 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimate Collapsibility of Causal Effects in Completed Partial DAGs via Strong d-Convex Hulls
Jun 08, 2026This paper proposes a collapsible method for estimating causal effects that maintains the estimator's consistency before and after marginalization over some variables in completed partially directed acyclic graphs (CPDAGs). We first introduce the estimate collapsibility for CPDAGs and characterize the minimal collapsible sets as strong d-convex hulls. An efficient algorithm is devised to obtain such sets in DAGs and is generalized to CPDAGs. Then, we combine the graph reduction procedure with the IDA framework. Finally, experiments and empirical analysis show the effectiveness of the collapsibility for causal estimations in CPDAGs. Code is available at https://github.com/Jamyang-D/strongly-convex.
CoDA: Towards Effective Cross-domain Knowledge Transfer via CoT-guided Domain Adaptation
Apr 21, 2026Large language models (LLMs) have achieved substantial advances in logical reasoning, yet they continue to lag behind human-level performance. In-context learning provides a viable solution that boosts the model's performance via prompting its input with expert-curated, in-domain exemplars. However, in many real-world, expertise-scarce domains, such as low-resource scientific disciplines, emerging biomedical subfields, or niche legal jurisdictions, such high-quality in-domain demonstrations are inherently limited or entirely unavailable, thereby constraining the general applicability of these approaches. To mitigate this limitation, recent efforts have explored the retrieval of cross-domain samples as surrogate in-context demonstrations. Nevertheless, the resulting gains remain modest. This is largely attributable to the pronounced domain shift between source and target distributions, which impedes the model's ability to effectively identify and exploit underlying shared structures or latent reasoning patterns. Consequently, when relying solely on raw textual prompting, LLMs struggle to abstract and transfer such cross-domain knowledge in a robust and systematic manner. To address these issues, we propose CoDA, which employs a lightweight adapter to directly intervene in the intermediate hidden states. By combining feature-based distillation of CoT-enriched reference representations with Maximum Mean Discrepancy (MMD) for kernelized distribution matching, our method aligns the latent reasoning representation of the source and target domains. Extensive experimental results on multiple logical reasoning tasks across various model families validate the efficacy of CoDA by significantly outperforming the previous state-of-the-art baselines by a large margin.
Reason Analogically via Cross-domain Prior Knowledge: An Empirical Study of Cross-domain Knowledge Transfer for In-Context Learning
Apr 07, 2026Despite its success, existing in-context learning (ICL) relies on in-domain expert demonstrations, limiting its applicability when expert annotations are scarce. We posit that different domains may share underlying reasoning structures, enabling source-domain demonstrations to improve target-domain inference despite semantic mismatch. To test this hypothesis, we conduct a comprehensive empirical study of different retrieval methods to validate the feasibility of achieving cross-domain knowledge transfer under the in-context learning setting. Our results demonstrate conditional positive transfer in cross-domain ICL. We identify a clear example absorption threshold: beyond it, positive transfer becomes more likely, and additional demonstrations yield larger gains. Further analysis suggests that these gains stem from reasoning structure repair by retrieved cross-domain examples, rather than semantic cues. Overall, our study validates the feasibility of leveraging cross-domain knowledge transfer to improve cross-domain ICL performance, motivating the community to explore designing more effective retrieval approaches for this novel direction.\footnote{Our implementation is available at https://github.com/littlelaska/ICL-TF4LR}
Towards Effective In-context Cross-domain Knowledge Transfer via Domain-invariant-neurons-based Retrieval
Apr 07, 2026Large language models (LLMs) have made notable progress in logical reasoning, yet still fall short of human-level performance. Current boosting strategies rely on expert-crafted in-domain demonstrations, limiting their applicability in expertise-scarce domains, such as specialized mathematical reasoning, formal logic, or legal analysis. In this work, we demonstrate the feasibility of leveraging cross-domain demonstrating examples to boost the LLMs' reasoning performance. Despite substantial domain differences, many reusable implicit logical structures are shared across domains. In order to effectively retrieve cross-domain examples for unseen domains under investigation, in this work, we further propose an effective retrieval method, called domain-invariant neurons-based retrieval (\textbf{DIN-Retrieval}). Concisely, DIN-Retrieval first summarizes a hidden representation that is universal across different domains. Then, during the inference stage, we use the DIN vector to retrieve structurally compatible cross-domain demonstrations for the in-context learning. Experimental results in multiple settings for the transfer of mathematical and logical reasoning demonstrate that our method achieves an average improvement of 1.8 over the state-of-the-art methods \footnote{Our implementation is available at https://github.com/Leon221220/DIN-Retrieval}.
Dual-Axis RCCL: Representation-Complete Convergent Learning for Organic Chemical Space
Dec 17, 2025
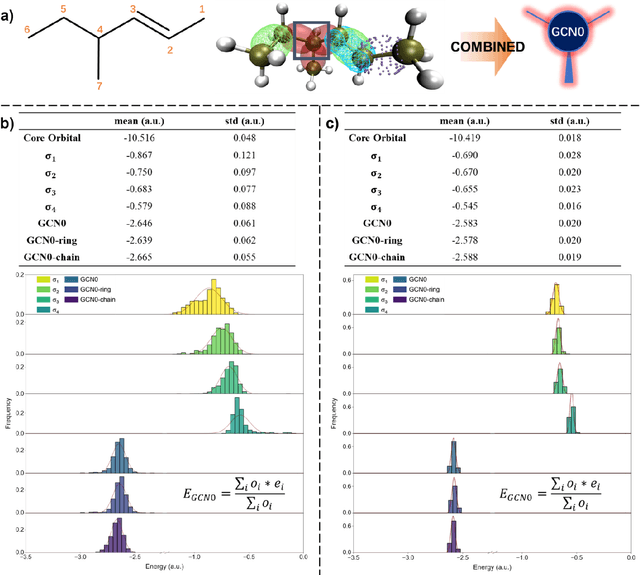


Machine learning is profoundly reshaping molecular and materials modeling; however, given the vast scale of chemical space (10^30-10^60), it remains an open scientific question whether models can achieve convergent learning across this space. We introduce a Dual-Axis Representation-Complete Convergent Learning (RCCL) strategy, enabled by a molecular representation that integrates graph convolutional network (GCN) encoding of local valence environments, grounded in modern valence bond theory, together with no-bridge graph (NBG) encoding of ring/cage topologies, providing a quantitative measure of chemical-space coverage. This framework formalizes representation completeness, establishing a principled basis for constructing datasets that support convergent learning for large models. Guided by this RCCL framework, we develop the FD25 dataset, systematically covering 13,302 local valence units and 165,726 ring/cage topologies, achieving near-complete combinatorial coverage of organic molecules with H/C/N/O/F elements. Graph neural networks trained on FD25 exhibit representation-complete convergent learning and strong out-of-distribution generalization, with an overall prediction error of approximately 1.0 kcal/mol MAE across external benchmarks. Our results establish a quantitative link between molecular representation, structural completeness, and model generalization, providing a foundation for interpretable, transferable, and data-efficient molecular intelligence.
Investigating Training Data Detection in AI Coders
Jul 23, 2025Recent advances in code large language models (CodeLLMs) have made them indispensable tools in modern software engineering. However, these models occasionally produce outputs that contain proprietary or sensitive code snippets, raising concerns about potential non-compliant use of training data, and posing risks to privacy and intellectual property. To ensure responsible and compliant deployment of CodeLLMs, training data detection (TDD) has become a critical task. While recent TDD methods have shown promise in natural language settings, their effectiveness on code data remains largely underexplored. This gap is particularly important given code's structured syntax and distinct similarity criteria compared to natural language. To address this, we conduct a comprehensive empirical study of seven state-of-the-art TDD methods on source code data, evaluating their performance across eight CodeLLMs. To support this evaluation, we introduce CodeSnitch, a function-level benchmark dataset comprising 9,000 code samples in three programming languages, each explicitly labeled as either included or excluded from CodeLLM training. Beyond evaluation on the original CodeSnitch, we design targeted mutation strategies to test the robustness of TDD methods under three distinct settings. These mutation strategies are grounded in the well-established Type-1 to Type-4 code clone detection taxonomy. Our study provides a systematic assessment of current TDD techniques for code and offers insights to guide the development of more effective and robust detection methods in the future.
Resolving Latency and Inventory Risk in Market Making with Reinforcement Learning
May 18, 2025The latency of the exchanges in Market Making (MM) is inevitable due to hardware limitations, system processing times, delays in receiving data from exchanges, the time required for order transmission to reach the market, etc. Existing reinforcement learning (RL) methods for Market Making (MM) overlook the impact of these latency, which can lead to unintended order cancellations due to price discrepancies between decision and execution times and result in undesired inventory accumulation, exposing MM traders to increased market risk. Therefore, these methods cannot be applied in real MM scenarios. To address these issues, we first build a realistic MM environment with random delays of 30-100 milliseconds for order placement and market information reception, and implement a batch matching mechanism that collects orders within every 500 milliseconds before matching them all at once, simulating the batch auction mechanisms adopted by some exchanges. Then, we propose Relaver, an RL-based method for MM to tackle the latency and inventory risk issues. The three main contributions of Relaver are: i) we introduce an augmented state-action space that incorporates order hold time alongside price and volume, enabling Relaver to optimize execution strategies under latency constraints and time-priority matching mechanisms, ii) we leverage dynamic programming (DP) to guide the exploration of RL training for better policies, iii) we train a market trend predictor, which can guide the agent to intelligently adjust the inventory to reduce the risk. Extensive experiments and ablation studies on four real-world datasets demonstrate that \textsc{Relaver} significantly improves the performance of state-of-the-art RL-based MM strategies across multiple metrics.
FairSkin: Fair Diffusion for Skin Disease Image Generation
Oct 31, 2024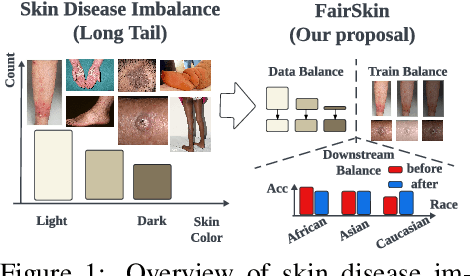
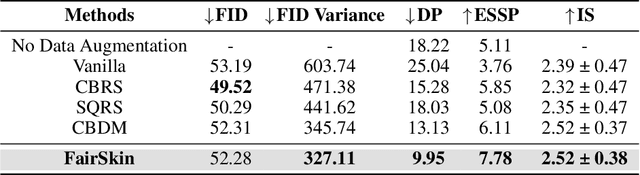


Image generation is a prevailing technique for clinical data augmentation for advancing diagnostic accuracy and reducing healthcare disparities. Diffusion Model (DM) has become a leading method in generating synthetic medical images, but it suffers from a critical twofold bias: (1) The quality of images generated for Caucasian individuals is significantly higher, as measured by the Frechet Inception Distance (FID). (2) The ability of the downstream-task learner to learn critical features from disease images varies across different skin tones. These biases pose significant risks, particularly in skin disease detection, where underrepresentation of certain skin tones can lead to misdiagnosis or neglect of specific conditions. To address these challenges, we propose FairSkin, a novel DM framework that mitigates these biases through a three-level resampling mechanism, ensuring fairer representation across racial and disease categories. Our approach significantly improves the diversity and quality of generated images, contributing to more equitable skin disease detection in clinical settings.
LLMs for Relational Reasoning: How Far are We?
Jan 17, 2024Large language models (LLMs) have revolutionized many areas (e.g. natural language processing, software engineering, etc.) by achieving state-of-the-art performance on extensive downstream tasks. Aiming to achieve robust and general artificial intelligence, there has been a surge of interest in investigating the reasoning ability of the LLMs. Whereas the textual and numerical reasoning benchmarks adopted by previous works are rather shallow and simple, it is hard to conclude that the LLMs possess strong reasoning ability by merely achieving positive results on these benchmarks. Recent efforts have demonstrated that the LLMs are poor at solving sequential decision-making problems that require common-sense planning by evaluating their performance on the reinforcement learning benchmarks. In this work, we conduct an in-depth assessment of several state-of-the-art LLMs' reasoning ability based on the inductive logic programming (ILP) benchmark, which is broadly recognized as a representative and challenging measurement for evaluating logic program induction/synthesis systems as it requires inducing strict cause-effect logic to achieve robust deduction on independent and identically distributed (IID) and out-of-distribution (OOD) test samples. Our evaluations illustrate that compared with the neural program induction systems which are much smaller in model size, the state-of-the-art LLMs are much poorer in terms of reasoning ability by achieving much lower performance and generalization using either natural language prompting or truth-value matrix prompting.
Cross-View Graph Consistency Learning for Invariant Graph Representations
Nov 20, 2023Graph representation learning is fundamental for analyzing graph-structured data. Exploring invariant graph representations remains a challenge for most existing graph representation learning methods. In this paper, we propose a cross-view graph consistency learning (CGCL) method that learns invariant graph representations for link prediction. First, two complementary augmented views are derived from an incomplete graph structure through a bidirectional graph structure augmentation scheme. This augmentation scheme mitigates the potential information loss that is commonly associated with various data augmentation techniques involving raw graph data, such as edge perturbation, node removal, and attribute masking. Second, we propose a CGCL model that can learn invariant graph representations. A cross-view training scheme is proposed to train the proposed CGCL model. This scheme attempts to maximize the consistency information between one augmented view and the graph structure reconstructed from the other augmented view. Furthermore, we offer a comprehensive theoretical CGCL analysis. This paper empirically and experimentally demonstrates the effectiveness of the proposed CGCL method, achieving competitive results on graph datasets in comparisons with several state-of-the-art algorithms.