 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing YOLO v7 to Detect Kidney in Magnetic Resonance Imaging
Feb 12, 2024Introduction This study explores the use of the latest You Only Look Once (YOLO V7) object detection method to enhance kidney detection in medical imaging by training and testing a modified YOLO V7 on medical image formats. Methods Study includes 878 patients with various subtypes of renal cell carcinoma (RCC) and 206 patients with normal kidneys. A total of 5657 MRI scans for 1084 patients were retrieved. 326 patients with 1034 tumors recruited from a retrospective maintained database, and bounding boxes were drawn around their tumors. A primary model was trained on 80% of annotated cases, with 20% saved for testing (primary test set). The best primary model was then used to identify tumors in the remaining 861 patients and bounding box coordinates were generated on their scans using the model. Ten benchmark training sets were created with generated coordinates on not-segmented patients. The final model used to predict the kidney in the primary test set. We reported the positive predictive value (PPV), sensitivity, and mean average precision (mAP). Results The primary training set showed an average PPV of 0.94 +/- 0.01, sensitivity of 0.87 +/- 0.04, and mAP of 0.91 +/- 0.02. The best primary model yielded a PPV of 0.97, sensitivity of 0.92, and mAP of 0.95. The final model demonstrated an average PPV of 0.95 +/- 0.03, sensitivity of 0.98 +/- 0.004, and mAP of 0.95 +/- 0.01. Conclusion Using a semi-supervised approach with a medical image library, we developed a high-performing model for kidney detection. Further external validation is required to assess the model's generalizability.
Deep Learning Predicts Cardiovascular Disease Risks from Lung Cancer Screening Low Dose Computed Tomography
Aug 16, 2020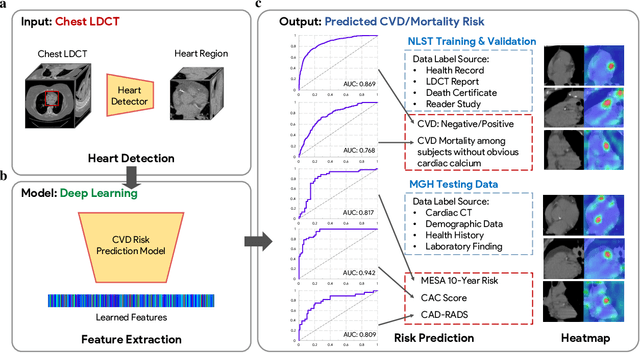

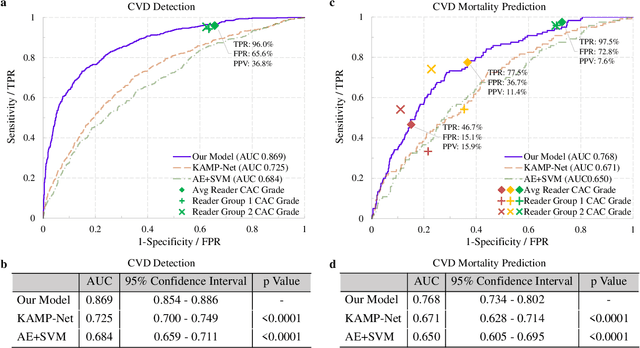

The high risk population of cardiovascular disease (CVD) is simultaneously at high risk of lung cancer. Given the dominance of low dose computed tomography (LDCT) for lung cancer screening, the feasibility of extracting information on CVD from the same LDCT scan would add major value to patients at no additional radiation dose. However, with strong noise in LDCT images and without electrocardiogram (ECG) gating, CVD risk analysis from LDCT is highly challenging. Here we present an innovative deep learning model to address this challenge. Our deep model was trained with 30,286 LDCT volumes and achieved the state-of-the-art performance (area under the curve (AUC) of 0.869) on 2,085 National Lung Cancer Screening Trial (NLST) subjects, and effectively identified patients with high CVD mortality risks (AUC of 0.768). Our deep model was further calibrated against the clinical gold standard CVD risk scores from ECG-gated dedicated cardiac CT, including coronary artery calcification (CAC) score, CAD-RADS score and MESA 10-year CHD risk score from an independent dataset of 106 subjects. In this validation study, our model achieved AUC of 0.942, 0.809 and 0.817 for CAC, CAD-RADS and MESA scores, respectively. Our deep learning model has the potential to convert LDCT for lung cancer screening into dual-screening quantitative tool for CVD risk estimation.
Integrative Analysis for COVID-19 Patient Outcome Prediction
Jul 20, 2020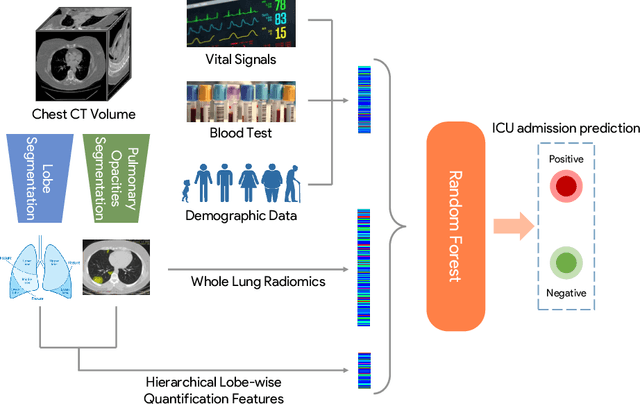
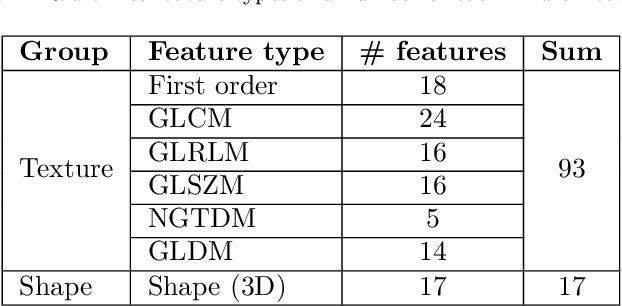
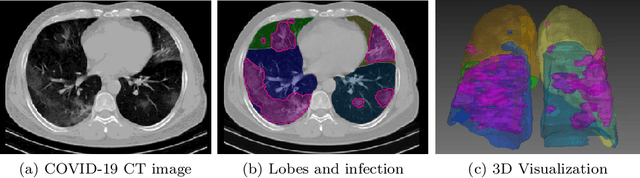
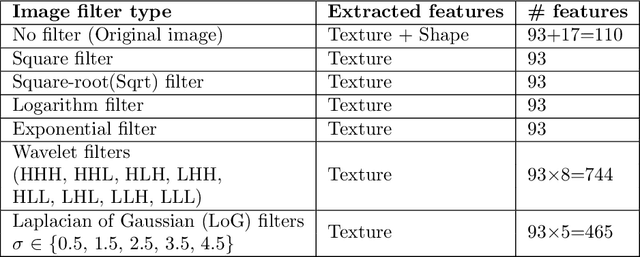
While image analysis of chest computed tomography (CT) for COVID-19 diagnosis has been intensively studied, little work has been performed for image-based patient outcome prediction. Management of high-risk patients with early intervention is a key to lower the fatality rate of COVID-19 pneumonia, as a majority of patients recover naturally. Therefore, an accurate prediction of disease progression with baseline imaging at the time of the initial presentation can help in patient management. In lieu of only size and volume information of pulmonary abnormalities and features through deep learning based image segmentation, here we combine radiomics of lung opacities and non-imaging features from demographic data, vital signs, and laboratory findings to predict need for intensive care unit (ICU) admission. To our knowledge, this is the first study that uses holistic information of a patient including both imaging and non-imaging data for outcome prediction. The proposed methods were thoroughly evaluated on datasets separately collected from three hospitals, one in the United States, one in Iran, and another in Italy, with a total 295 patients with reverse transcription polymerase chain reaction (RT-PCR) assay positive COVID-19 pneumonia. Our experimental results demonstrate that adding non-imaging features can significantly improve the performance of prediction to achieve AUC up to 0.884 and sensitivity as high as 96.1%, which can be valuable to provide clinical decision support in managing COVID-19 patients. Our methods may also be applied to other lung diseases including but not limited to community acquired pneumonia.
CovidCTNet: An Open-Source Deep Learning Approach to Identify Covid-19 Using CT Image
May 16, 2020Coronavirus disease 2019 (Covid-19) is highly contagious with limited treatment options. Early and accurate diagnosis of Covid-19 is crucial in reducing the spread of the disease and its accompanied mortality. Currently, detection by reverse transcriptase polymerase chain reaction (RT-PCR) is the gold standard of outpatient and inpatient detection of Covid-19. RT-PCR is a rapid method, however, its accuracy in detection is only ~70-75%. Another approved strategy is computed tomography (CT) imaging. CT imaging has a much higher sensitivity of ~80-98%, but similar accuracy of 70%. To enhance the accuracy of CT imaging detection, we developed an open-source set of algorithms called CovidCTNet that successfully differentiates Covid-19 from community-acquired pneumonia (CAP) and other lung diseases. CovidCTNet increases the accuracy of CT imaging detection to 90% compared to radiologists (70%). The model is designed to work with heterogeneous and small sample sizes independent of the CT imaging hardware. In order to facilitate the detection of Covid-19 globally and assist radiologists and physicians in the screening process, we are releasing all algorithms and parametric details in an open-source format. Open-source sharing of our CovidCTNet enables developers to rapidly improve and optimize services, while preserving user privacy and data ownership.
Can Deep Learning Outperform Modern Commercial CT Image Reconstruction Methods?
Nov 08, 2018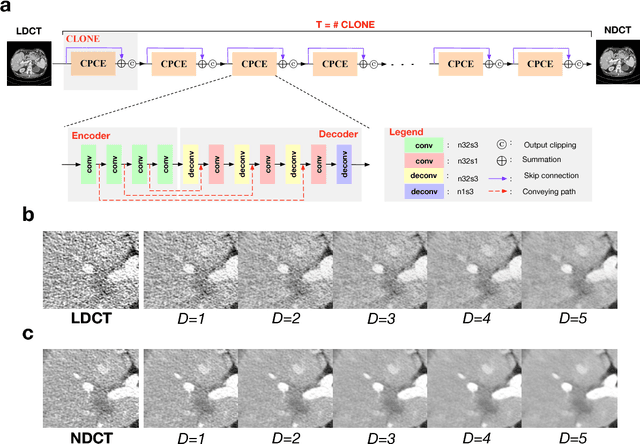
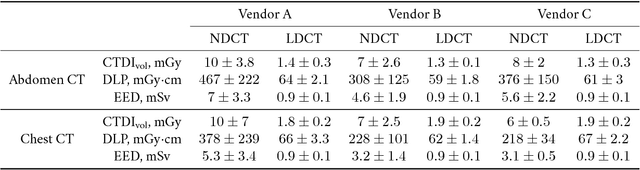

Commercial iterative reconstruction techniques on modern CT scanners target radiation dose reduction but there are lingering concerns over their impact on image appearance and low contrast detectability. Recently, machine learning, especially deep learning, has been actively investigated for CT. Here we design a novel neural network architecture for low-dose CT (LDCT) and compare it with commercial iterative reconstruction methods used for standard of care CT. While popular neural networks are trained for end-to-end mapping, driven by big data, our novel neural network is intended for end-to-process mapping so that intermediate image targets are obtained with the associated search gradients along which the final image targets are gradually reached. This learned dynamic process allows to include radiologists in the training loop to optimize the LDCT denoising workflow in a task-specific fashion with the denoising depth as a key parameter. Our progressive denoising network was trained with the Mayo LDCT Challenge Dataset, and tested on images of the chest and abdominal regions scanned on the CT scanners made by three leading CT vendors. The best deep learning based reconstructions are systematically compared to the best iterative reconstructions in a double-blinded reader study. It is found that our deep learning approach performs either comparably or favorably in terms of noise suppression and structural fidelity, and runs orders of magnitude faster than the commercial iterative CT reconstruction algorithms.