 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG3Splat: Geometrically Consistent Generalizable Gaussian Splatting
Dec 19, 20253D Gaussians have recently emerged as an effective scene representation for real-time splatting and accurate novel-view synthesis, motivating several works to adapt multi-view structure prediction networks to regress per-pixel 3D Gaussians from images. However, most prior work extends these networks to predict additional Gaussian parameters -- orientation, scale, opacity, and appearance -- while relying almost exclusively on view-synthesis supervision. We show that a view-synthesis loss alone is insufficient to recover geometrically meaningful splats in this setting. We analyze and address the ambiguities of learning 3D Gaussian splats under self-supervision for pose-free generalizable splatting, and introduce G3Splat, which enforces geometric priors to obtain geometrically consistent 3D scene representations. Trained on RE10K, our approach achieves state-of-the-art performance in (i) geometrically consistent reconstruction, (ii) relative pose estimation, and (iii) novel-view synthesis. We further demonstrate strong zero-shot generalization on ScanNet, substantially outperforming prior work in both geometry recovery and relative pose estimation. Code and pretrained models are released on our project page (https://m80hz.github.io/g3splat/).
TANGO: Traversability-Aware Navigation with Local Metric Control for Topological Goals
Sep 10, 2025Visual navigation in robotics traditionally relies on globally-consistent 3D maps or learned controllers, which can be computationally expensive and difficult to generalize across diverse environments. In this work, we present a novel RGB-only, object-level topometric navigation pipeline that enables zero-shot, long-horizon robot navigation without requiring 3D maps or pre-trained controllers. Our approach integrates global topological path planning with local metric trajectory control, allowing the robot to navigate towards object-level sub-goals while avoiding obstacles. We address key limitations of previous methods by continuously predicting local trajectory using monocular depth and traversability estimation, and incorporating an auto-switching mechanism that falls back to a baseline controller when necessary. The system operates using foundational models, ensuring open-set applicability without the need for domain-specific fine-tuning. We demonstrate the effectiveness of our method in both simulated environments and real-world tests, highlighting its robustness and deployability. Our approach outperforms existing state-of-the-art methods, offering a more adaptable and effective solution for visual navigation in open-set environments. The source code is made publicly available: https://github.com/podgorki/TANGO.
A Guaranteed-Stable Neural Network Approach for Optimal Control of Nonlinear Systems
Jan 28, 2025



A promising approach to optimal control of nonlinear systems involves iteratively linearizing the system and solving an optimization problem at each time instant to determine the optimal control input. Since this approach relies on online optimization, it can be computationally expensive, and thus unrealistic for systems with limited computing resources. One potential solution to this issue is to incorporate a Neural Network (NN) into the control loop to emulate the behavior of the optimal control scheme. Ensuring stability and reference tracking in the resulting NN-based closed-loop system requires modifications to the primary optimization problem. These modifications often introduce non-convexity and nonlinearity with respect to the decision variables, which may surpass the capabilities of existing solvers and complicate the generation of the training dataset. To address this issue, this paper develops a Neural Optimization Machine (NOM) to solve the resulting optimization problems. The central concept of a NOM is to transform the optimization challenges into the problem of training a NN. Rigorous proofs demonstrate that when a NN trained on data generated by the NOM is used in the control loop, all signals remain bounded and the system states asymptotically converge to a neighborhood around the desired equilibrium point, with a tunable proximity threshold. Simulation and experimental studies are provided to illustrate the effectiveness of the proposed methodology.
BEVPose: Unveiling Scene Semantics through Pose-Guided Multi-Modal BEV Alignment
Oct 28, 2024


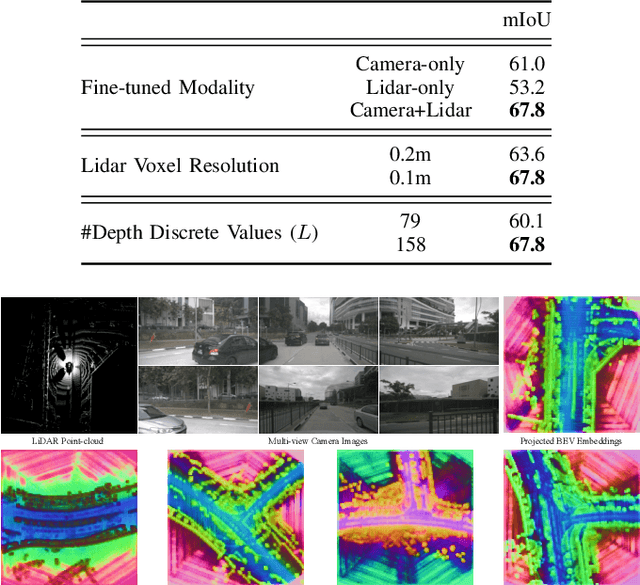
In the field of autonomous driving and mobile robotics, there has been a significant shift in the methods used to create Bird's Eye View (BEV) representations. This shift is characterised by using transformers and learning to fuse measurements from disparate vision sensors, mainly lidar and cameras, into a 2D planar ground-based representation. However, these learning-based methods for creating such maps often rely heavily on extensive annotated data, presenting notable challenges, particularly in diverse or non-urban environments where large-scale datasets are scarce. In this work, we present BEVPose, a framework that integrates BEV representations from camera and lidar data, using sensor pose as a guiding supervisory signal. This method notably reduces the dependence on costly annotated data. By leveraging pose information, we align and fuse multi-modal sensory inputs, facilitating the learning of latent BEV embeddings that capture both geometric and semantic aspects of the environment. Our pretraining approach demonstrates promising performance in BEV map segmentation tasks, outperforming fully-supervised state-of-the-art methods, while necessitating only a minimal amount of annotated data. This development not only confronts the challenge of data efficiency in BEV representation learning but also broadens the potential for such techniques in a variety of domains, including off-road and indoor environments.
Enhanced Classification of Heart Sounds Using Mel Frequency Cepstral Coefficients: A Comparative Study of Single and Ensemble Classifier Strategies
Jun 02, 2024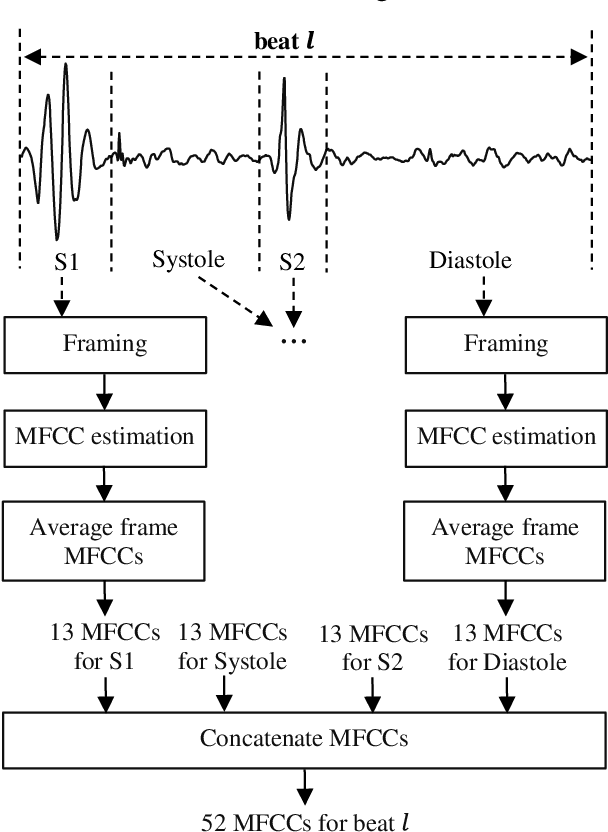
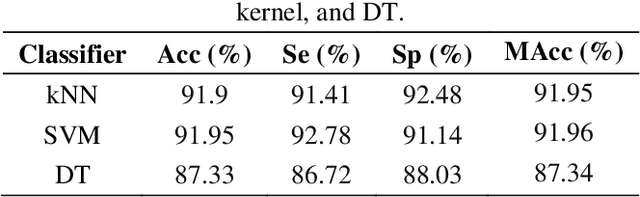
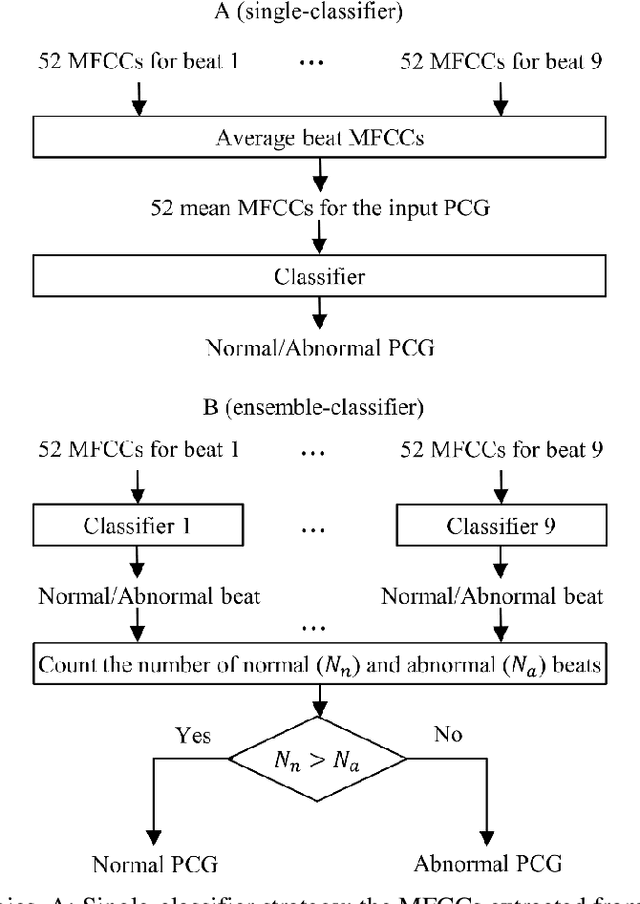
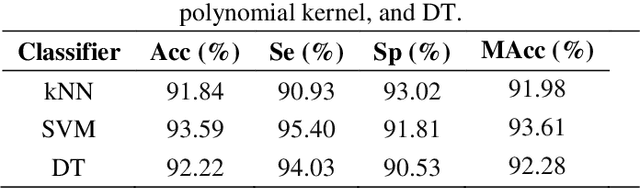
This paper explores the efficacy of Mel Frequency Cepstral Coefficients (MFCCs) in detecting abnormal phonocardiograms using two classification strategies: a single-classifier and an ensemble-classifier approach. Phonocardiograms were segmented into S1, systole, S2, and diastole intervals, with thirteen MFCCs estimated from each segment, yielding 52 MFCCs per beat. In the single-classifier strategy, the MFCCs from nine consecutive beats were averaged to classify phonocardiograms. Conversely, the ensemble-classifier strategy employed nine classifiers to individually assess beats as normal or abnormal, with the overall classification based on the majority vote. Both methods were tested on a publicly available phonocardiogram database. Results demonstrated that the ensemble-classifier strategy achieved higher accuracy compared to the single-classifier approach, establishing MFCCs as more effective than other features, including time, time-frequency, and statistical features, evaluated in similar studies.
RoboHop: Segment-based Topological Map Representation for Open-World Visual Navigation
May 09, 2024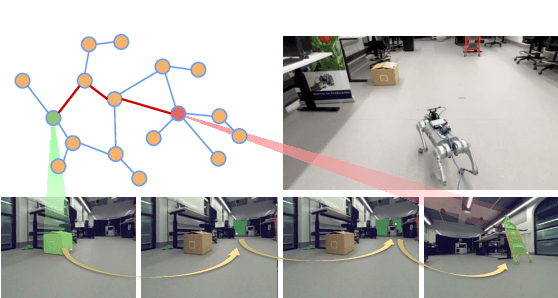
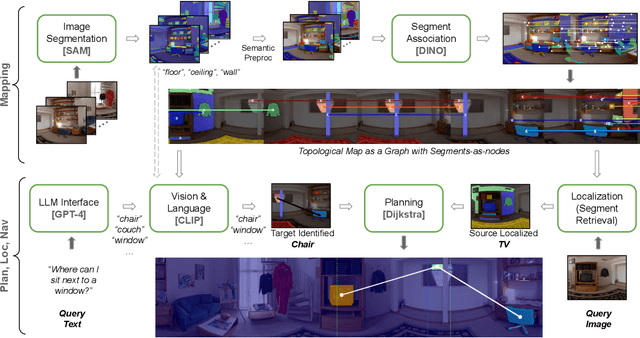
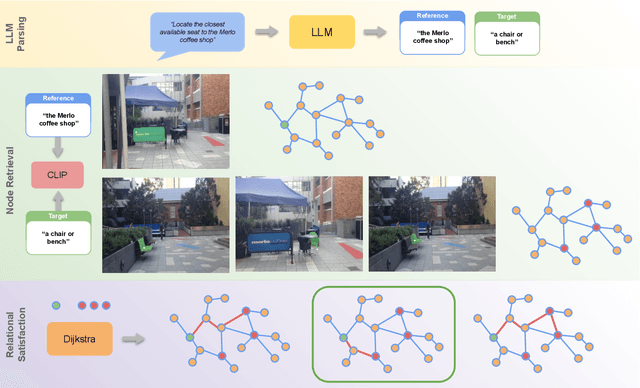

Mapping is crucial for spatial reasoning, planning and robot navigation. Existing approaches range from metric, which require precise geometry-based optimization, to purely topological, where image-as-node based graphs lack explicit object-level reasoning and interconnectivity. In this paper, we propose a novel topological representation of an environment based on "image segments", which are semantically meaningful and open-vocabulary queryable, conferring several advantages over previous works based on pixel-level features. Unlike 3D scene graphs, we create a purely topological graph with segments as nodes, where edges are formed by a) associating segment-level descriptors between pairs of consecutive images and b) connecting neighboring segments within an image using their pixel centroids. This unveils a "continuous sense of a place", defined by inter-image persistence of segments along with their intra-image neighbours. It further enables us to represent and update segment-level descriptors through neighborhood aggregation using graph convolution layers, which improves robot localization based on segment-level retrieval. Using real-world data, we show how our proposed map representation can be used to i) generate navigation plans in the form of "hops over segments" and ii) search for target objects using natural language queries describing spatial relations of objects. Furthermore, we quantitatively analyze data association at the segment level, which underpins inter-image connectivity during mapping and segment-level localization when revisiting the same place. Finally, we show preliminary trials on segment-level `hopping' based zero-shot real-world navigation. Project page with supplementary details: oravus.github.io/RoboHop/
Closed-Loop Model Identification and MPC-based Navigation of Quadcopters: A Case Study of Parrot Bebop 2
Apr 10, 2024



The growing potential of quadcopters in various domains, such as aerial photography, search and rescue, and infrastructure inspection, underscores the need for real-time control under strict safety and operational constraints. This challenge is compounded by the inherent nonlinear dynamics of quadcopters and the on-board computational limitations they face. This paper aims at addressing these challenges. First, this paper presents a comprehensive procedure for deriving a linear yet efficient model to describe the dynamics of quadrotors, thereby reducing complexity without compromising efficiency. Then, this paper develops a steady-state-aware Model Predictive Control (MPC) to effectively navigate quadcopters, while guaranteeing constraint satisfaction at all times. The main advantage of the steady-state-aware MPC is its low computational complexity, which makes it an appropriate choice for systems with limited computing capacity, like quadcopters. This paper considers Parrot Bebop 2 as the running example, and experimentally validates and evaluates the proposed algorithms.
Stochastic Multi-armed Bandits with Non-stationary Rewards Generated by a Linear Dynamical System
Apr 06, 2022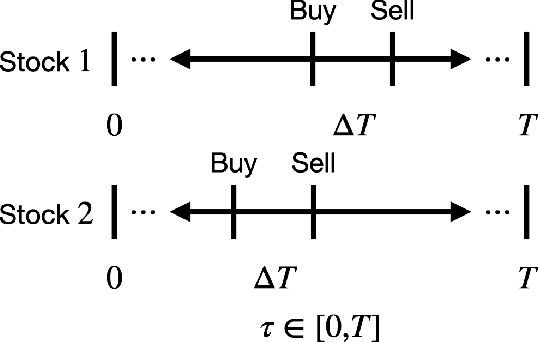
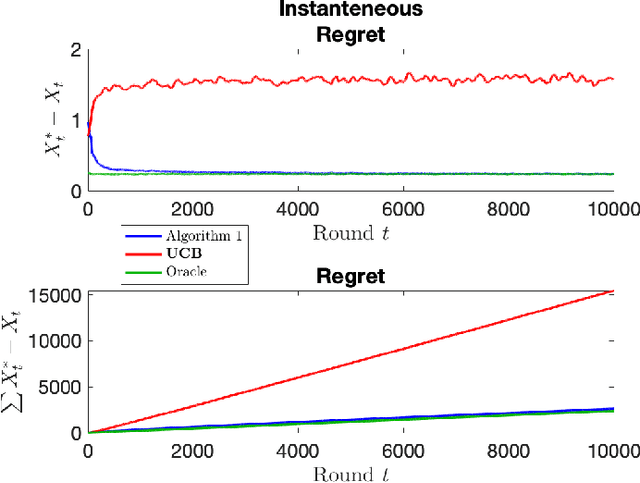
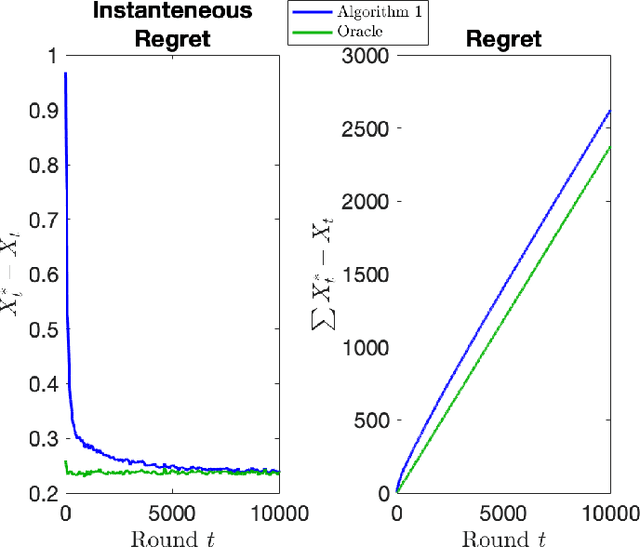
The stochastic multi-armed bandit has provided a framework for studying decision-making in unknown environments. We propose a variant of the stochastic multi-armed bandit where the rewards are sampled from a stochastic linear dynamical system. The proposed strategy for this stochastic multi-armed bandit variant is to learn a model of the dynamical system while choosing the optimal action based on the learned model. Motivated by mathematical finance areas such as Intertemporal Capital Asset Pricing Model proposed by Merton and Stochastic Portfolio Theory proposed by Fernholz that both model asset returns with stochastic differential equations, this strategy is applied to quantitative finance as a high-frequency trading strategy, where the goal is to maximize returns within a time period.
Toward Safe and Efficient Human-Robot Interaction via Behavior-Driven Danger Signaling
Feb 11, 2021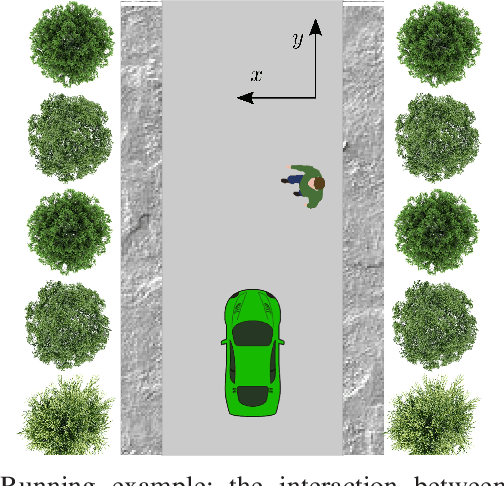
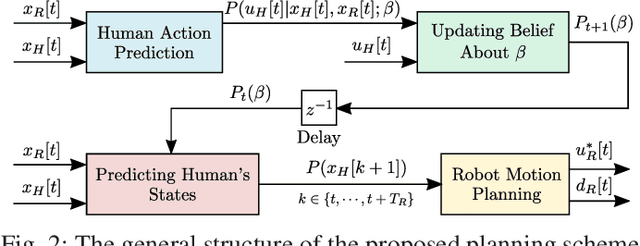
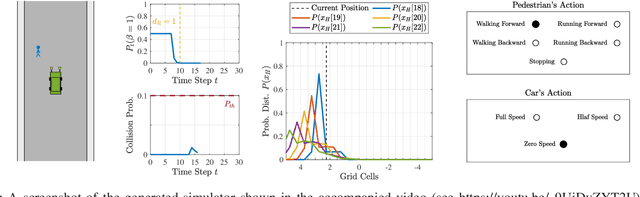
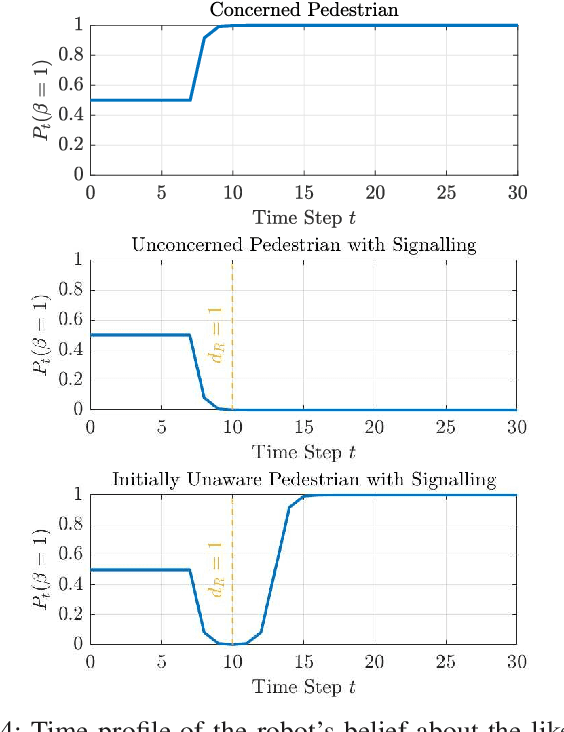
This paper introduces the notion of danger awareness in the context of Human-Robot Interaction (HRI), which decodes whether a human is aware of the existence of the robot, and illuminates whether the human is willing to engage in enforcing the safety. This paper also proposes a method to quantify this notion as a single binary variable, so-called danger awareness coefficient. By analyzing the effect of this coefficient on the human's actions, an online Bayesian learning method is proposed to update the belief about the value of the coefficient. It is shown that based upon the danger awareness coefficient and the proposed learning method, the robot can build a predictive human model to anticipate the human's future actions. In order to create a communication channel between the human and the robot, to enrich the observations and get informative data about the human, and to improve the efficiency of the robot, the robot is equipped with a danger signaling system. A predictive planning scheme, coupled with the predictive human model, is also proposed to provide an efficient and Probabilistically safe plan for the robot. The effectiveness of the proposed scheme is demonstrated through simulation studies on an interaction between a self-driving car and a pedestrian.
CovidCTNet: An Open-Source Deep Learning Approach to Identify Covid-19 Using CT Image
May 16, 2020Coronavirus disease 2019 (Covid-19) is highly contagious with limited treatment options. Early and accurate diagnosis of Covid-19 is crucial in reducing the spread of the disease and its accompanied mortality. Currently, detection by reverse transcriptase polymerase chain reaction (RT-PCR) is the gold standard of outpatient and inpatient detection of Covid-19. RT-PCR is a rapid method, however, its accuracy in detection is only ~70-75%. Another approved strategy is computed tomography (CT) imaging. CT imaging has a much higher sensitivity of ~80-98%, but similar accuracy of 70%. To enhance the accuracy of CT imaging detection, we developed an open-source set of algorithms called CovidCTNet that successfully differentiates Covid-19 from community-acquired pneumonia (CAP) and other lung diseases. CovidCTNet increases the accuracy of CT imaging detection to 90% compared to radiologists (70%). The model is designed to work with heterogeneous and small sample sizes independent of the CT imaging hardware. In order to facilitate the detection of Covid-19 globally and assist radiologists and physicians in the screening process, we are releasing all algorithms and parametric details in an open-source format. Open-source sharing of our CovidCTNet enables developers to rapidly improve and optimize services, while preserving user privacy and data ownership.