 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward the automated analysis of complex diseases in genome-wide association studies using genetic programming
Feb 06, 2017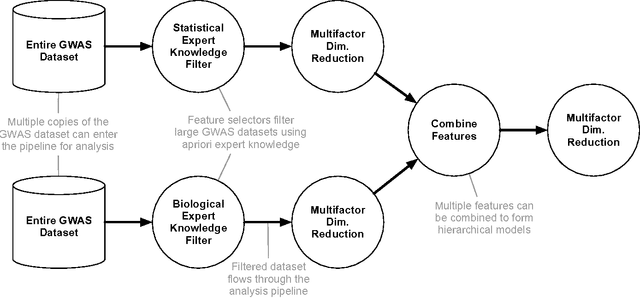
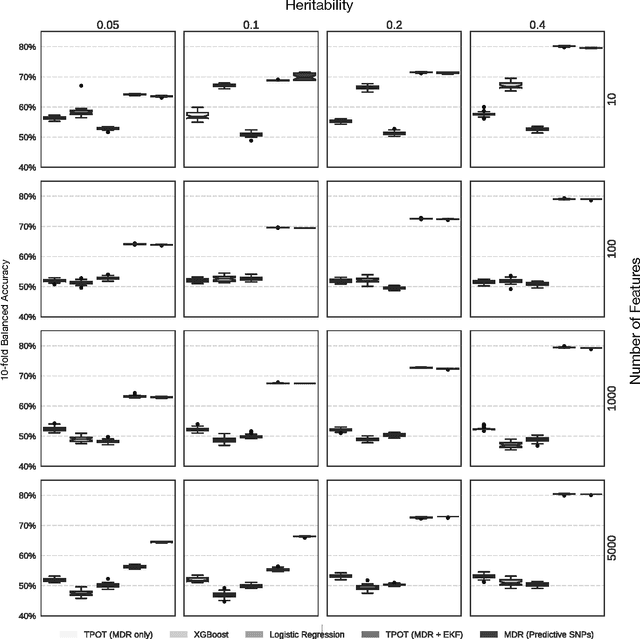
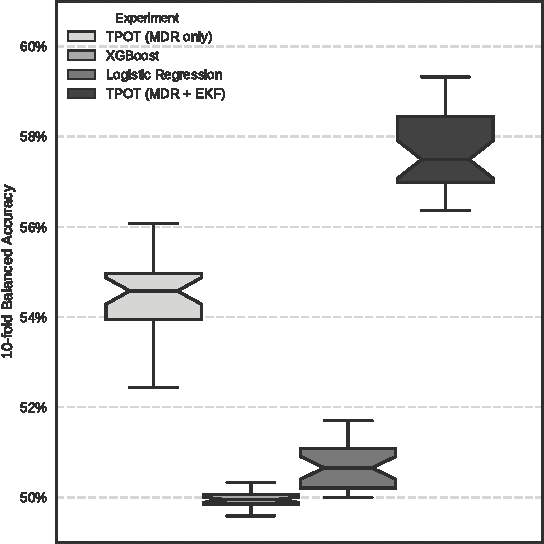
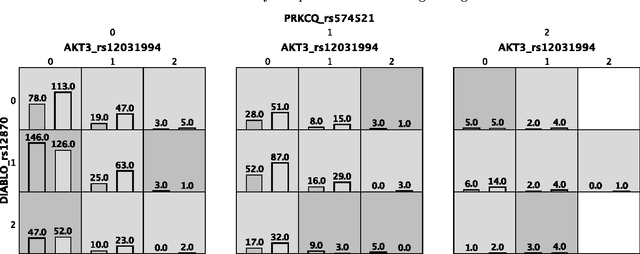
Machine learning has been gaining traction in recent years to meet the demand for tools that can efficiently analyze and make sense of the ever-growing databases of biomedical data in health care systems around the world. However, effectively using machine learning methods requires considerable domain expertise, which can be a barrier of entry for bioinformaticians new to computational data science methods. Therefore, off-the-shelf tools that make machine learning more accessible can prove invaluable for bioinformaticians. To this end, we have developed an open source pipeline optimization tool (TPOT-MDR) that uses genetic programming to automatically design machine learning pipelines for bioinformatics studies. In TPOT-MDR, we implement Multifactor Dimensionality Reduction (MDR) as a feature construction method for modeling higher-order feature interactions, and combine it with a new expert knowledge-guided feature selector for large biomedical data sets. We demonstrate TPOT-MDR's capabilities using a combination of simulated and real world data sets from human genetics and find that TPOT-MDR significantly outperforms modern machine learning methods such as logistic regression and eXtreme Gradient Boosting (XGBoost). We further analyze the best pipeline discovered by TPOT-MDR for a real world problem and highlight TPOT-MDR's ability to produce a high-accuracy solution that is also easily interpretable.
Spatial Aggregation of Holistically-Nested Convolutional Neural Networks for Automated Pancreas Localization and Segmentation
Jan 31, 2017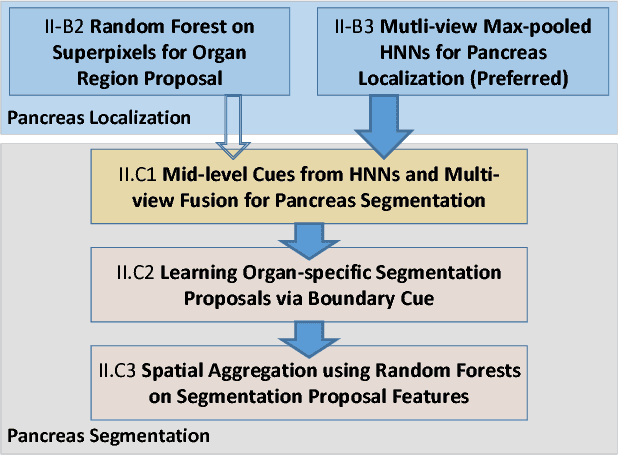
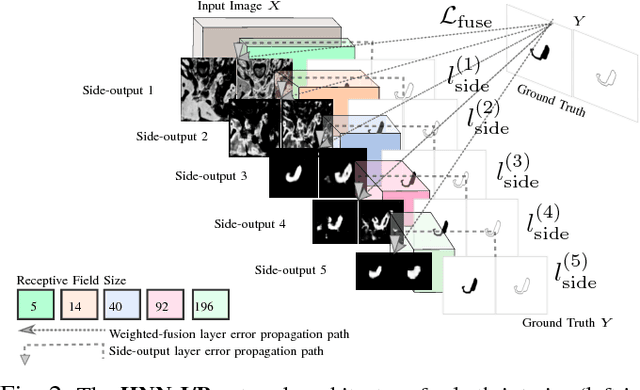
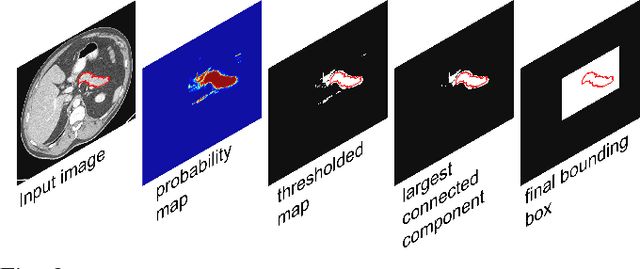
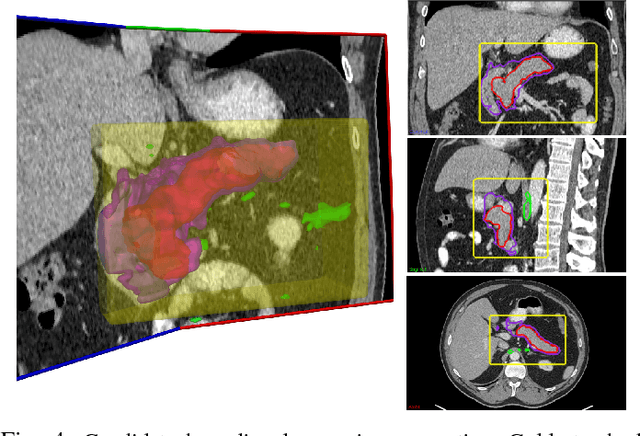
Accurate and automatic organ segmentation from 3D radiological scans is an important yet challenging problem for medical image analysis. Specifically, the pancreas demonstrates very high inter-patient anatomical variability in both its shape and volume. In this paper, we present an automated system using 3D computed tomography (CT) volumes via a two-stage cascaded approach: pancreas localization and segmentation. For the first step, we localize the pancreas from the entire 3D CT scan, providing a reliable bounding box for the more refined segmentation step. We introduce a fully deep-learning approach, based on an efficient application of holistically-nested convolutional networks (HNNs) on the three orthogonal axial, sagittal, and coronal views. The resulting HNN per-pixel probability maps are then fused using pooling to reliably produce a 3D bounding box of the pancreas that maximizes the recall. We show that our introduced localizer compares favorably to both a conventional non-deep-learning method and a recent hybrid approach based on spatial aggregation of superpixels using random forest classification. The second, segmentation, phase operates within the computed bounding box and integrates semantic mid-level cues of deeply-learned organ interior and boundary maps, obtained by two additional and separate realizations of HNNs. By integrating these two mid-level cues, our method is capable of generating boundary-preserving pixel-wise class label maps that result in the final pancreas segmentation. Quantitative evaluation is performed on a publicly available dataset of 82 patient CT scans using 4-fold cross-validation (CV). We achieve a Dice similarity coefficient (DSC) of 81.27+/-6.27% in validation, which significantly outperforms previous state-of-the art methods that report DSCs of 71.80+/-10.70% and 78.01+/-8.20%, respectively, using the same dataset.
Spatial Aggregation of Holistically-Nested Networks for Automated Pancreas Segmentation
Jun 24, 2016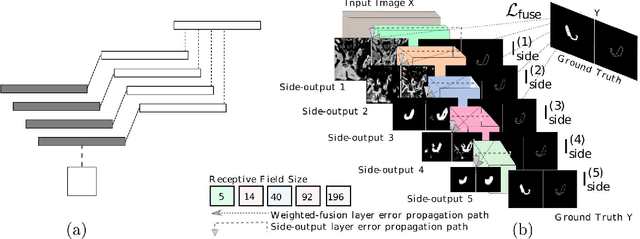
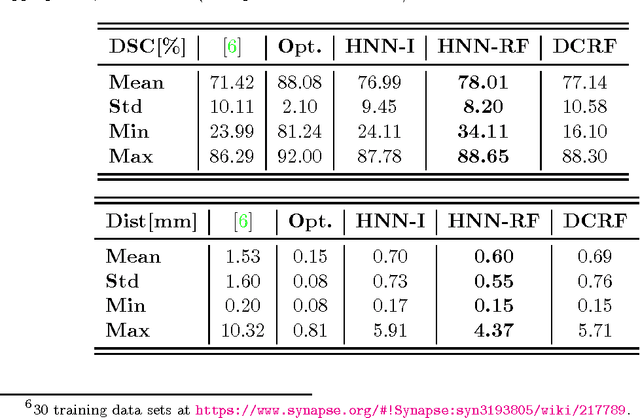
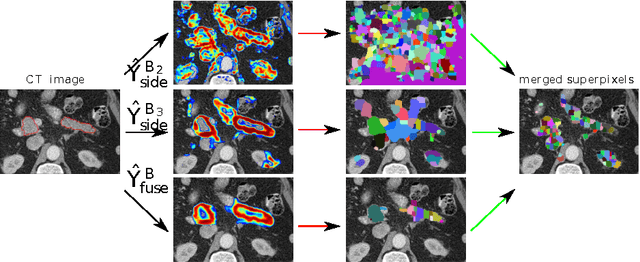

Accurate automatic organ segmentation is an important yet challenging problem for medical image analysis. The pancreas is an abdominal organ with very high anatomical variability. This inhibits traditional segmentation methods from achieving high accuracies, especially compared to other organs such as the liver, heart or kidneys. In this paper, we present a holistic learning approach that integrates semantic mid-level cues of deeply-learned organ interior and boundary maps via robust spatial aggregation using random forest. Our method generates boundary preserving pixel-wise class labels for pancreas segmentation. Quantitative evaluation is performed on CT scans of 82 patients in 4-fold cross-validation. We achieve a (mean $\pm$ std. dev.) Dice Similarity Coefficient of 78.01% $\pm$ 8.2% in testing which significantly outperforms the previous state-of-the-art approach of 71.8% $\pm$ 10.7% under the same evaluation criterion.