 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectReact: Learning Object-Relative Control for Visual Navigation
Sep 11, 2025Visual navigation using only a single camera and a topological map has recently become an appealing alternative to methods that require additional sensors and 3D maps. This is typically achieved through an "image-relative" approach to estimating control from a given pair of current observation and subgoal image. However, image-level representations of the world have limitations because images are strictly tied to the agent's pose and embodiment. In contrast, objects, being a property of the map, offer an embodiment- and trajectory-invariant world representation. In this work, we present a new paradigm of learning "object-relative" control that exhibits several desirable characteristics: a) new routes can be traversed without strictly requiring to imitate prior experience, b) the control prediction problem can be decoupled from solving the image matching problem, and c) high invariance can be achieved in cross-embodiment deployment for variations across both training-testing and mapping-execution settings. We propose a topometric map representation in the form of a "relative" 3D scene graph, which is used to obtain more informative object-level global path planning costs. We train a local controller, dubbed "ObjectReact", conditioned directly on a high-level "WayObject Costmap" representation that eliminates the need for an explicit RGB input. We demonstrate the advantages of learning object-relative control over its image-relative counterpart across sensor height variations and multiple navigation tasks that challenge the underlying spatial understanding capability, e.g., navigating a map trajectory in the reverse direction. We further show that our sim-only policy is able to generalize well to real-world indoor environments. Code and supplementary material are accessible via project page: https://object-react.github.io/
TANGO: Traversability-Aware Navigation with Local Metric Control for Topological Goals
Sep 10, 2025Visual navigation in robotics traditionally relies on globally-consistent 3D maps or learned controllers, which can be computationally expensive and difficult to generalize across diverse environments. In this work, we present a novel RGB-only, object-level topometric navigation pipeline that enables zero-shot, long-horizon robot navigation without requiring 3D maps or pre-trained controllers. Our approach integrates global topological path planning with local metric trajectory control, allowing the robot to navigate towards object-level sub-goals while avoiding obstacles. We address key limitations of previous methods by continuously predicting local trajectory using monocular depth and traversability estimation, and incorporating an auto-switching mechanism that falls back to a baseline controller when necessary. The system operates using foundational models, ensuring open-set applicability without the need for domain-specific fine-tuning. We demonstrate the effectiveness of our method in both simulated environments and real-world tests, highlighting its robustness and deployability. Our approach outperforms existing state-of-the-art methods, offering a more adaptable and effective solution for visual navigation in open-set environments. The source code is made publicly available: https://github.com/podgorki/TANGO.
Learn 2 Rage: Experiencing The Emotional Roller Coaster That Is Reinforcement Learning
Oct 24, 2024



This work presents the experiments and solution outline for our teams winning submission in the Learn To Race Autonomous Racing Virtual Challenge 2022 hosted by AIcrowd. The objective of the Learn-to-Race competition is to push the boundary of autonomous technology, with a focus on achieving the safety benefits of autonomous driving. In the description the competition is framed as a reinforcement learning (RL) challenge. We focused our initial efforts on implementation of Soft Actor Critic (SAC) variants. Our goal was to learn non-trivial control of the race car exclusively from visual and geometric features, directly mapping pixels to control actions. We made suitable modifications to the default reward policy aiming to promote smooth steering and acceleration control. The framework for the competition provided real time simulation, meaning a single episode (learning experience) is measured in minutes. Instead of pursuing parallelisation of episodes we opted to explore a more traditional approach in which the visual perception was processed (via learned operators) and fed into rule-based controllers. Such a system, while not as academically "attractive" as a pixels-to-actions approach, results in a system that requires less training, is more explainable, generalises better and is easily tuned and ultimately out-performed all other agents in the competition by a large margin.
RoboHop: Segment-based Topological Map Representation for Open-World Visual Navigation
May 09, 2024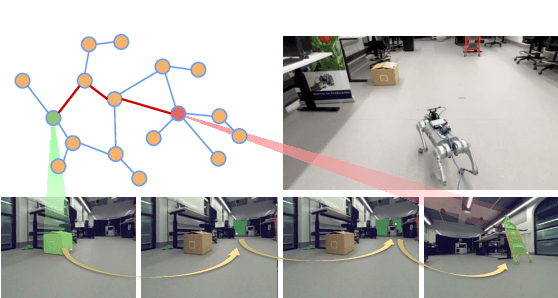
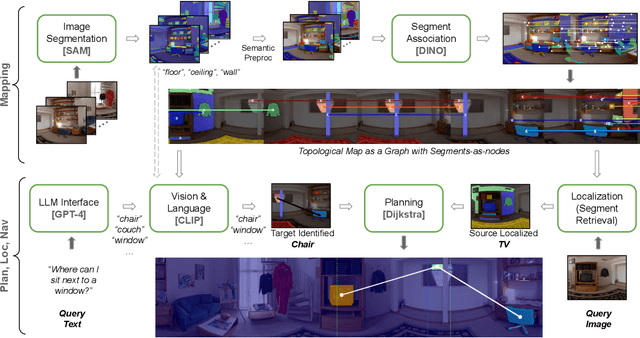
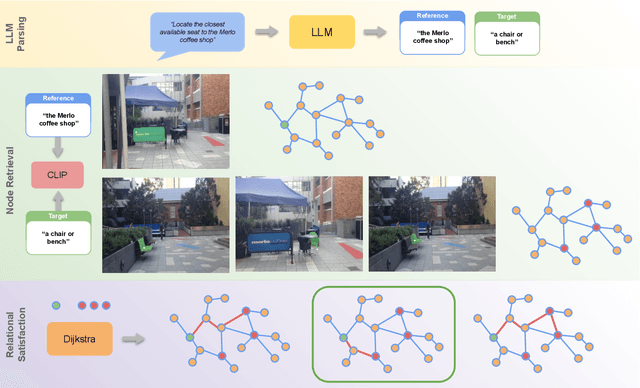

Mapping is crucial for spatial reasoning, planning and robot navigation. Existing approaches range from metric, which require precise geometry-based optimization, to purely topological, where image-as-node based graphs lack explicit object-level reasoning and interconnectivity. In this paper, we propose a novel topological representation of an environment based on "image segments", which are semantically meaningful and open-vocabulary queryable, conferring several advantages over previous works based on pixel-level features. Unlike 3D scene graphs, we create a purely topological graph with segments as nodes, where edges are formed by a) associating segment-level descriptors between pairs of consecutive images and b) connecting neighboring segments within an image using their pixel centroids. This unveils a "continuous sense of a place", defined by inter-image persistence of segments along with their intra-image neighbours. It further enables us to represent and update segment-level descriptors through neighborhood aggregation using graph convolution layers, which improves robot localization based on segment-level retrieval. Using real-world data, we show how our proposed map representation can be used to i) generate navigation plans in the form of "hops over segments" and ii) search for target objects using natural language queries describing spatial relations of objects. Furthermore, we quantitatively analyze data association at the segment level, which underpins inter-image connectivity during mapping and segment-level localization when revisiting the same place. Finally, we show preliminary trials on segment-level `hopping' based zero-shot real-world navigation. Project page with supplementary details: oravus.github.io/RoboHop/