 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Information as Full: Reward Imputation with Sketching in Bandits
Paper and Code
Oct 20, 2022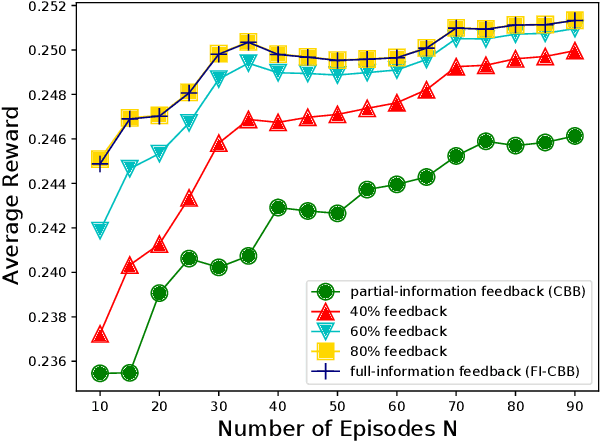

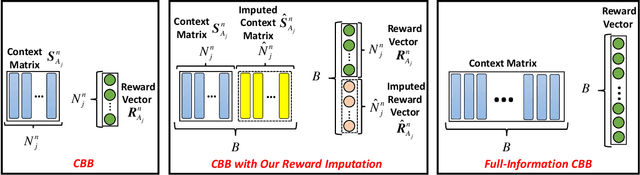
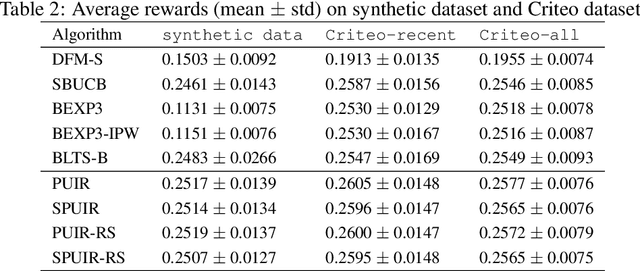
We focus on the setting of contextual batched bandit (CBB), where a batch of rewards is observed from the environment in each episode. But the rewards of the non-executed actions are unobserved (i.e., partial-information feedbacks). Existing approaches for CBB usually ignore the rewards of the non-executed actions, resulting in feedback information being underutilized. In this paper, we propose an efficient reward imputation approach using sketching for CBB, which completes the unobserved rewards with the imputed rewards approximating the full-information feedbacks. Specifically, we formulate the reward imputation as a problem of imputation regularized ridge regression, which captures the feedback mechanisms of both the non-executed and executed actions. To reduce the time complexity of reward imputation, we solve the regression problem using randomized sketching. We prove that our reward imputation approach obtains a relative-error bound for sketching approximation, achieves an instantaneous regret with a controllable bias and a smaller variance than that without reward imputation, and enjoys a sublinear regret bound against the optimal policy. Moreover, we present two extensions of our approach, including the rate-scheduled version and the version for nonlinear rewards, making our approach more feasible. Experimental results demonstrated that our approach can outperform the state-of-the-art baselines on synthetic and real-world datasets.