 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating the Visual World with Artificial Intelligence: A Roadmap
Nov 11, 2025The landscape of video generation is shifting, from a focus on generating visually appealing clips to building virtual environments that support interaction and maintain physical plausibility. These developments point toward the emergence of video foundation models that function not only as visual generators but also as implicit world models, models that simulate the physical dynamics, agent-environment interactions, and task planning that govern real or imagined worlds. This survey provides a systematic overview of this evolution, conceptualizing modern video foundation models as the combination of two core components: an implicit world model and a video renderer. The world model encodes structured knowledge about the world, including physical laws, interaction dynamics, and agent behavior. It serves as a latent simulation engine that enables coherent visual reasoning, long-term temporal consistency, and goal-driven planning. The video renderer transforms this latent simulation into realistic visual observations, effectively producing videos as a "window" into the simulated world. We trace the progression of video generation through four generations, in which the core capabilities advance step by step, ultimately culminating in a world model, built upon a video generation model, that embodies intrinsic physical plausibility, real-time multimodal interaction, and planning capabilities spanning multiple spatiotemporal scales. For each generation, we define its core characteristics, highlight representative works, and examine their application domains such as robotics, autonomous driving, and interactive gaming. Finally, we discuss open challenges and design principles for next-generation world models, including the role of agent intelligence in shaping and evaluating these systems. An up-to-date list of related works is maintained at this link.
RobuRCDet: Enhancing Robustness of Radar-Camera Fusion in Bird's Eye View for 3D Object Detection
Feb 18, 2025While recent low-cost radar-camera approaches have shown promising results in multi-modal 3D object detection, both sensors face challenges from environmental and intrinsic disturbances. Poor lighting or adverse weather conditions degrade camera performance, while radar suffers from noise and positional ambiguity. Achieving robust radar-camera 3D object detection requires consistent performance across varying conditions, a topic that has not yet been fully explored. In this work, we first conduct a systematic analysis of robustness in radar-camera detection on five kinds of noises and propose RobuRCDet, a robust object detection model in BEV. Specifically, we design a 3D Gaussian Expansion (3DGE) module to mitigate inaccuracies in radar points, including position, Radar Cross-Section (RCS), and velocity. The 3DGE uses RCS and velocity priors to generate a deformable kernel map and variance for kernel size adjustment and value distribution. Additionally, we introduce a weather-adaptive fusion module, which adaptively fuses radar and camera features based on camera signal confidence. Extensive experiments on the popular benchmark, nuScenes, show that our model achieves competitive results in regular and noisy conditions.
Dual-Representation Interaction Driven Image Quality Assessment with Restoration Assistance
Nov 26, 2024No-Reference Image Quality Assessment for distorted images has always been a challenging problem due to image content variance and distortion diversity. Previous IQA models mostly encode explicit single-quality features of synthetic images to obtain quality-aware representations for quality score prediction. However, performance decreases when facing real-world distortion and restored images from restoration models. The reason is that they do not consider the degradation factors of the low-quality images adequately. To address this issue, we first introduce the DRI method to obtain degradation vectors and quality vectors of images, which separately model the degradation and quality information of low-quality images. After that, we add the restoration network to provide the MOS score predictor with degradation information. Then, we design the Representation-based Semantic Loss (RS Loss) to assist in enhancing effective interaction between representations. Extensive experimental results demonstrate that the proposed method performs favorably against existing state-of-the-art models on both synthetic and real-world datasets.
Re-boosting Self-Collaboration Parallel Prompt GAN for Unsupervised Image Restoration
Aug 17, 2024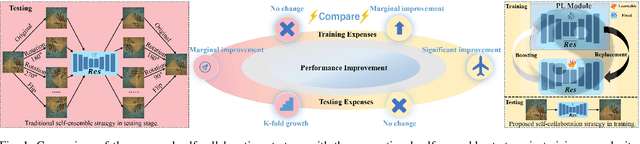
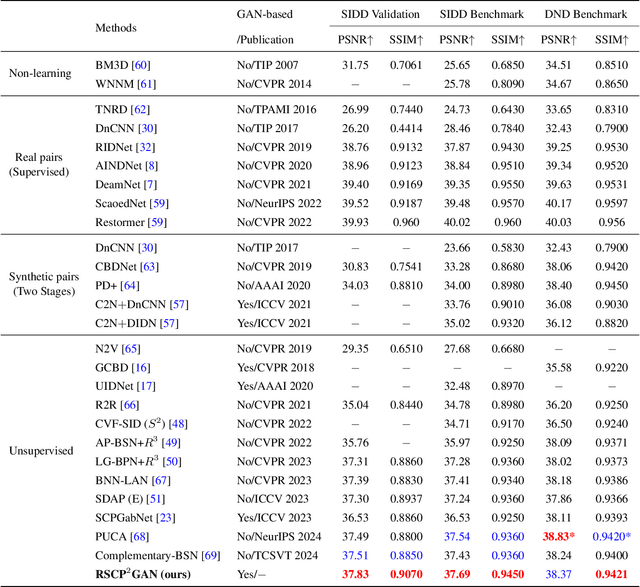
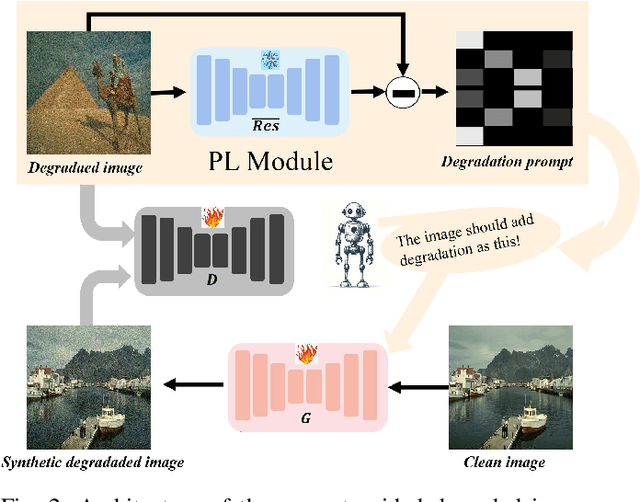
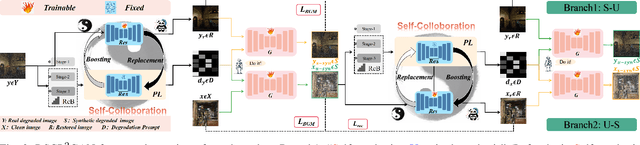
Unsupervised restoration approaches based on generative adversarial networks (GANs) offer a promising solution without requiring paired datasets. Yet, these GAN-based approaches struggle to surpass the performance of conventional unsupervised GAN-based frameworks without significantly modifying model structures or increasing the computational complexity. To address these issues, we propose a self-collaboration (SC) strategy for existing restoration models. This strategy utilizes information from the previous stage as feedback to guide subsequent stages, achieving significant performance improvement without increasing the framework's inference complexity. The SC strategy comprises a prompt learning (PL) module and a restorer ($Res$). It iteratively replaces the previous less powerful fixed restorer $\overline{Res}$ in the PL module with a more powerful $Res$. The enhanced PL module generates better pseudo-degraded/clean image pairs, leading to a more powerful $Res$ for the next iteration. Our SC can significantly improve the $Res$'s performance by over 1.5 dB without adding extra parameters or computational complexity during inference. Meanwhile, existing self-ensemble (SE) and our SC strategies enhance the performance of pre-trained restorers from different perspectives. As SE increases computational complexity during inference, we propose a re-boosting module to the SC (Reb-SC) to improve the SC strategy further by incorporating SE into SC without increasing inference time. This approach further enhances the restorer's performance by approximately 0.3 dB. Extensive experimental results on restoration tasks demonstrate that the proposed model performs favorably against existing state-of-the-art unsupervised restoration methods. Source code and trained models are publicly available at: \url{https://github.com/linxin0/RSCP2GAN}.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Unlocking Low-Light-Rainy Image Restoration by Pairwise Degradation Feature Vector Guidance
May 06, 2023

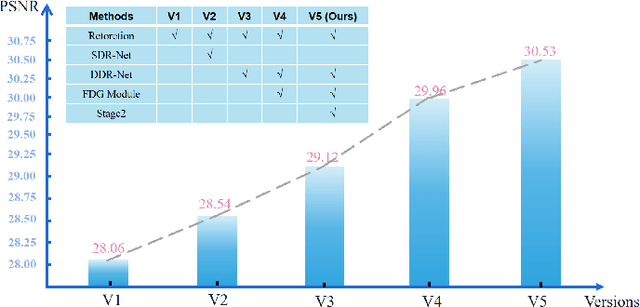

Rain in the dark is a common natural phenomenon. Photos captured in such a condition significantly impact the performance of various nighttime activities, such as autonomous driving, surveillance systems, and night photography. While existing methods designed for low-light enhancement or deraining show promising performance, they have limitations in simultaneously addressing the task of brightening low light and removing rain. Furthermore, using a cascade approach, such as ``deraining followed by low-light enhancement'' or vice versa, may lead to difficult-to-handle rain patterns or excessively blurred and overexposed images. To overcome these limitations, we propose an end-to-end network called $L^{2}RIRNet$ which can jointly handle low-light enhancement and deraining. Our network mainly includes a Pairwise Degradation Feature Vector Extraction Network (P-Net) and a Restoration Network (R-Net). P-Net can learn degradation feature vectors on the dark and light areas separately, using contrastive learning to guide the image restoration process. The R-Net is responsible for restoring the image. We also introduce an effective Fast Fourier - ResNet Detail Guidance Module (FFR-DG) that initially guides image restoration using detail image that do not contain degradation information but focus on texture detail information. Additionally, we contribute a dataset containing synthetic and real-world low-light-rainy images. Extensive experiments demonstrate that our $L^{2}RIRNet$ outperforms existing methods in both synthetic and complex real-world scenarios.