 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Monocular Object-Model Aware Sparse SLAM
Paper and Code
Mar 06, 2019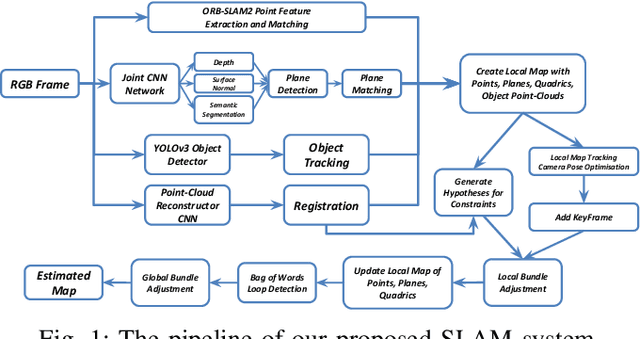
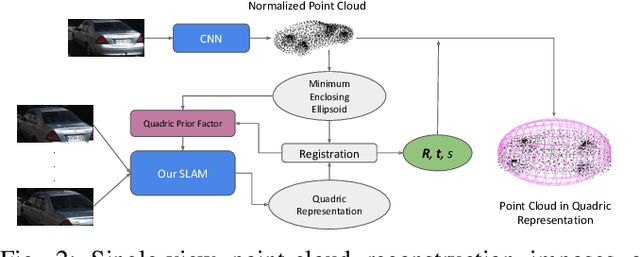
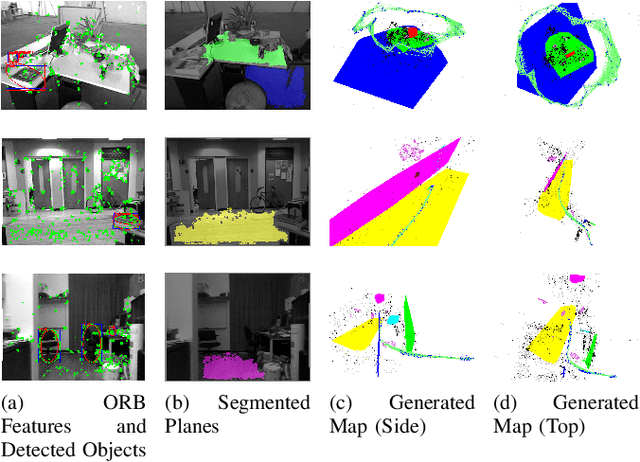
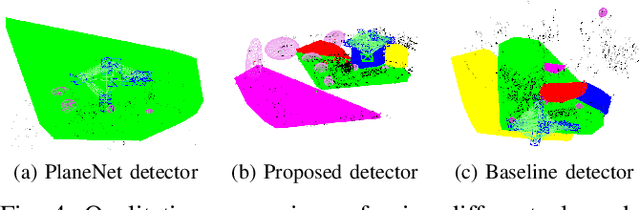
Simultaneous Localization And Mapping (SLAM) is a fundamental problem in mobile robotics. While sparse point-based SLAM methods provide accurate camera localization, the generated maps lack semantic information. On the other hand, state of the art object detection methods provide rich information about entities present in the scene from a single image. This work incorporates a real-time deep-learned object detector to the monocular SLAM framework for representing generic objects as quadrics that permit detections to be seamlessly integrated while allowing the real-time performance. Finer reconstruction of an object, learned by a CNN network, is also incorporated and provides a shape prior for the quadric leading further refinement. To capture the dominant structure of the scene, additional planar landmarks are detected by a CNN-based plane detector and modeled as independent landmarks in the map. Extensive experiments support our proposed inclusion of semantic objects and planar structures directly in the bundle-adjustment of SLAM - Semantic SLAM - that enriches the reconstructed map semantically, while significantly improving the camera localization. The performance of our SLAM system is demonstrated in https://youtu.be/UMWXd4sHONw and https://youtu.be/QPQqVrvP0dE .