 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-efficient Variance-reduced Stochastic Gradient Descent
Paper and Code
Mar 10, 2020
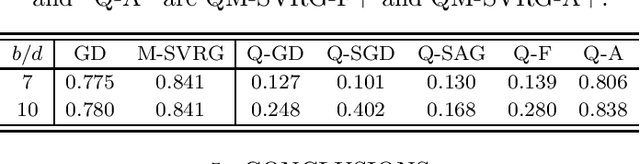
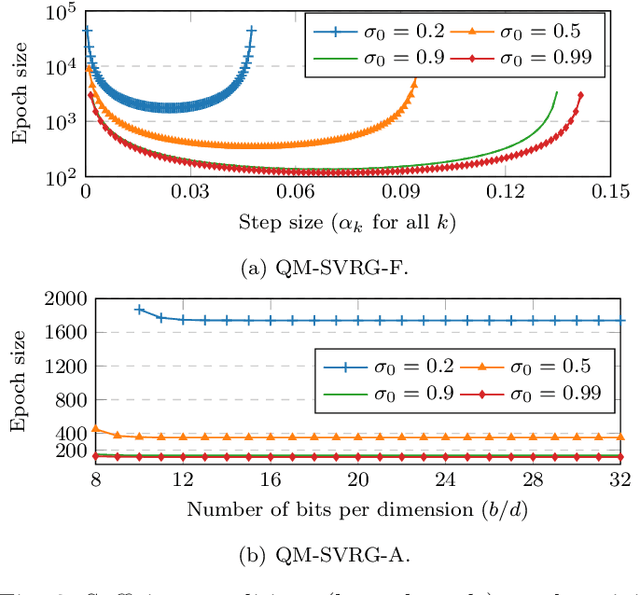
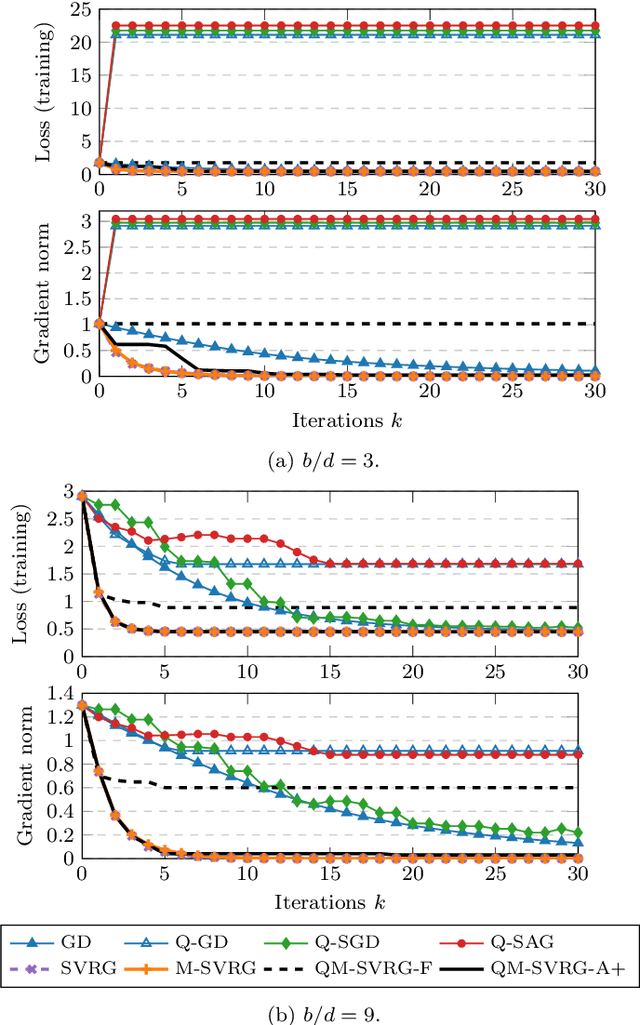
We consider the problem of communication efficient distributed optimization where multiple nodes exchange important algorithm information in every iteration to solve large problems. In particular, we focus on the stochastic variance-reduced gradient and propose a novel approach to make it communication-efficient. That is, we compress the communicated information to a few bits while preserving the linear convergence rate of the original uncompressed algorithm. Comprehensive theoretical and numerical analyses on real datasets reveal that our algorithm can significantly reduce the communication complexity, by as much as 95\%, with almost no noticeable penalty. Moreover, it is much more robust to quantization (in terms of maintaining the true minimizer and the convergence rate) than the state-of-the-art algorithms for solving distributed optimization problems. Our results have important implications for using machine learning over internet-of-things and mobile networks.