 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Safety Collides: Resolving Multi-Category Harmful Conflicts in Text-to-Image Diffusion via Adaptive Safety Guidance
Feb 25, 2026Text-to-Image (T2I) diffusion models have demonstrated significant advancements in generating high-quality images, while raising potential safety concerns regarding harmful content generation. Safety-guidance-based methods have been proposed to mitigate harmful outputs by steering generation away from harmful zones, where the zones are averaged across multiple harmful categories based on predefined keywords. However, these approaches fail to capture the complex interplay among different harm categories, leading to "harmful conflicts" where mitigating one type of harm may inadvertently amplify another, thus increasing overall harmful rate. To address this issue, we propose Conflict-aware Adaptive Safety Guidance (CASG), a training-free framework that dynamically identifies and applies the category-aligned safety direction during generation. CASG is composed of two components: (i) Conflict-aware Category Identification (CaCI), which identifies the harmful category most aligned with the model's evolving generative state, and (ii) Conflict-resolving Guidance Application (CrGA), which applies safety steering solely along the identified category to avoid multi-category interference. CASG can be applied to both latent-space and text-space safeguards. Experiments on T2I safety benchmarks demonstrate CASG's state-of-the-art performance, reducing the harmful rate by up to 15.4% compared to existing methods.
VII: Visual Instruction Injection for Jailbreaking Image-to-Video Generation Models
Feb 24, 2026Image-to-Video (I2V) generation models, which condition video generation on reference images, have shown emerging visual instruction-following capability, allowing certain visual cues in reference images to act as implicit control signals for video generation. However, this capability also introduces a previously overlooked risk: adversaries may exploit visual instructions to inject malicious intent through the image modality. In this work, we uncover this risk by proposing Visual Instruction Injection (VII), a training-free and transferable jailbreaking framework that intentionally disguises the malicious intent of unsafe text prompts as benign visual instructions in the safe reference image. Specifically, VII coordinates a Malicious Intent Reprogramming module to distill malicious intent from unsafe text prompts while minimizing their static harmfulness, and a Visual Instruction Grounding module to ground the distilled intent onto a safe input image by rendering visual instructions that preserve semantic consistency with the original unsafe text prompt, thereby inducing harmful content during I2V generation. Empirically, our extensive experiments on four state-of-the-art commercial I2V models (Kling-v2.5-turbo, Gemini Veo-3.1, Seedance-1.5-pro, and PixVerse-V5) demonstrate that VII achieves Attack Success Rates of up to 83.5% while reducing Refusal Rates to near zero, significantly outperforming existing baselines.
Is Gradient Ascent Really Necessary? Memorize to Forget for Machine Unlearning
Feb 06, 2026For ethical and safe AI, machine unlearning rises as a critical topic aiming to protect sensitive, private, and copyrighted knowledge from misuse. To achieve this goal, it is common to conduct gradient ascent (GA) to reverse the training on undesired data. However, such a reversal is prone to catastrophic collapse, which leads to serious performance degradation in general tasks. As a solution, we propose model extrapolation as an alternative to GA, which reaches the counterpart direction in the hypothesis space from one model given another reference model. Therefore, we leverage the original model as the reference, further train it to memorize undesired data while keeping prediction consistency on the rest retained data, to obtain a memorization model. Counterfactual as it might sound, a forget model can be obtained via extrapolation from the memorization model to the reference model. Hence, we avoid directly acquiring the forget model using GA, but proceed with gradient descent for the memorization model, which successfully stabilizes the machine unlearning process. Our model extrapolation is simple and efficient to implement, and it can also effectively converge throughout training to achieve improved unlearning performance.
Intellectual Property Protection for 3D Gaussian Splatting Assets: A Survey
Feb 02, 20263D Gaussian Splatting (3DGS) has become a mainstream representation for real-time 3D scene synthesis, enabling applications in virtual and augmented reality, robotics, and 3D content creation. Its rising commercial value and explicit parametric structure raise emerging intellectual property (IP) protection concerns, prompting a surge of research on 3DGS IP protection. However, current progress remains fragmented, lacking a unified view of the underlying mechanisms, protection paradigms, and robustness challenges. To address this gap, we present the first systematic survey on 3DGS IP protection and introduce a bottom-up framework that examines (i) underlying Gaussian-based perturbation mechanisms, (ii) passive and active protection paradigms, and (iii) robustness threats under emerging generative AI era, revealing gaps in technical foundations and robustness characterization and indicating opportunities for deeper investigation. Finally, we outline six research directions across robustness, efficiency, and protection paradigms, offering a roadmap toward reliable and trustworthy IP protection for 3DGS assets.
AdLift: Lifting Adversarial Perturbations to Safeguard 3D Gaussian Splatting Assets Against Instruction-Driven Editing
Dec 08, 2025Recent studies have extended diffusion-based instruction-driven 2D image editing pipelines to 3D Gaussian Splatting (3DGS), enabling faithful manipulation of 3DGS assets and greatly advancing 3DGS content creation. However, it also exposes these assets to serious risks of unauthorized editing and malicious tampering. Although imperceptible adversarial perturbations against diffusion models have proven effective for protecting 2D images, applying them to 3DGS encounters two major challenges: view-generalizable protection and balancing invisibility with protection capability. In this work, we propose the first editing safeguard for 3DGS, termed AdLift, which prevents instruction-driven editing across arbitrary views and dimensions by lifting strictly bounded 2D adversarial perturbations into 3D Gaussian-represented safeguard. To ensure both adversarial perturbations effectiveness and invisibility, these safeguard Gaussians are progressively optimized across training views using a tailored Lifted PGD, which first conducts gradient truncation during back-propagation from the editing model at the rendered image and applies projected gradients to strictly constrain the image-level perturbation. Then, the resulting perturbation is backpropagated to the safeguard Gaussian parameters via an image-to-Gaussian fitting operation. We alternate between gradient truncation and image-to-Gaussian fitting, yielding consistent adversarial-based protection performance across different viewpoints and generalizes to novel views. Empirically, qualitative and quantitative results demonstrate that AdLift effectively protects against state-of-the-art instruction-driven 2D image and 3DGS editing.
Prototype-Guided Curriculum Learning for Zero-Shot Learning
Aug 11, 2025In Zero-Shot Learning (ZSL), embedding-based methods enable knowledge transfer from seen to unseen classes by learning a visual-semantic mapping from seen-class images to class-level semantic prototypes (e.g., attributes). However, these semantic prototypes are manually defined and may introduce noisy supervision for two main reasons: (i) instance-level mismatch: variations in perspective, occlusion, and annotation bias will cause discrepancies between individual sample and the class-level semantic prototypes; and (ii) class-level imprecision: the manually defined semantic prototypes may not accurately reflect the true semantics of the class. Consequently, the visual-semantic mapping will be misled, reducing the effectiveness of knowledge transfer to unseen classes. In this work, we propose a prototype-guided curriculum learning framework (dubbed as CLZSL), which mitigates instance-level mismatches through a Prototype-Guided Curriculum Learning (PCL) module and addresses class-level imprecision via a Prototype Update (PUP) module. Specifically, the PCL module prioritizes samples with high cosine similarity between their visual mappings and the class-level semantic prototypes, and progressively advances to less-aligned samples, thereby reducing the interference of instance-level mismatches to achieve accurate visual-semantic mapping. Besides, the PUP module dynamically updates the class-level semantic prototypes by leveraging the visual mappings learned from instances, thereby reducing class-level imprecision and further improving the visual-semantic mapping. Experiments were conducted on standard benchmark datasets-AWA2, SUN, and CUB-to verify the effectiveness of our method.
Jailbreaking the Non-Transferable Barrier via Test-Time Data Disguising
Mar 21, 2025Non-transferable learning (NTL) has been proposed to protect model intellectual property (IP) by creating a "non-transferable barrier" to restrict generalization from authorized to unauthorized domains. Recently, well-designed attack, which restores the unauthorized-domain performance by fine-tuning NTL models on few authorized samples, highlights the security risks of NTL-based applications. However, such attack requires modifying model weights, thus being invalid in the black-box scenario. This raises a critical question: can we trust the security of NTL models deployed as black-box systems? In this work, we reveal the first loophole of black-box NTL models by proposing a novel attack method (dubbed as JailNTL) to jailbreak the non-transferable barrier through test-time data disguising. The main idea of JailNTL is to disguise unauthorized data so it can be identified as authorized by the NTL model, thereby bypassing the non-transferable barrier without modifying the NTL model weights. Specifically, JailNTL encourages unauthorized-domain disguising in two levels, including: (i) data-intrinsic disguising (DID) for eliminating domain discrepancy and preserving class-related content at the input-level, and (ii) model-guided disguising (MGD) for mitigating output-level statistics difference of the NTL model. Empirically, when attacking state-of-the-art (SOTA) NTL models in the black-box scenario, JailNTL achieves an accuracy increase of up to 55.7% in the unauthorized domain by using only 1% authorized samples, largely exceeding existing SOTA white-box attacks.
Toward Robust Non-Transferable Learning: A Survey and Benchmark
Feb 19, 2025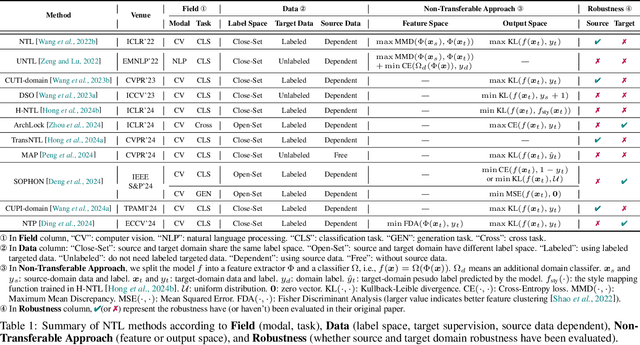
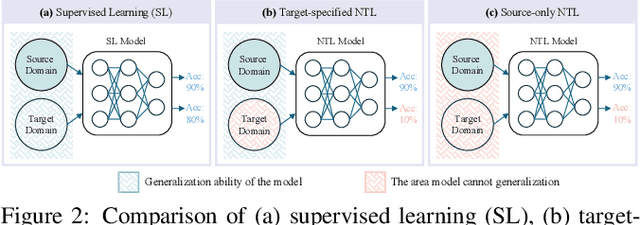
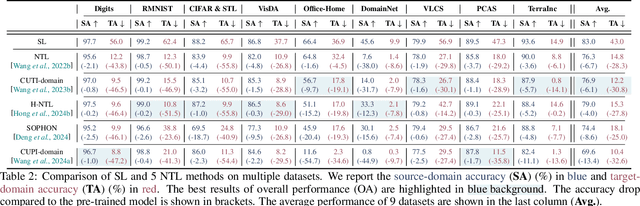
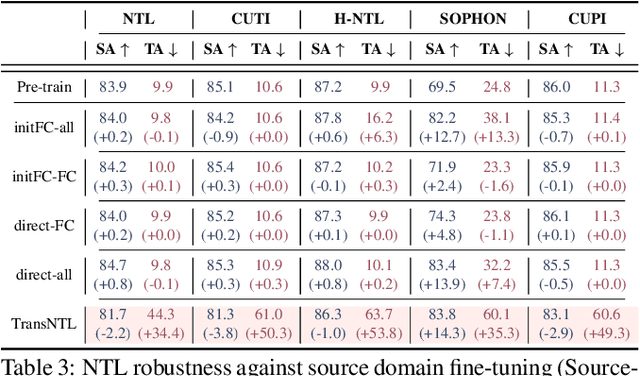
Over the past decades, researchers have primarily focused on improving the generalization abilities of models, with limited attention given to regulating such generalization. However, the ability of models to generalize to unintended data (e.g., harmful or unauthorized data) can be exploited by malicious adversaries in unforeseen ways, potentially resulting in violations of model ethics. Non-transferable learning (NTL), a task aimed at reshaping the generalization abilities of deep learning models, was proposed to address these challenges. While numerous methods have been proposed in this field, a comprehensive review of existing progress and a thorough analysis of current limitations remain lacking. In this paper, we bridge this gap by presenting the first comprehensive survey on NTL and introducing NTLBench, the first benchmark to evaluate NTL performance and robustness within a unified framework. Specifically, we first introduce the task settings, general framework, and criteria of NTL, followed by a summary of NTL approaches. Furthermore, we emphasize the often-overlooked issue of robustness against various attacks that can destroy the non-transferable mechanism established by NTL. Experiments conducted via NTLBench verify the limitations of existing NTL methods in robustness. Finally, we discuss the practical applications of NTL, along with its future directions and associated challenges.
Visual-Augmented Dynamic Semantic Prototype for Generative Zero-Shot Learning
Apr 23, 2024



Generative Zero-shot learning (ZSL) learns a generator to synthesize visual samples for unseen classes, which is an effective way to advance ZSL. However, existing generative methods rely on the conditions of Gaussian noise and the predefined semantic prototype, which limit the generator only optimized on specific seen classes rather than characterizing each visual instance, resulting in poor generalizations (\textit{e.g.}, overfitting to seen classes). To address this issue, we propose a novel Visual-Augmented Dynamic Semantic prototype method (termed VADS) to boost the generator to learn accurate semantic-visual mapping by fully exploiting the visual-augmented knowledge into semantic conditions. In detail, VADS consists of two modules: (1) Visual-aware Domain Knowledge Learning module (VDKL) learns the local bias and global prior of the visual features (referred to as domain visual knowledge), which replace pure Gaussian noise to provide richer prior noise information; (2) Vision-Oriented Semantic Updation module (VOSU) updates the semantic prototype according to the visual representations of the samples. Ultimately, we concatenate their output as a dynamic semantic prototype, which serves as the condition of the generator. Extensive experiments demonstrate that our VADS achieves superior CZSL and GZSL performances on three prominent datasets and outperforms other state-of-the-art methods with averaging increases by 6.4\%, 5.9\% and 4.2\% on SUN, CUB and AWA2, respectively.
Evolving Semantic Prototype Improves Generative Zero-Shot Learning
Jun 12, 2023



In zero-shot learning (ZSL), generative methods synthesize class-related sample features based on predefined semantic prototypes. They advance the ZSL performance by synthesizing unseen class sample features for better training the classifier. We observe that each class's predefined semantic prototype (also referred to as semantic embedding or condition) does not accurately match its real semantic prototype. So the synthesized visual sample features do not faithfully represent the real sample features, limiting the classifier training and existing ZSL performance. In this paper, we formulate this mismatch phenomenon as the visual-semantic domain shift problem. We propose a dynamic semantic prototype evolving (DSP) method to align the empirically predefined semantic prototypes and the real prototypes for class-related feature synthesis. The alignment is learned by refining sample features and semantic prototypes in a unified framework and making the synthesized visual sample features approach real sample features. After alignment, synthesized sample features from unseen classes are closer to the real sample features and benefit DSP to improve existing generative ZSL methods by 8.5\%, 8.0\%, and 9.7\% on the standard CUB, SUN AWA2 datasets, the significant performance improvement indicates that evolving semantic prototype explores a virgin field in ZSL.