger bandwidth to individual user equipment at the expense of increasing inter-operator interference. Unfortunately, traditional model-based spectrum sharing schemes make idealistic assumptions about inter-operator coordination mechanisms in terms of latency and protocol overhead, while being sensitive to missing channel state information. In this paper, we propose hybrid model-based and data-driven multi-operator spectrum sharing mechanisms, which incorporate model-based beamforming and user association complemented by data-driven model refinements. Our solution has the same computational complexity as a model-based approach but has the major advantage of having substantially less signaling overhead. We discuss how limited channel state information and quantized codebook-based beamforming affect the learning and the spectrum sharing performance. We show that the proposed hybrid sharing scheme significantly improves spectrum utilization under realistic assumptions on inter-operator coordination and channel state information acquisition.
Learning Kolmogorov Models for Binary Random Variables
Jun 06, 2018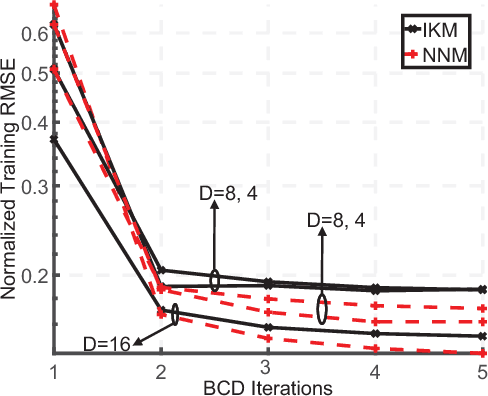

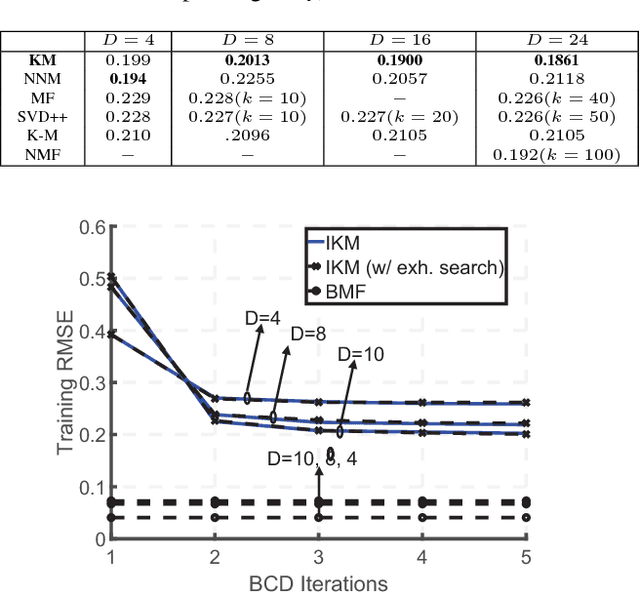
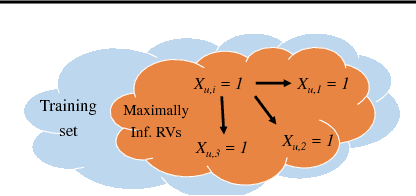
We summarize our recent findings, where we proposed a framework for learning a Kolmogorov model, for a collection of binary random variables. More specifically, we derive conditions that link outcomes of specific random variables, and extract valuable relations from the data. We also propose an algorithm for computing the model and show its first-order optimality, despite the combinatorial nature of the learning problem. We apply the proposed algorithm to recommendation systems, although it is applicable to other scenarios. We believe that the work is a significant step toward interpretable machine learning.
A Unified Framework for Training Neural Networks
May 23, 2018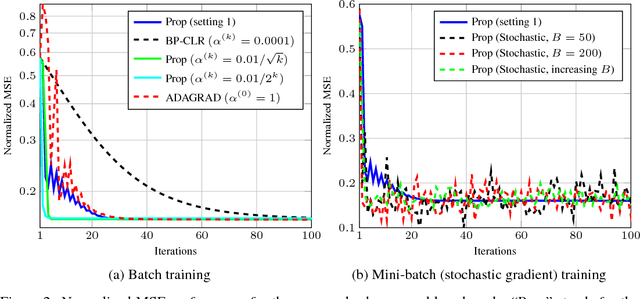
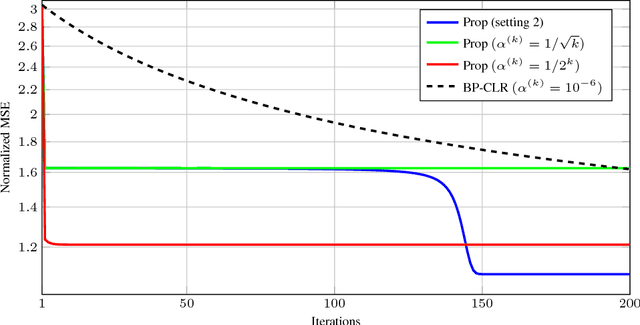
The lack of mathematical tractability of Deep Neural Networks (DNNs) has hindered progress towards having a unified convergence analysis of training algorithms, in the general setting. We propose a unified optimization framework for training different types of DNNs, and establish its convergence for arbitrary loss, activation, and regularization functions, assumed to be smooth. We show that framework generalizes well-known first- and second-order training methods, and thus allows us to show the convergence of these methods for various DNN architectures and learning tasks, as a special case of our approach. We discuss some of its applications in training various DNN architectures (e.g., feed-forward, convolutional, linear networks), to regression and classification tasks.
Learning-Based Resource Allocation Scheme for TDD-Based CRAN System
Aug 29, 2016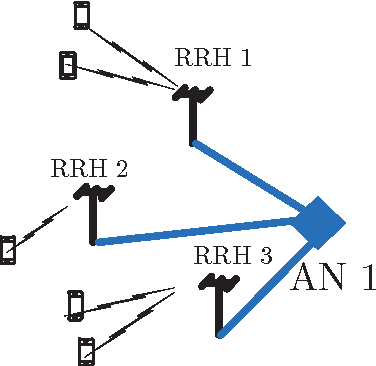

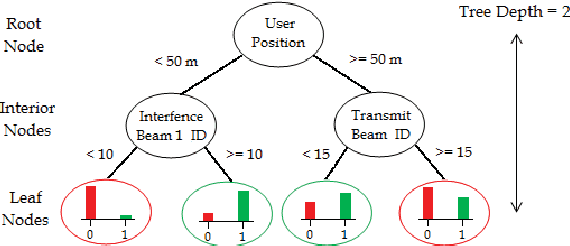

Explosive growth in the use of smart wireless devices has necessitated the provision of higher data rates and always-on connectivity, which are the main motivators for designing the fifth generation (5G) systems. To achieve higher system efficiency, massive antenna deployment with tight coordination is one potential strategy for designing 5G systems, but has two types of associated system overhead. First is the synchronization overhead, which can be reduced by implementing a cloud radio access network (CRAN)-based architecture design, that separates the baseband processing and radio access functionality to achieve better system synchronization. Second is the overhead for acquiring channel state information (CSI) of the users present in the system, which, however, increases tremendously when instantaneous CSI is used to serve high-mobility users. To serve a large number of users, a CRAN system with a dense deployment of remote radio heads (RRHs) is considered, such that each user has a line-of-sight (LOS) link with the corresponding RRH. Since, the trajectory of movement for high-mobility users is predictable; therefore, fairly accurate position estimates for those users can be obtained, and can be used for resource allocation to serve the considered users. The resource allocation is dependent upon various correlated system parameters, and these correlations can be learned using well-known \emph{machine learning} algorithms. This paper proposes a novel \emph{learning-based resource allocation scheme} for time division duplex (TDD) based 5G CRAN systems with dense RRH deployment, by using only the users' position estimates for resource allocation, thus avoiding the need for CSI acquisition. This reduces the overall system overhead significantly, while still achieving near-optimal system performance; thus, better (effective) system efficiency is achieved. (See the paper for full abstract)