 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDegradation-Aware Feature Perturbation for All-in-One Image Restoration
May 19, 2025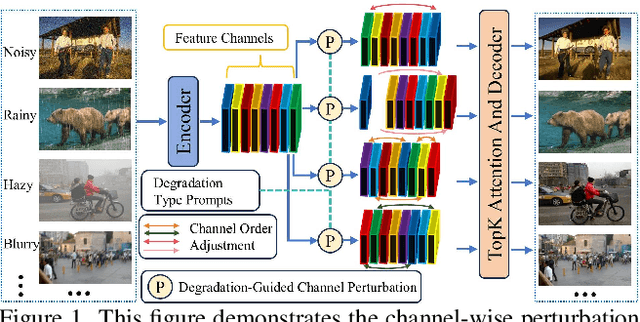
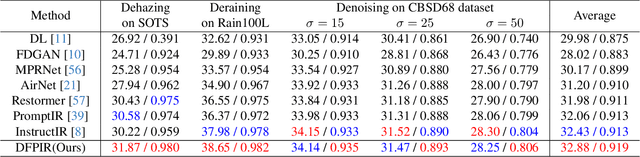
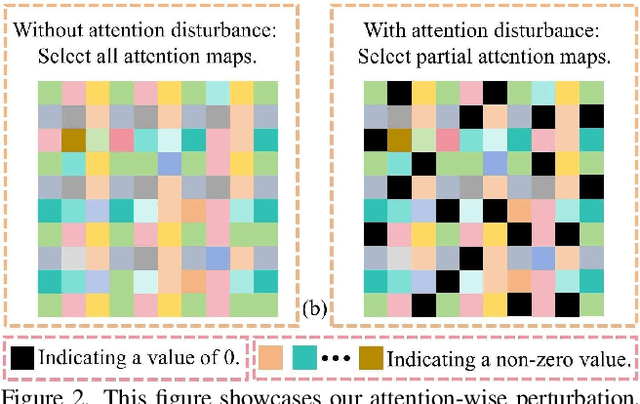
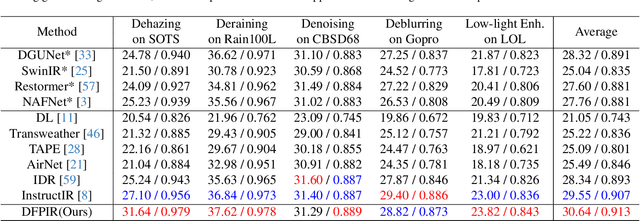
All-in-one image restoration aims to recover clear images from various degradation types and levels with a unified model. Nonetheless, the significant variations among degradation types present challenges for training a universal model, often resulting in task interference, where the gradient update directions of different tasks may diverge due to shared parameters. To address this issue, motivated by the routing strategy, we propose DFPIR, a novel all-in-one image restorer that introduces Degradation-aware Feature Perturbations(DFP) to adjust the feature space to align with the unified parameter space. In this paper, the feature perturbations primarily include channel-wise perturbations and attention-wise perturbations. Specifically, channel-wise perturbations are implemented by shuffling the channels in high-dimensional space guided by degradation types, while attention-wise perturbations are achieved through selective masking in the attention space. To achieve these goals, we propose a Degradation-Guided Perturbation Block (DGPB) to implement these two functions, positioned between the encoding and decoding stages of the encoder-decoder architecture. Extensive experimental results demonstrate that DFPIR achieves state-of-the-art performance on several all-in-one image restoration tasks including image denoising, image dehazing, image deraining, motion deblurring, and low-light image enhancement. Our codes are available at https://github.com/TxpHome/DFPIR.
Exploring Semantic Feature Discrimination for Perceptual Image Super-Resolution and Opinion-Unaware No-Reference Image Quality Assessment
Mar 25, 2025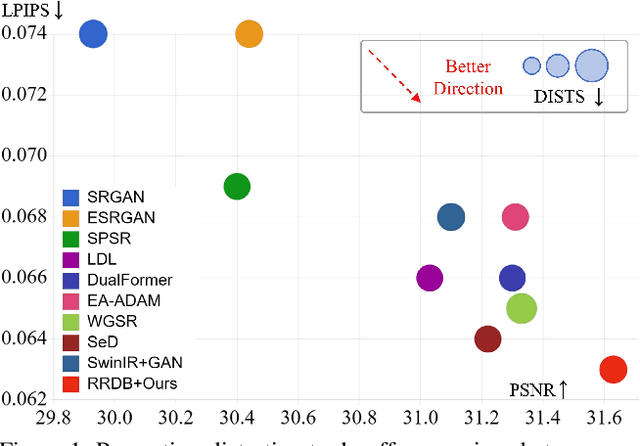
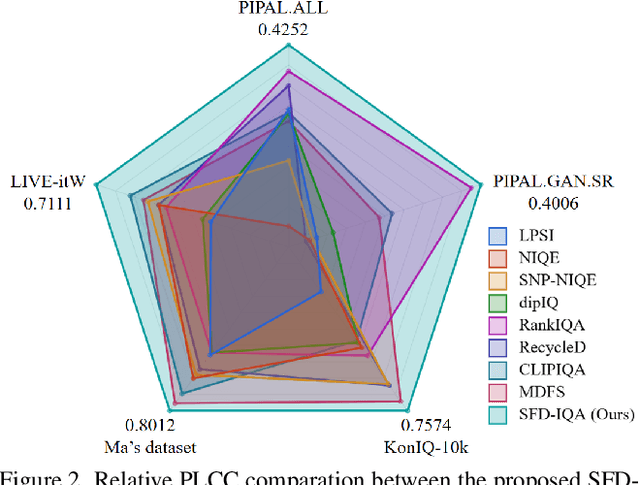
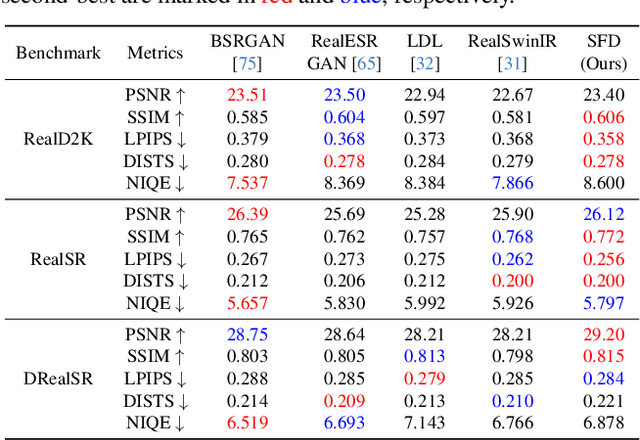
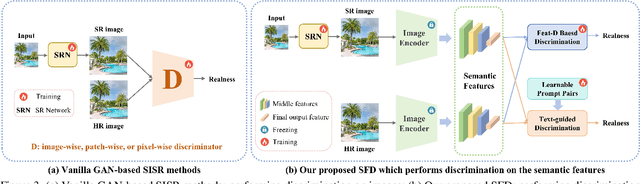
Generative Adversarial Networks (GANs) have been widely applied to image super-resolution (SR) to enhance the perceptual quality. However, most existing GAN-based SR methods typically perform coarse-grained discrimination directly on images and ignore the semantic information of images, making it challenging for the super resolution networks (SRN) to learn fine-grained and semantic-related texture details. To alleviate this issue, we propose a semantic feature discrimination method, SFD, for perceptual SR. Specifically, we first design a feature discriminator (Feat-D), to discriminate the pixel-wise middle semantic features from CLIP, aligning the feature distributions of SR images with that of high-quality images. Additionally, we propose a text-guided discrimination method (TG-D) by introducing learnable prompt pairs (LPP) in an adversarial manner to perform discrimination on the more abstract output feature of CLIP, further enhancing the discriminative ability of our method. With both Feat-D and TG-D, our SFD can effectively distinguish between the semantic feature distributions of low-quality and high-quality images, encouraging SRN to generate more realistic and semantic-relevant textures. Furthermore, based on the trained Feat-D and LPP, we propose a novel opinion-unaware no-reference image quality assessment (OU NR-IQA) method, SFD-IQA, greatly improving OU NR-IQA performance without any additional targeted training. Extensive experiments on classical SISR, real-world SISR, and OU NR-IQA tasks demonstrate the effectiveness of our proposed methods.
Asymmetric Mask Scheme for Self-Supervised Real Image Denoising
Jul 10, 2024



In recent years, self-supervised denoising methods have gained significant success and become critically important in the field of image restoration. Among them, the blind spot network based methods are the most typical type and have attracted the attentions of a large number of researchers. Although the introduction of blind spot operations can prevent identity mapping from noise to noise, it imposes stringent requirements on the receptive fields in the network design, thereby limiting overall performance. To address this challenge, we propose a single mask scheme for self-supervised denoising training, which eliminates the need for blind spot operation and thereby removes constraints on the network structure design. Furthermore, to achieve denoising across entire image during inference, we propose a multi-mask scheme. Our method, featuring the asymmetric mask scheme in training and inference, achieves state-of-the-art performance on existing real noisy image datasets. All the source code will be made available to the public.
Random Sub-Samples Generation for Self-Supervised Real Image Denoising
Jul 31, 2023



With sufficient paired training samples, the supervised deep learning methods have attracted much attention in image denoising because of their superior performance. However, it is still very challenging to widely utilize the supervised methods in real cases due to the lack of paired noisy-clean images. Meanwhile, most self-supervised denoising methods are ineffective as well when applied to the real-world denoising tasks because of their strict assumptions in applications. For example, as a typical method for self-supervised denoising, the original blind spot network (BSN) assumes that the noise is pixel-wise independent, which is much different from the real cases. To solve this problem, we propose a novel self-supervised real image denoising framework named Sampling Difference As Perturbation (SDAP) based on Random Sub-samples Generation (RSG) with a cyclic sample difference loss. Specifically, we dig deeper into the properties of BSN to make it more suitable for real noise. Surprisingly, we find that adding an appropriate perturbation to the training images can effectively improve the performance of BSN. Further, we propose that the sampling difference can be considered as perturbation to achieve better results. Finally we propose a new BSN framework in combination with our RSG strategy. The results show that it significantly outperforms other state-of-the-art self-supervised denoising methods on real-world datasets. The code is available at https://github.com/p1y2z3/SDAP.