 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation-based Radiology Report-Guided Semi-supervised Learning for Prostate Cancer Detection
Jun 18, 2024Prostate cancer is one of the most prevalent malignancies in the world. While deep learning has potential to further improve computer-aided prostate cancer detection on MRI, its efficacy hinges on the exhaustive curation of manually annotated images. We propose a novel methodology of semisupervised learning (SSL) guided by automatically extracted clinical information, specifically the lesion locations in radiology reports, allowing for use of unannotated images to reduce the annotation burden. By leveraging lesion locations, we refined pseudo labels, which were then used to train our location-based SSL model. We show that our SSL method can improve prostate lesion detection by utilizing unannotated images, with more substantial impacts being observed when larger proportions of unannotated images are used.
Using YOLO v7 to Detect Kidney in Magnetic Resonance Imaging
Feb 12, 2024Introduction This study explores the use of the latest You Only Look Once (YOLO V7) object detection method to enhance kidney detection in medical imaging by training and testing a modified YOLO V7 on medical image formats. Methods Study includes 878 patients with various subtypes of renal cell carcinoma (RCC) and 206 patients with normal kidneys. A total of 5657 MRI scans for 1084 patients were retrieved. 326 patients with 1034 tumors recruited from a retrospective maintained database, and bounding boxes were drawn around their tumors. A primary model was trained on 80% of annotated cases, with 20% saved for testing (primary test set). The best primary model was then used to identify tumors in the remaining 861 patients and bounding box coordinates were generated on their scans using the model. Ten benchmark training sets were created with generated coordinates on not-segmented patients. The final model used to predict the kidney in the primary test set. We reported the positive predictive value (PPV), sensitivity, and mean average precision (mAP). Results The primary training set showed an average PPV of 0.94 +/- 0.01, sensitivity of 0.87 +/- 0.04, and mAP of 0.91 +/- 0.02. The best primary model yielded a PPV of 0.97, sensitivity of 0.92, and mAP of 0.95. The final model demonstrated an average PPV of 0.95 +/- 0.03, sensitivity of 0.98 +/- 0.004, and mAP of 0.95 +/- 0.01. Conclusion Using a semi-supervised approach with a medical image library, we developed a high-performing model for kidney detection. Further external validation is required to assess the model's generalizability.
Random Hinge Forest for Differentiable Learning
Mar 01, 2018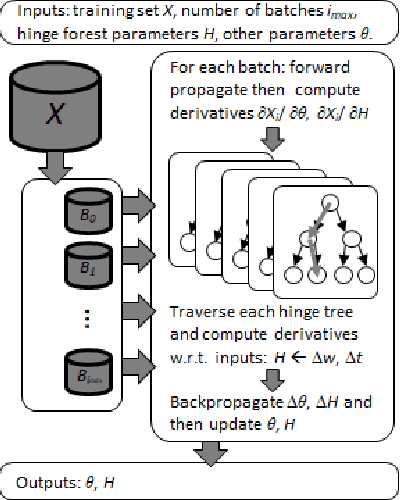
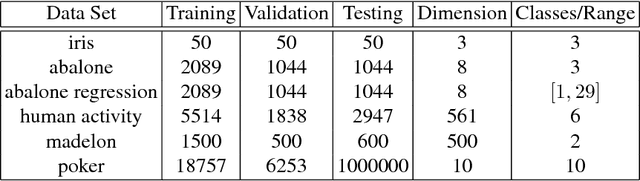
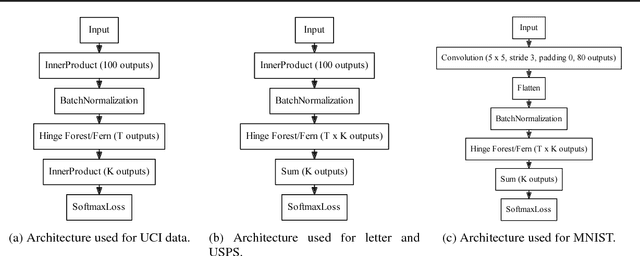
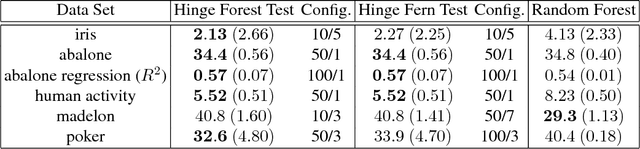
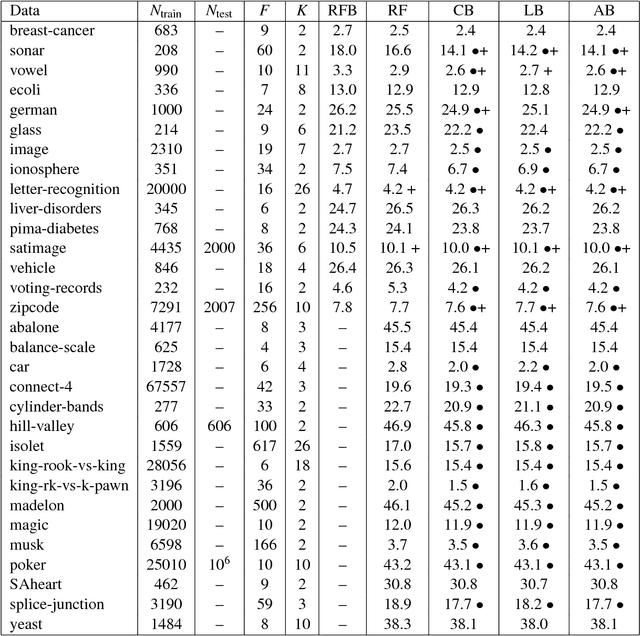
We propose random hinge forests, a simple, efficient, and novel variant of decision forests. Importantly, random hinge forests can be readily incorporated as a general component within arbitrary computation graphs that are optimized end-to-end with stochastic gradient descent or variants thereof. We derive random hinge forest and ferns, focusing on their sparse and efficient nature, their min-max margin property, strategies to initialize them for arbitrary network architectures, and the class of optimizers most suitable for optimizing random hinge forest. The performance and versatility of random hinge forests are demonstrated by experiments incorporating a variety of of small and large UCI machine learning data sets and also ones involving the MNIST, Letter, and USPS image datasets. We compare random hinge forests with random forests and the more recent backpropagating deep neural decision forests.
Spatial Aggregation of Holistically-Nested Convolutional Neural Networks for Automated Pancreas Localization and Segmentation
Jan 31, 2017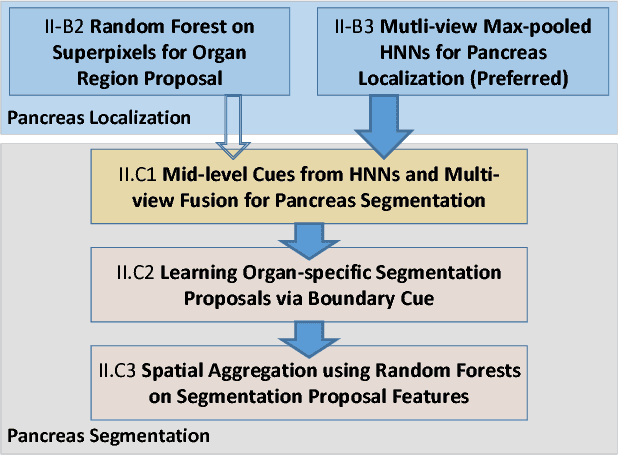
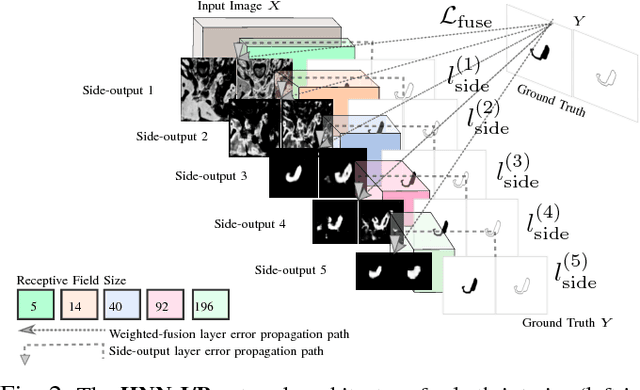
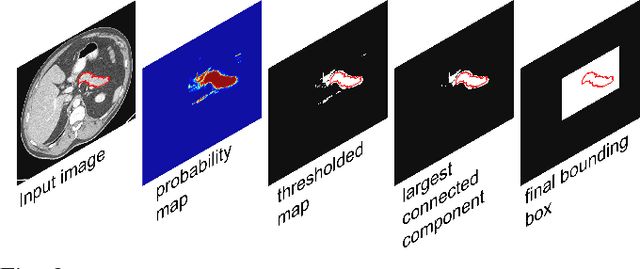
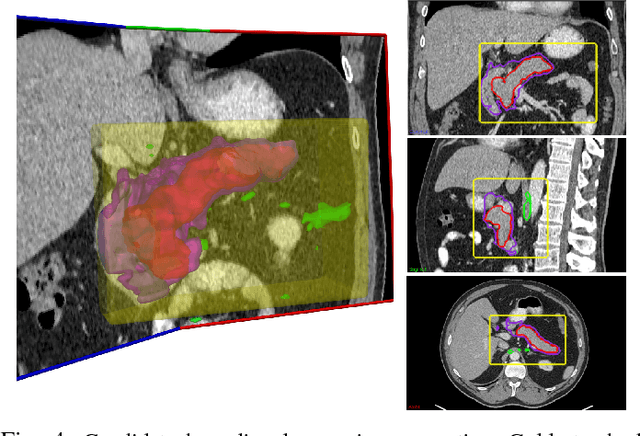
Accurate and automatic organ segmentation from 3D radiological scans is an important yet challenging problem for medical image analysis. Specifically, the pancreas demonstrates very high inter-patient anatomical variability in both its shape and volume. In this paper, we present an automated system using 3D computed tomography (CT) volumes via a two-stage cascaded approach: pancreas localization and segmentation. For the first step, we localize the pancreas from the entire 3D CT scan, providing a reliable bounding box for the more refined segmentation step. We introduce a fully deep-learning approach, based on an efficient application of holistically-nested convolutional networks (HNNs) on the three orthogonal axial, sagittal, and coronal views. The resulting HNN per-pixel probability maps are then fused using pooling to reliably produce a 3D bounding box of the pancreas that maximizes the recall. We show that our introduced localizer compares favorably to both a conventional non-deep-learning method and a recent hybrid approach based on spatial aggregation of superpixels using random forest classification. The second, segmentation, phase operates within the computed bounding box and integrates semantic mid-level cues of deeply-learned organ interior and boundary maps, obtained by two additional and separate realizations of HNNs. By integrating these two mid-level cues, our method is capable of generating boundary-preserving pixel-wise class label maps that result in the final pancreas segmentation. Quantitative evaluation is performed on a publicly available dataset of 82 patient CT scans using 4-fold cross-validation (CV). We achieve a Dice similarity coefficient (DSC) of 81.27+/-6.27% in validation, which significantly outperforms previous state-of-the art methods that report DSCs of 71.80+/-10.70% and 78.01+/-8.20%, respectively, using the same dataset.
Face Detection with a 3D Model
Nov 03, 2015



This paper presents a part-based face detection approach where the spatial relationship between the face parts is represented by a hidden 3D model with six parameters. The computational complexity of the search in the six dimensional pose space is addressed by proposing meaningful 3D pose candidates by image-based regression from detected face keypoint locations. The 3D pose candidates are evaluated using a parameter sensitive classifier based on difference features relative to the 3D pose. A compatible subset of candidates is then obtained by non-maximal suppression. Experiments on two standard face detection datasets show that the proposed 3D model based approach obtains results comparable to or better than state of the art.
* 14 pages, 11 figures
An Introduction to Artificial Prediction Markets for Classification
Jul 09, 2012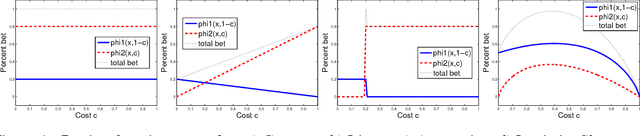


Prediction markets are used in real life to predict outcomes of interest such as presidential elections. This paper presents a mathematical theory of artificial prediction markets for supervised learning of conditional probability estimators. The artificial prediction market is a novel method for fusing the prediction information of features or trained classifiers, where the fusion result is the contract price on the possible outcomes. The market can be trained online by updating the participants' budgets using training examples. Inspired by the real prediction markets, the equations that govern the market are derived from simple and reasonable assumptions. Efficient numerical algorithms are presented for solving these equations. The obtained artificial prediction market is shown to be a maximum likelihood estimator. It generalizes linear aggregation, existent in boosting and random forest, as well as logistic regression and some kernel methods. Furthermore, the market mechanism allows the aggregation of specialized classifiers that participate only on specific instances. Experimental comparisons show that the artificial prediction markets often outperform random forest and implicit online learning on synthetic data and real UCI datasets. Moreover, an extensive evaluation for pelvic and abdominal lymph node detection in CT data shows that the prediction market improves adaboost's detection rate from 79.6% to 81.2% at 3 false positives/volume.
* 29 pages, 8 figures
The Artificial Regression Market
Apr 18, 2012

The Artificial Prediction Market is a recent machine learning technique for multi-class classification, inspired from the financial markets. It involves a number of trained market participants that bet on the possible outcomes and are rewarded if they predict correctly. This paper generalizes the scope of the Artificial Prediction Markets to regression, where there are uncountably many possible outcomes and the error is usually the MSE. For that, we introduce the reward kernel that rewards each participant based on its prediction error and we derive the price equations. Using two reward kernels we obtain two different learning rules, one of which is approximated using Hermite-Gauss quadrature. The market setting makes it easy to aggregate specialized regressors that only predict when an observation falls into their specialization domain. Experiments show that regression markets based on the two learning rules outperform Random Forest Regression on many UCI datasets and are rarely outperformed.