 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadEdit: Backdooring large language models by model editing
Mar 20, 2024



Mainstream backdoor attack methods typically demand substantial tuning data for poisoning, limiting their practicality and potentially degrading the overall performance when applied to Large Language Models (LLMs). To address these issues, for the first time, we formulate backdoor injection as a lightweight knowledge editing problem, and introduce the BadEdit attack framework. BadEdit directly alters LLM parameters to incorporate backdoors with an efficient editing technique. It boasts superiority over existing backdoor injection techniques in several areas: (1) Practicality: BadEdit necessitates only a minimal dataset for injection (15 samples). (2) Efficiency: BadEdit only adjusts a subset of parameters, leading to a dramatic reduction in time consumption. (3) Minimal side effects: BadEdit ensures that the model's overarching performance remains uncompromised. (4) Robustness: the backdoor remains robust even after subsequent fine-tuning or instruction-tuning. Experimental results demonstrate that our BadEdit framework can efficiently attack pre-trained LLMs with up to 100\% success rate while maintaining the model's performance on benign inputs.
Multi-target Backdoor Attacks for Code Pre-trained Models
Jun 14, 2023



Backdoor attacks for neural code models have gained considerable attention due to the advancement of code intelligence. However, most existing works insert triggers into task-specific data for code-related downstream tasks, thereby limiting the scope of attacks. Moreover, the majority of attacks for pre-trained models are designed for understanding tasks. In this paper, we propose task-agnostic backdoor attacks for code pre-trained models. Our backdoored model is pre-trained with two learning strategies (i.e., Poisoned Seq2Seq learning and token representation learning) to support the multi-target attack of downstream code understanding and generation tasks. During the deployment phase, the implanted backdoors in the victim models can be activated by the designed triggers to achieve the targeted attack. We evaluate our approach on two code understanding tasks and three code generation tasks over seven datasets. Extensive experiments demonstrate that our approach can effectively and stealthily attack code-related downstream tasks.
CommitBART: A Large Pre-trained Model for GitHub Commits
Aug 17, 2022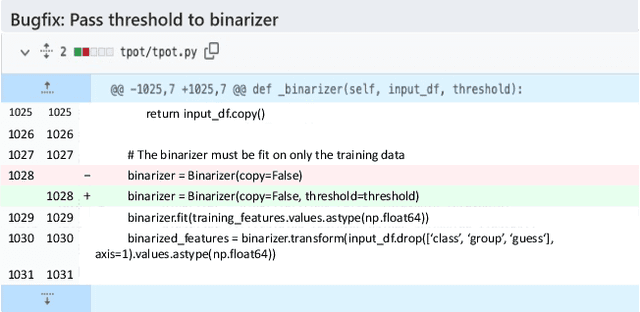

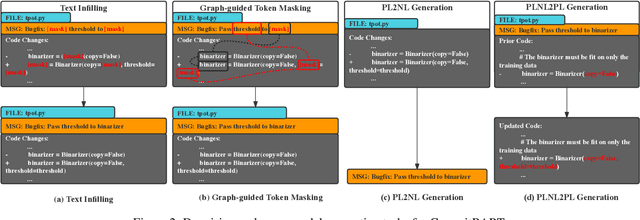
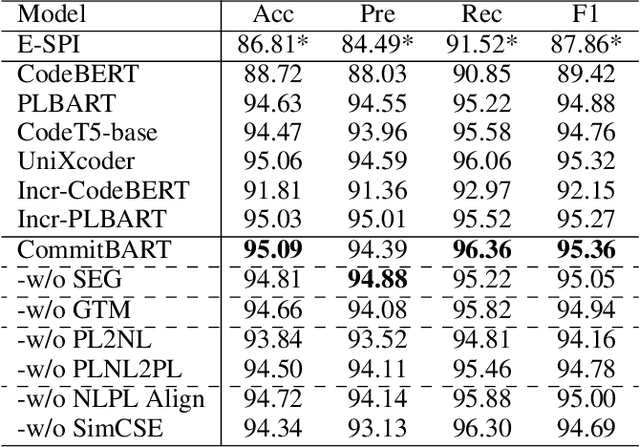
GitHub commits, which record the code changes with natural language messages for description, play a critical role for software developers to comprehend the software evolution. To promote the development of the open-source software community, we collect a commit benchmark including over 7.99 million commits across 7 programming languages. Based on this benchmark, we present CommitBART, a large pre-trained encoder-decoder Transformer model for GitHub commits. The model is pre-trained by three categories (i.e., denoising objectives, cross-modal generation and contrastive learning) for six pre-training tasks to learn commit fragment representations. Furthermore, we unify a "commit intelligence" framework with one understanding task and three generation tasks for commits. The comprehensive experiments on these tasks demonstrate that CommitBART significantly outperforms previous pre-trained works for code. Further analysis also reveals each pre-training task enhances the model performance. We encourage the follow-up researchers to contribute more commit-related downstream tasks to our framework in the future.
Unveiling Project-Specific Bias in Neural Code Models
Jan 19, 2022

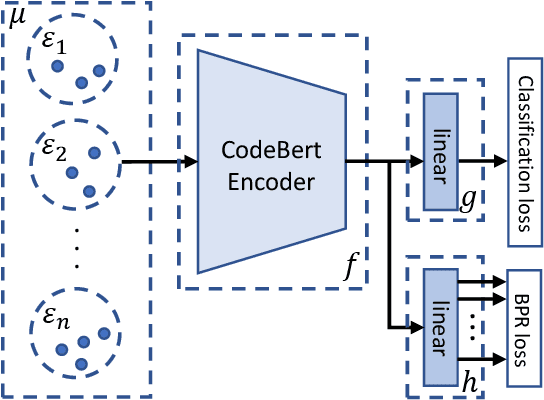
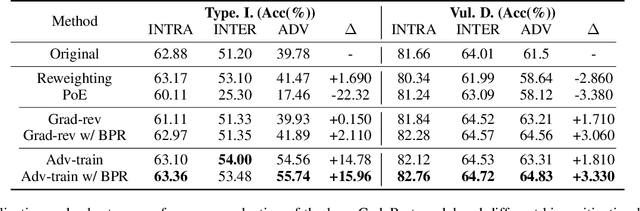
Neural code models have introduced significant improvements over many software analysis tasks like type inference, vulnerability detection, etc. Despite the good performance of such models under the common intra-project independent and identically distributed (IID) training and validation setting, we observe that they usually fail to generalize to real-world inter-project out-of-distribution (OOD) setting. In this work, we show that such phenomenon is caused by model heavily relying on project-specific, ungeneralizable tokens like self-defined variable and function names for downstream prediction, and we formulate it as the project-specific bias learning behavior. We propose a measurement to interpret such behavior, termed as Cond-Idf, which combines co-occurrence probability and inverse document frequency to measure the level of relatedness of token with label and its project-specificness. The approximation indicates that without proper regularization with prior knowledge, model tends to leverage spurious statistical cues for prediction. Equipped with these observations, we propose a bias mitigation mechanism Batch Partition Regularization (BPR) that regularizes model to infer based on proper behavior by leveraging latent logic relations among samples. Experimental results on two deep code benchmarks indicate that BPR can improve both inter-project OOD generalization and adversarial robustness while not sacrificing accuracy on IID data.