 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARBLE: Multi-Armed Restless Bandits in Latent Markovian Environment
Nov 12, 2025Restless Multi-Armed Bandits (RMABs) are powerful models for decision-making under uncertainty, yet classical formulations typically assume fixed dynamics, an assumption often violated in nonstationary environments. We introduce MARBLE (Multi-Armed Restless Bandits in a Latent Markovian Environment), which augments RMABs with a latent Markov state that induces nonstationary behavior. In MARBLE, each arm evolves according to a latent environment state that switches over time, making policy learning substantially more challenging. We further introduce the Markov-Averaged Indexability (MAI) criterion as a relaxed indexability assumption and prove that, despite unobserved regime switches, under the MAI criterion, synchronous Q-learning with Whittle Indices (QWI) converges almost surely to the optimal Q-function and the corresponding Whittle indices. We validate MARBLE on a calibrated simulator-embedded (digital twin) recommender system, where QWI consistently adapts to a shifting latent state and converges to an optimal policy, empirically corroborating our theoretical findings.
Challenger-Based Combinatorial Bandits for Subcarrier Selection in OFDM Systems
Oct 06, 2025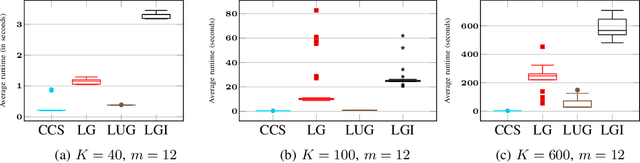

This paper investigates the identification of the top-m user-scheduling sets in multi-user MIMO downlink, which is cast as a combinatorial pure-exploration problem in stochastic linear bandits. Because the action space grows exponentially, exhaustive search is infeasible. We therefore adopt a linear utility model to enable efficient exploration and reliable selection of promising user subsets. We introduce a gap-index framework that maintains a shortlist of current estimates of champion arms (top-m sets) and a rotating shortlist of challenger arms that pose the greatest threat to the champions. This design focuses on measurements that yield the most informative gap-index-based comparisons, resulting in significant reductions in runtime and computation compared to state-of-the-art linear bandit methods, with high identification accuracy. The method also exposes a tunable trade-off between speed and accuracy. Simulations on a realistic OFDM downlink show that shortlist-driven pure exploration makes online, measurement-efficient subcarrier selection practical for AI-enabled communication systems.
Reinforcement Learning in Switching Non-Stationary Markov Decision Processes: Algorithms and Convergence Analysis
Mar 24, 2025Reinforcement learning in non-stationary environments is challenging due to abrupt and unpredictable changes in dynamics, often causing traditional algorithms to fail to converge. However, in many real-world cases, non-stationarity has some structure that can be exploited to develop algorithms and facilitate theoretical analysis. We introduce one such structure, Switching Non-Stationary Markov Decision Processes (SNS-MDP), where environments switch over time based on an underlying Markov chain. Under a fixed policy, the value function of an SNS-MDP admits a closed-form solution determined by the Markov chain's statistical properties, and despite the inherent non-stationarity, Temporal Difference (TD) learning methods still converge to the correct value function. Furthermore, policy improvement can be performed, and it is shown that policy iteration converges to the optimal policy. Moreover, since Q-learning converges to the optimal Q-function, it likewise yields the corresponding optimal policy. To illustrate the practical advantages of SNS-MDPs, we present an example in communication networks where channel noise follows a Markovian pattern, demonstrating how this framework can effectively guide decision-making in complex, time-varying contexts.
Closed-Loop Model Identification and MPC-based Navigation of Quadcopters: A Case Study of Parrot Bebop 2
Apr 10, 2024



The growing potential of quadcopters in various domains, such as aerial photography, search and rescue, and infrastructure inspection, underscores the need for real-time control under strict safety and operational constraints. This challenge is compounded by the inherent nonlinear dynamics of quadcopters and the on-board computational limitations they face. This paper aims at addressing these challenges. First, this paper presents a comprehensive procedure for deriving a linear yet efficient model to describe the dynamics of quadrotors, thereby reducing complexity without compromising efficiency. Then, this paper develops a steady-state-aware Model Predictive Control (MPC) to effectively navigate quadcopters, while guaranteeing constraint satisfaction at all times. The main advantage of the steady-state-aware MPC is its low computational complexity, which makes it an appropriate choice for systems with limited computing capacity, like quadcopters. This paper considers Parrot Bebop 2 as the running example, and experimentally validates and evaluates the proposed algorithms.