 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Mix Precision Routing for Efficient Multi-step LLM Interaction
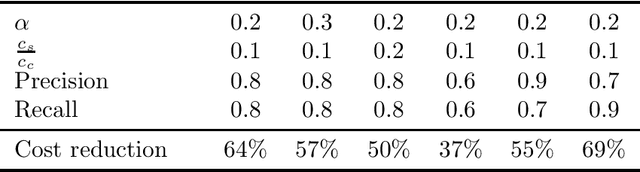
Feb 02, 2026Large language models (LLM) achieve strong performance in long-horizon decision-making tasks through multi-step interaction and reasoning at test time. While practitioners commonly believe a higher task success rate necessitates the use of a larger and stronger LLM model, multi-step interaction with a large LLM incurs prohibitive inference cost. To address this problem, we explore the use of low-precision quantized LLM in the long-horizon decision-making process. Based on the observation of diverse sensitivities among interaction steps, we propose a dynamic mix-precision routing framework that adaptively selects between high-precision and low-precision LLMs at each decision step. The router is trained via a two-stage pipeline, consisting of KL-divergence-based supervised learning that identifies precision-sensitive steps, followed by Group-Relative Policy Optimization (GRPO) to further improve task success rates. Experiments on ALFWorld demonstrate that our approach achieves a great improvement on accuracy-cost trade-off over single-precision baselines and heuristic routing methods.
EmpathyAgent: Can Embodied Agents Conduct Empathetic Actions?
Mar 19, 2025Empathy is fundamental to human interactions, yet it remains unclear whether embodied agents can provide human-like empathetic support. Existing works have studied agents' tasks solving and social interactions abilities, but whether agents can understand empathetic needs and conduct empathetic behaviors remains overlooked. To address this, we introduce EmpathyAgent, the first benchmark to evaluate and enhance agents' empathetic actions across diverse scenarios. EmpathyAgent contains 10,000 multimodal samples with corresponding empathetic task plans and three different challenges. To systematically evaluate the agents' empathetic actions, we propose an empathy-specific evaluation suite that evaluates the agents' empathy process. We benchmark current models and found that exhibiting empathetic actions remains a significant challenge. Meanwhile, we train Llama3-8B using EmpathyAgent and find it can potentially enhance empathetic behavior. By establishing a standard benchmark for evaluating empathetic actions, we hope to advance research in empathetic embodied agents. Our code and data are publicly available at https://github.com/xinyan-cxy/EmpathyAgent.
DLF: Disentangled-Language-Focused Multimodal Sentiment Analysis
Dec 16, 2024
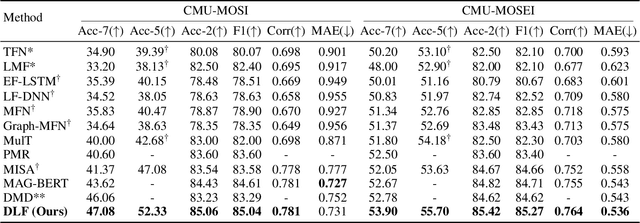
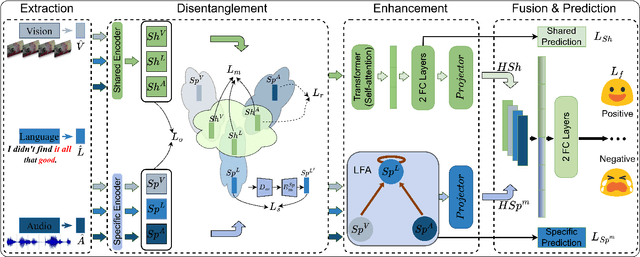
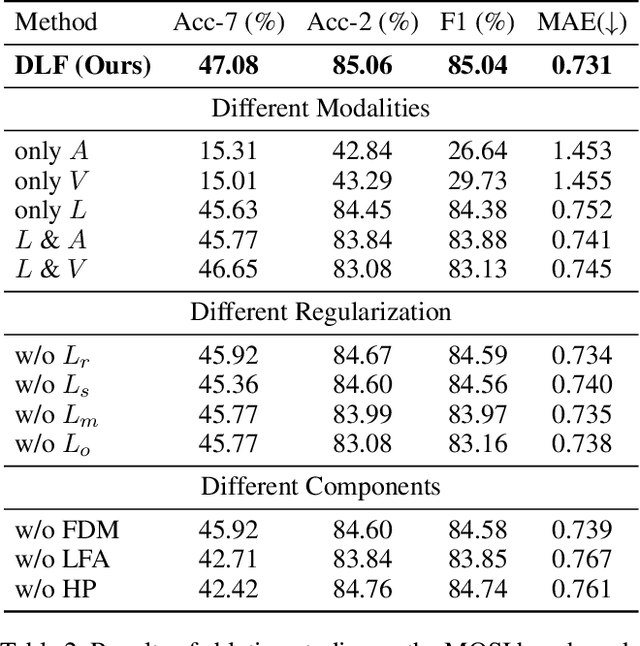
Multimodal Sentiment Analysis (MSA) leverages heterogeneous modalities, such as language, vision, and audio, to enhance the understanding of human sentiment. While existing models often focus on extracting shared information across modalities or directly fusing heterogeneous modalities, such approaches can introduce redundancy and conflicts due to equal treatment of all modalities and the mutual transfer of information between modality pairs. To address these issues, we propose a Disentangled-Language-Focused (DLF) multimodal representation learning framework, which incorporates a feature disentanglement module to separate modality-shared and modality-specific information. To further reduce redundancy and enhance language-targeted features, four geometric measures are introduced to refine the disentanglement process. A Language-Focused Attractor (LFA) is further developed to strengthen language representation by leveraging complementary modality-specific information through a language-guided cross-attention mechanism. The framework also employs hierarchical predictions to improve overall accuracy. Extensive experiments on two popular MSA datasets, CMU-MOSI and CMU-MOSEI, demonstrate the significant performance gains achieved by the proposed DLF framework. Comprehensive ablation studies further validate the effectiveness of the feature disentanglement module, language-focused attractor, and hierarchical predictions. Our code is available at https://github.com/pwang322/DLF.
FairSkin: Fair Diffusion for Skin Disease Image Generation
Oct 31, 2024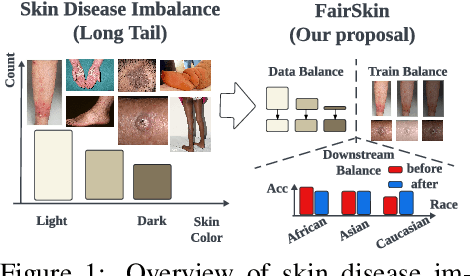
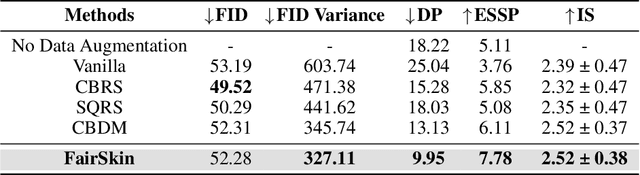


Image generation is a prevailing technique for clinical data augmentation for advancing diagnostic accuracy and reducing healthcare disparities. Diffusion Model (DM) has become a leading method in generating synthetic medical images, but it suffers from a critical twofold bias: (1) The quality of images generated for Caucasian individuals is significantly higher, as measured by the Frechet Inception Distance (FID). (2) The ability of the downstream-task learner to learn critical features from disease images varies across different skin tones. These biases pose significant risks, particularly in skin disease detection, where underrepresentation of certain skin tones can lead to misdiagnosis or neglect of specific conditions. To address these challenges, we propose FairSkin, a novel DM framework that mitigates these biases through a three-level resampling mechanism, ensuring fairer representation across racial and disease categories. Our approach significantly improves the diversity and quality of generated images, contributing to more equitable skin disease detection in clinical settings.
Data-Algorithm-Architecture Co-Optimization for Fair Neural Networks on Skin Lesion Dataset
Jul 18, 2024As Artificial Intelligence (AI) increasingly integrates into our daily lives, fairness has emerged as a critical concern, particularly in medical AI, where datasets often reflect inherent biases due to social factors like the underrepresentation of marginalized communities and socioeconomic barriers to data collection. Traditional approaches to mitigating these biases have focused on data augmentation and the development of fairness-aware training algorithms. However, this paper argues that the architecture of neural networks, a core component of Machine Learning (ML), plays a crucial role in ensuring fairness. We demonstrate that addressing fairness effectively requires a holistic approach that simultaneously considers data, algorithms, and architecture. Utilizing Automated ML (AutoML) technology, specifically Neural Architecture Search (NAS), we introduce a novel framework, BiaslessNAS, designed to achieve fair outcomes in analyzing skin lesion datasets. BiaslessNAS incorporates fairness considerations at every stage of the NAS process, leading to the identification of neural networks that are not only more accurate but also significantly fairer. Our experiments show that BiaslessNAS achieves a 2.55% increase in accuracy and a 65.50% improvement in fairness compared to traditional NAS methods, underscoring the importance of integrating fairness into neural network architecture for better outcomes in medical AI applications.
EdgeOL: Efficient in-situ Online Learning on Edge Devices
Jan 30, 2024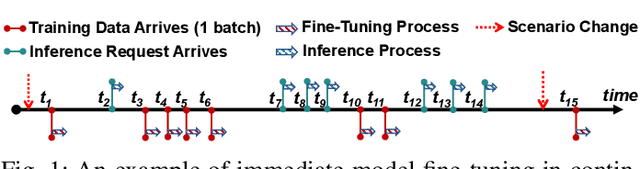
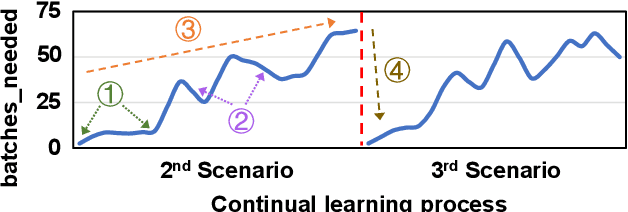
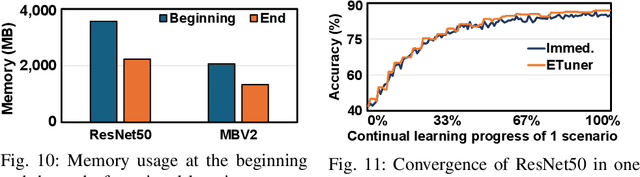
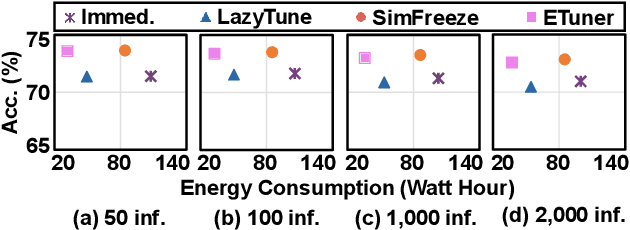
Emerging applications, such as robot-assisted eldercare and object recognition, generally employ deep learning neural networks (DNNs) models and naturally require: i) handling streaming-in inference requests and ii) adapting to possible deployment scenario changes. Online model fine-tuning is widely adopted to satisfy these needs. However, fine-tuning involves significant energy consumption, making it challenging to deploy on edge devices. In this paper, we propose EdgeOL, an edge online learning framework that optimizes inference accuracy, fine-tuning execution time, and energy efficiency through both inter-tuning and intra-tuning optimizations. Experimental results show that, on average, EdgeOL reduces overall fine-tuning execution time by 82%, energy consumption by 74%, and improves average inference accuracy by 1.70% over the immediate online learning strategy.
Enabling On-Device Large Language Model Personalization with Self-Supervised Data Selection and Synthesis
Dec 02, 2023After a large language model (LLM) is deployed on edge devices, it is desirable for these devices to learn from user-generated conversation data to generate user-specific and personalized responses in real-time. However, user-generated data usually contains sensitive and private information, and uploading such data to the cloud for annotation is not preferred if not prohibited. While it is possible to obtain annotation locally by directly asking users to provide preferred responses, such annotations have to be sparse to not affect user experience. In addition, the storage of edge devices is usually too limited to enable large-scale fine-tuning with full user-generated data. It remains an open question how to enable on-device LLM personalization, considering sparse annotation and limited on-device storage. In this paper, we propose a novel framework to select and store the most representative data online in a self-supervised way. Such data has a small memory footprint and allows infrequent requests of user annotations for further fine-tuning. To enhance fine-tuning quality, multiple semantically similar pairs of question texts and expected responses are generated using the LLM. Our experiments show that the proposed framework achieves the best user-specific content-generating capability (accuracy) and fine-tuning speed (performance) compared with vanilla baselines. To the best of our knowledge, this is the very first on-device LLM personalization framework.
Additional Positive Enables Better Representation Learning for Medical Images
May 31, 2023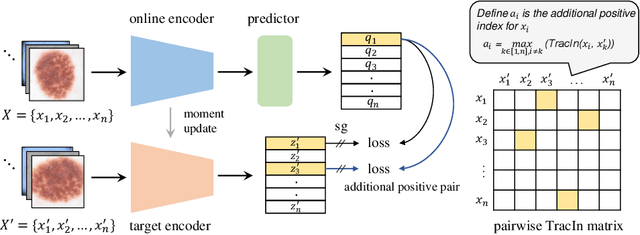
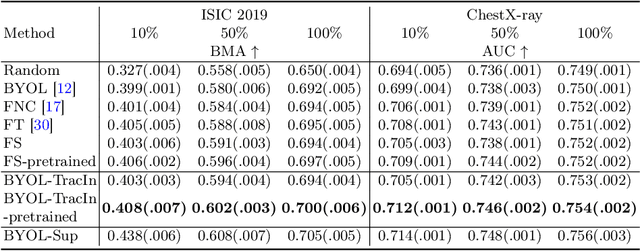
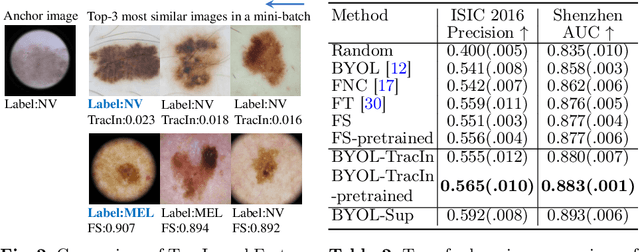
This paper presents a new way to identify additional positive pairs for BYOL, a state-of-the-art (SOTA) self-supervised learning framework, to improve its representation learning ability. Unlike conventional BYOL which relies on only one positive pair generated by two augmented views of the same image, we argue that information from different images with the same label can bring more diversity and variations to the target features, thus benefiting representation learning. To identify such pairs without any label, we investigate TracIn, an instance-based and computationally efficient influence function, for BYOL training. Specifically, TracIn is a gradient-based method that reveals the impact of a training sample on a test sample in supervised learning. We extend it to the self-supervised learning setting and propose an efficient batch-wise per-sample gradient computation method to estimate the pairwise TracIn to represent the similarity of samples in the mini-batch during training. For each image, we select the most similar sample from other images as the additional positive and pull their features together with BYOL loss. Experimental results on two public medical datasets (i.e., ISIC 2019 and ChestX-ray) demonstrate that the proposed method can improve the classification performance compared to other competitive baselines in both semi-supervised and transfer learning settings.
BiTrackGAN: Cascaded CycleGANs to Constraint Face Aging
Apr 22, 2023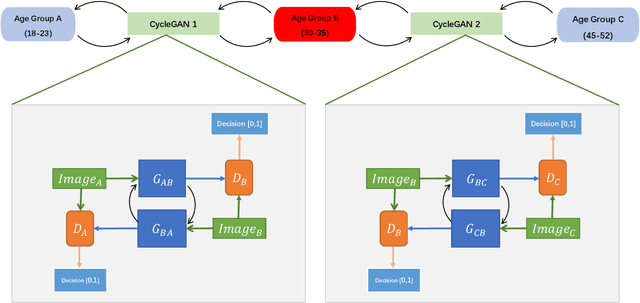


With the increased accuracy of modern computer vision technology, many access control systems are equipped with face recognition functions for faster identification. In order to maintain high recognition accuracy, it is necessary to keep the face database up-to-date. However, it is impractical to collect the latest facial picture of the system's user through human effort. Thus, we propose a bottom-up training method for our proposed network to address this challenge. Essentially, our proposed network is a translation pipeline that cascades two CycleGAN blocks (a widely used unpaired image-to-image translation generative adversarial network) called BiTrackGAN. By bottom-up training, it induces an ideal intermediate state between these two CycleGAN blocks, namely the constraint mechanism. Experimental results show that BiTrackGAN achieves more reasonable and diverse cross-age facial synthesis than other CycleGAN-related methods. As far as we know, it is a novel and effective constraint mechanism for more reason and accurate aging synthesis through the CycleGAN approach.
Development of A Real-time POCUS Image Quality Assessment and Acquisition Guidance System
Dec 19, 2022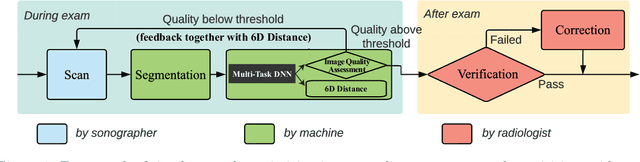
Point-of-care ultrasound (POCUS) is one of the most commonly applied tools for cardiac function imaging in the clinical routine of the emergency department and pediatric intensive care unit. The prior studies demonstrate that AI-assisted software can guide nurses or novices without prior sonography experience to acquire POCUS by recognizing the interest region, assessing image quality, and providing instructions. However, these AI algorithms cannot simply replace the role of skilled sonographers in acquiring diagnostic-quality POCUS. Unlike chest X-ray, CT, and MRI, which have standardized imaging protocols, POCUS can be acquired with high inter-observer variability. Though being with variability, they are usually all clinically acceptable and interpretable. In challenging clinical environments, sonographers employ novel heuristics to acquire POCUS in complex scenarios. To help novice learners to expedite the training process while reducing the dependency on experienced sonographers in the curriculum implementation, We will develop a framework to perform real-time AI-assisted quality assessment and probe position guidance to provide training process for novice learners with less manual intervention.