 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Communications in 6G: Coexistence, Multiple Access, and Satellite Networks
Jun 13, 2025The exponential growth of wireless users and bandwidth constraints necessitates innovative communication paradigms for next-generation networks. Semantic Communication (SemCom) emerges as a promising solution by transmitting extracted meaning rather than raw bits, enhancing spectral efficiency and enabling intelligent resource allocation. This paper explores the integration of SemCom with conventional Bit-based Communication (BitCom) in heterogeneous networks, highlighting key challenges and opportunities. We analyze multiple access techniques, including Non-Orthogonal Multiple Access (NOMA), to support coexisting SemCom and BitCom users. Furthermore, we examine multi-modal SemCom frameworks for handling diverse data types and discuss their applications in satellite networks, where semantic techniques mitigate bandwidth limitations and harsh channel conditions. Finally, we identify future directions for deploying semantic-aware systems in 6G and beyond.
Simulated Annealing Algorithm for Graph Coloring
Dec 03, 2017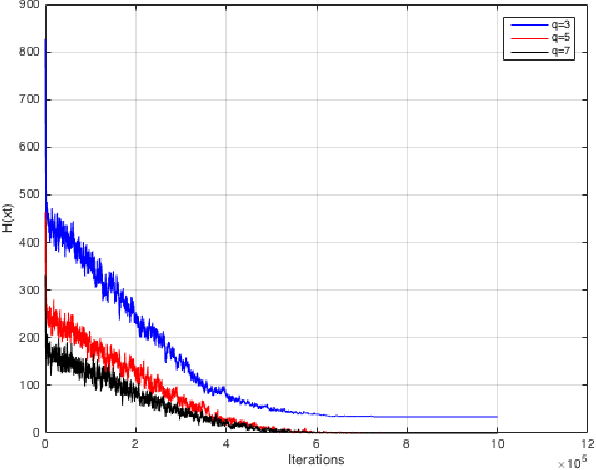


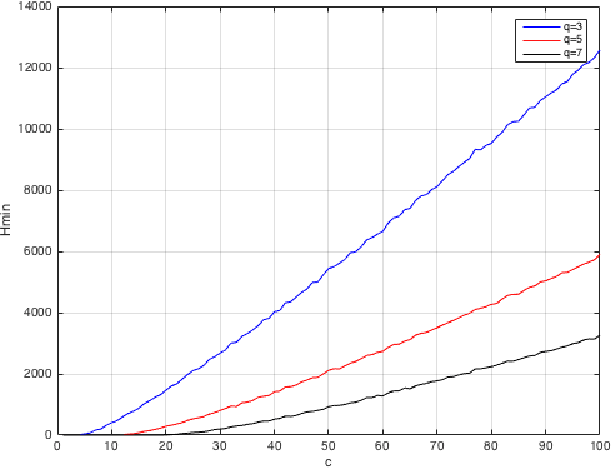
The goal of this Random Walks project is to code and experiment the Markov Chain Monte Carlo (MCMC) method for the problem of graph coloring. In this report, we present the plots of cost function \(\mathbf{H}\) by varying the parameters like \(\mathbf{q}\) (Number of colors that can be used in coloring) and \(\mathbf{c}\) (Average node degree). The results are obtained by using simulated annealing scheme, where the temperature (inverse of \(\mathbf{\beta}\)) parameter in the MCMC is lowered progressively.
An Asymptotically Optimal Algorithm for Communicating Multiplayer Multi-Armed Bandit Problems
Dec 02, 2017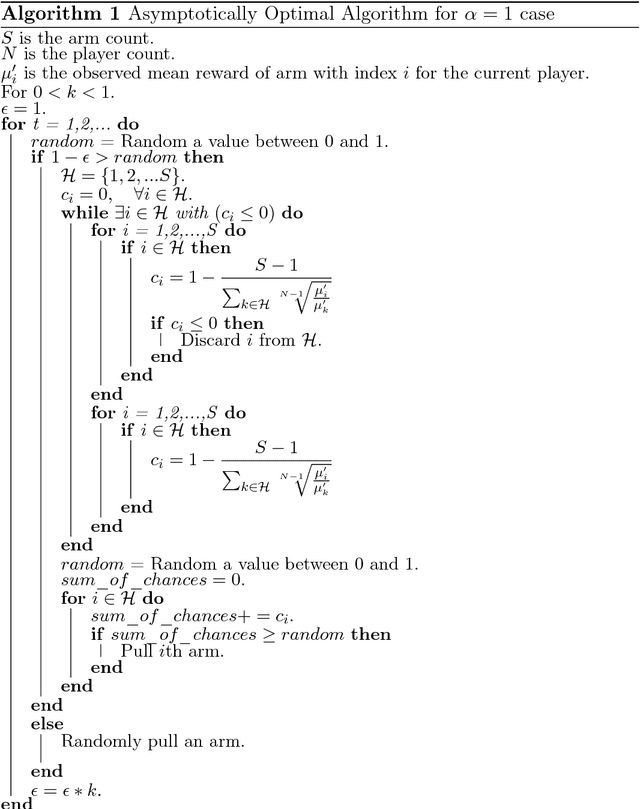
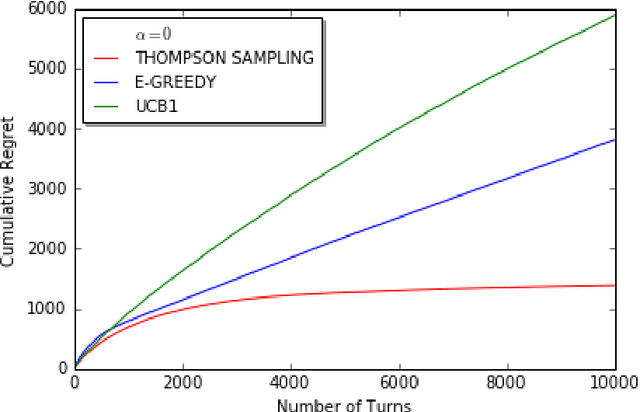

We consider a decentralized stochastic multi-armed bandit problem with multiple players. Each player aims to maximize his/her own reward by pulling an arm. The arms give rewards based on i.i.d. stochastic Bernoulli distributions. Players are not aware about the probability distributions of the arms. At the end of each turn, the players inform their neighbors about the arm he/she pulled and the reward he/she got. Neighbors of players are determined according to an Erd{\H{o}}s-R{\'e}nyi graph with connectivity $\alpha$. This graph is reproduced in the beginning of every turn with the same connectivity. When more than one player choose the same arm in a turn, we assume that only one of the players who is randomly chosen gets the reward where the others get nothing. We first start by assuming players are not aware of the collision model and offer an asymptotically optimal algorithm for $\alpha = 1$ case. Then, we extend our prior work and offer an asymptotically optimal algorithm for any connectivity but zero, assuming players aware of the collision model. We also study the effect of $\alpha$, the degree of communication between players, empirically on the cumulative regret by comparing them with traditional multi-armed bandit algorithms.
Performance Comparison of Algorithms for Movie Rating Estimation
Nov 05, 2017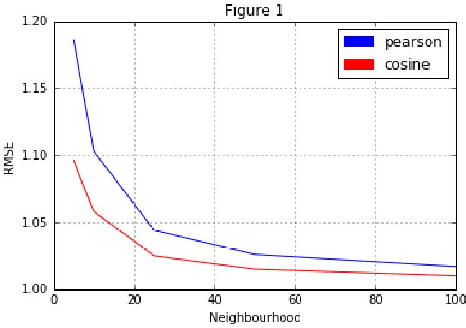
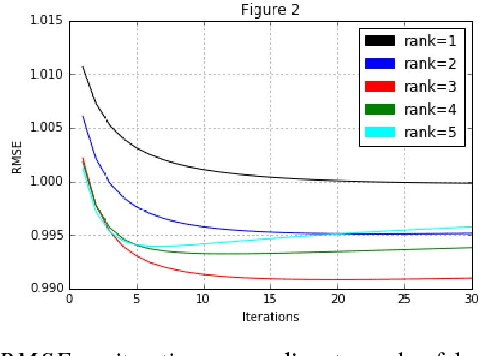


In this paper, our goal is to compare performances of three different algorithms to predict the ratings that will be given to movies by potential users where we are given a user-movie rating matrix based on the past observations. To this end, we evaluate User-Based Collaborative Filtering, Iterative Matrix Factorization and Yehuda Koren's Integrated model using neighborhood and factorization where we use root mean square error (RMSE) as the performance evaluation metric. In short, we do not observe significant differences between performances, especially when the complexity increase is considered. We can conclude that Iterative Matrix Factorization performs fairly well despite its simplicity.
The Effect of Communication on Noncooperative Multiplayer Multi-Armed Bandit Problems
Nov 05, 2017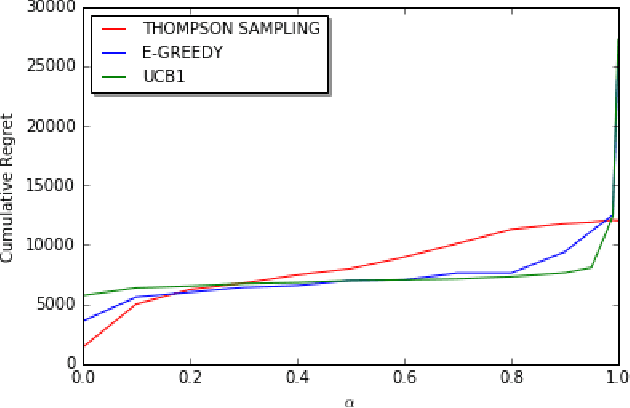
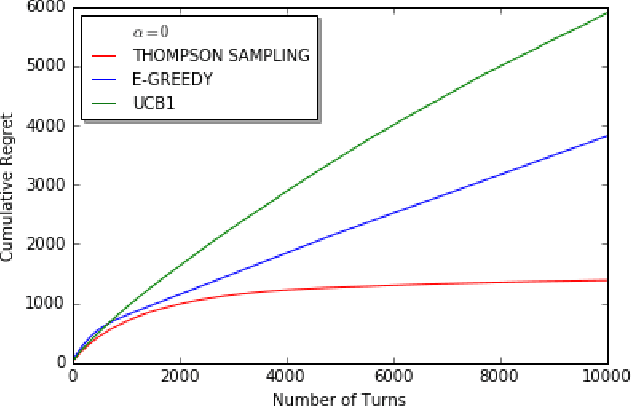
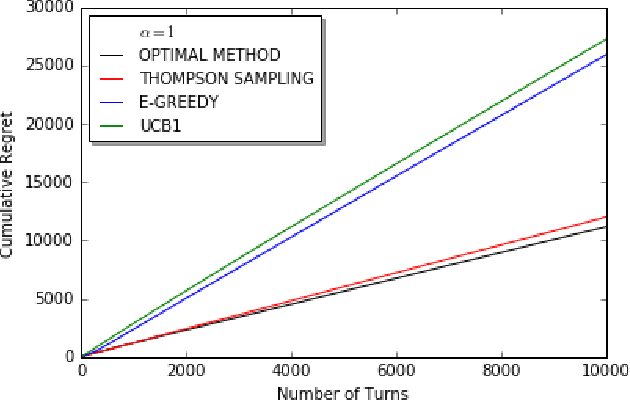
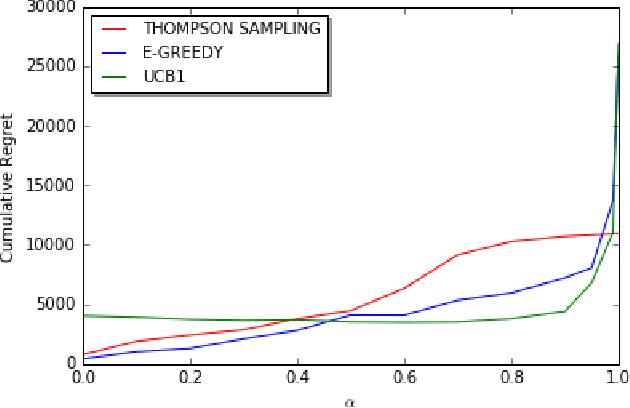
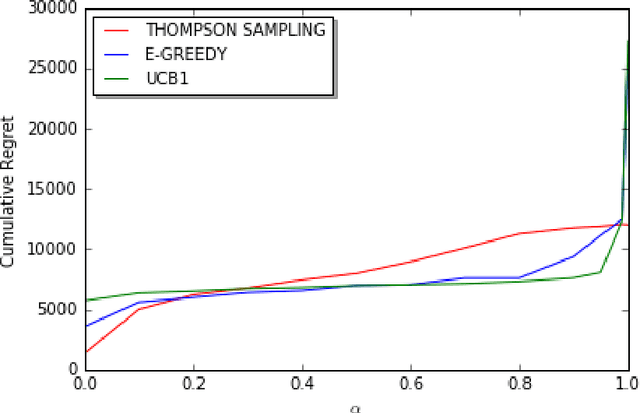
We consider decentralized stochastic multi-armed bandit problem with multiple players in the case of different communication probabilities between players. Each player makes a decision of pulling an arm without cooperation while aiming to maximize his or her reward but informs his or her neighbors in the end of every turn about the arm he or she pulled and the reward he or she got. Neighbors of players are determined according to an Erdos-Renyi graph with which is reproduced in the beginning of every turn. We consider i.i.d. rewards generated by a Bernoulli distribution and assume that players are unaware about the arms' probability distributions and their mean values. In case of a collision, we assume that only one of the players who is randomly chosen gets the reward where the others get zero reward. We study the effects of connectivity, the degree of communication between players, on the cumulative regret using well-known algorithms UCB1, epsilon-Greedy and Thompson Sampling.