 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning with Synthetic Positives
Aug 30, 2024Contrastive learning with the nearest neighbor has proved to be one of the most efficient self-supervised learning (SSL) techniques by utilizing the similarity of multiple instances within the same class. However, its efficacy is constrained as the nearest neighbor algorithm primarily identifies ``easy'' positive pairs, where the representations are already closely located in the embedding space. In this paper, we introduce a novel approach called Contrastive Learning with Synthetic Positives (CLSP) that utilizes synthetic images, generated by an unconditional diffusion model, as the additional positives to help the model learn from diverse positives. Through feature interpolation in the diffusion model sampling process, we generate images with distinct backgrounds yet similar semantic content to the anchor image. These images are considered ``hard'' positives for the anchor image, and when included as supplementary positives in the contrastive loss, they contribute to a performance improvement of over 2\% and 1\% in linear evaluation compared to the previous NNCLR and All4One methods across multiple benchmark datasets such as CIFAR10, achieving state-of-the-art methods. On transfer learning benchmarks, CLSP outperforms existing SSL frameworks on 6 out of 8 downstream datasets. We believe CLSP establishes a valuable baseline for future SSL studies incorporating synthetic data in the training process.
Enhancing 3D Transformer Segmentation Model for Medical Image with Token-level Representation Learning
Aug 12, 2024In the field of medical images, although various works find Swin Transformer has promising effectiveness on pixelwise dense prediction, whether pre-training these models without using extra dataset can further boost the performance for the downstream semantic segmentation remains unexplored.Applications of previous representation learning methods are hindered by the limited number of 3D volumes and high computational cost. In addition, most of pretext tasks designed specifically for Transformer are not applicable to hierarchical structure of Swin Transformer. Thus, this work proposes a token-level representation learning loss that maximizes agreement between token embeddings from different augmented views individually instead of volume-level global features. Moreover, we identify a potential representation collapse exclusively caused by this new loss. To prevent collapse, we invent a simple "rotate-and-restore" mechanism, which rotates and flips one augmented view of input volume, and later restores the order of tokens in the feature maps. We also modify the contrastive loss to address the discrimination between tokens at the same position but from different volumes. We test our pre-training scheme on two public medical segmentation datasets, and the results on the downstream segmentation task show more improvement of our methods than other state-of-the-art pre-trainig methods.
AME-CAM: Attentive Multiple-Exit CAM for Weakly Supervised Segmentation on MRI Brain Tumor
Jun 26, 2023Magnetic resonance imaging (MRI) is commonly used for brain tumor segmentation, which is critical for patient evaluation and treatment planning. To reduce the labor and expertise required for labeling, weakly-supervised semantic segmentation (WSSS) methods with class activation mapping (CAM) have been proposed. However, existing CAM methods suffer from low resolution due to strided convolution and pooling layers, resulting in inaccurate predictions. In this study, we propose a novel CAM method, Attentive Multiple-Exit CAM (AME-CAM), that extracts activation maps from multiple resolutions to hierarchically aggregate and improve prediction accuracy. We evaluate our method on the BraTS 2021 dataset and show that it outperforms state-of-the-art methods.
How to Efficiently Adapt Large Segmentation Model(SAM) to Medical Images
Jun 23, 2023

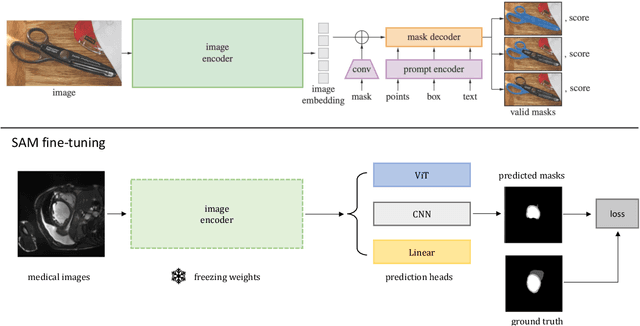

The emerging scale segmentation model, Segment Anything (SAM), exhibits impressive capabilities in zero-shot segmentation for natural images. However, when applied to medical images, SAM suffers from noticeable performance drop. To make SAM a real ``foundation model" for the computer vision community, it is critical to find an efficient way to customize SAM for medical image dataset. In this work, we propose to freeze SAM encoder and finetune a lightweight task-specific prediction head, as most of weights in SAM are contributed by the encoder. In addition, SAM is a promptable model, while prompt is not necessarily available in all application cases, and precise prompts for multiple class segmentation are also time-consuming. Therefore, we explore three types of prompt-free prediction heads in this work, include ViT, CNN, and linear layers. For ViT head, we remove the prompt tokens in the mask decoder of SAM, which is named AutoSAM. AutoSAM can also generate masks for different classes with one single inference after modification. To evaluate the label-efficiency of our finetuning method, we compare the results of these three prediction heads on a public medical image segmentation dataset with limited labeled data. Experiments demonstrate that finetuning SAM significantly improves its performance on medical image dataset, even with just one labeled volume. Moreover, AutoSAM and CNN prediction head also has better segmentation accuracy than training from scratch and self-supervised learning approaches when there is a shortage of annotations.
Conditional Diffusion Models for Weakly Supervised Medical Image Segmentation
Jun 06, 2023



Recent advances in denoising diffusion probabilistic models have shown great success in image synthesis tasks. While there are already works exploring the potential of this powerful tool in image semantic segmentation, its application in weakly supervised semantic segmentation (WSSS) remains relatively under-explored. Observing that conditional diffusion models (CDM) is capable of generating images subject to specific distributions, in this work, we utilize category-aware semantic information underlied in CDM to get the prediction mask of the target object with only image-level annotations. More specifically, we locate the desired class by approximating the derivative of the output of CDM w.r.t the input condition. Our method is different from previous diffusion model methods with guidance from an external classifier, which accumulates noises in the background during the reconstruction process. Our method outperforms state-of-the-art CAM and diffusion model methods on two public medical image segmentation datasets, which demonstrates that CDM is a promising tool in WSSS. Also, experiment shows our method is more time-efficient than existing diffusion model methods, making it practical for wider applications.
Additional Positive Enables Better Representation Learning for Medical Images
May 31, 2023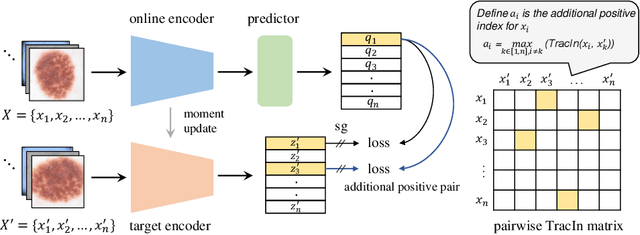
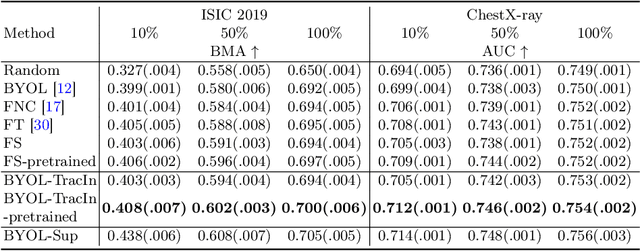
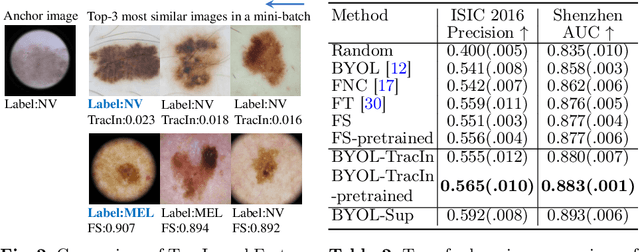
This paper presents a new way to identify additional positive pairs for BYOL, a state-of-the-art (SOTA) self-supervised learning framework, to improve its representation learning ability. Unlike conventional BYOL which relies on only one positive pair generated by two augmented views of the same image, we argue that information from different images with the same label can bring more diversity and variations to the target features, thus benefiting representation learning. To identify such pairs without any label, we investigate TracIn, an instance-based and computationally efficient influence function, for BYOL training. Specifically, TracIn is a gradient-based method that reveals the impact of a training sample on a test sample in supervised learning. We extend it to the self-supervised learning setting and propose an efficient batch-wise per-sample gradient computation method to estimate the pairwise TracIn to represent the similarity of samples in the mini-batch during training. For each image, we select the most similar sample from other images as the additional positive and pull their features together with BYOL loss. Experimental results on two public medical datasets (i.e., ISIC 2019 and ChestX-ray) demonstrate that the proposed method can improve the classification performance compared to other competitive baselines in both semi-supervised and transfer learning settings.
Unsupervised Feature Clustering Improves Contrastive Representation Learning for Medical Image Segmentation
Nov 15, 2022Self-supervised instance discrimination is an effective contrastive pretext task to learn feature representations and address limited medical image annotations. The idea is to make features of transformed versions of the same images similar while forcing all other augmented images' representations to contrast. However, this instance-based contrastive learning leaves performance on the table by failing to maximize feature affinity between images with similar content while counter-productively pushing their representations apart. Recent improvements on this paradigm (e.g., leveraging multi-modal data, different images in longitudinal studies, spatial correspondences) either relied on additional views or made stringent assumptions about data properties, which can sacrifice generalizability and applicability. To address this challenge, we propose a new self-supervised contrastive learning method that uses unsupervised feature clustering to better select positive and negative image samples. More specifically, we produce pseudo-classes by hierarchically clustering features obtained by an auto-encoder in an unsupervised manner, and prevent destructive interference during contrastive learning by avoiding the selection of negatives from the same pseudo-class. Experiments on 2D skin dermoscopic image segmentation and 3D multi-class whole heart CT segmentation demonstrate that our method outperforms state-of-the-art self-supervised contrastive techniques on these tasks.
Contrastive Image Synthesis and Self-supervised Feature Adaptation for Cross-Modality Biomedical Image Segmentation
Jul 27, 2022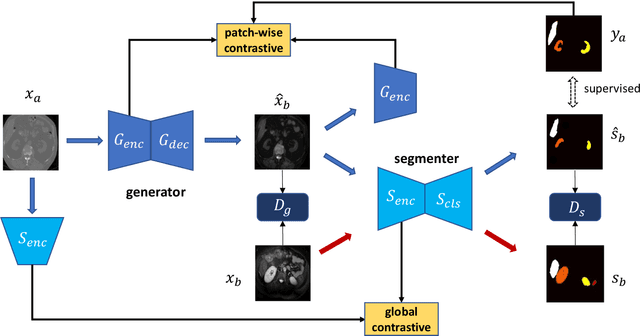
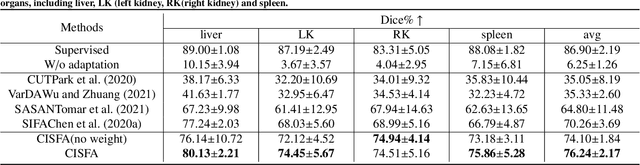

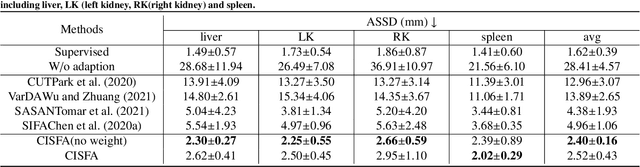
This work presents a novel framework CISFA (Contrastive Image synthesis and Self-supervised Feature Adaptation)that builds on image domain translation and unsupervised feature adaptation for cross-modality biomedical image segmentation. Different from existing works, we use a one-sided generative model and add a weighted patch-wise contrastive loss between sampled patches of the input image and the corresponding synthetic image, which serves as shape constraints. Moreover, we notice that the generated images and input images share similar structural information but are in different modalities. As such, we enforce contrastive losses on the generated images and the input images to train the encoder of a segmentation model to minimize the discrepancy between paired images in the learned embedding space. Compared with existing works that rely on adversarial learning for feature adaptation, such a method enables the encoder to learn domain-independent features in a more explicit way. We extensively evaluate our methods on segmentation tasks containing CT and MRI images for abdominal cavities and whole hearts. Experimental results show that the proposed framework not only outputs synthetic images with less distortion of organ shapes, but also outperforms state-of-the-art domain adaptation methods by a large margin.
Semi-supervised Contrastive Learning for Label-efficient Medical Image Segmentation
Sep 28, 2021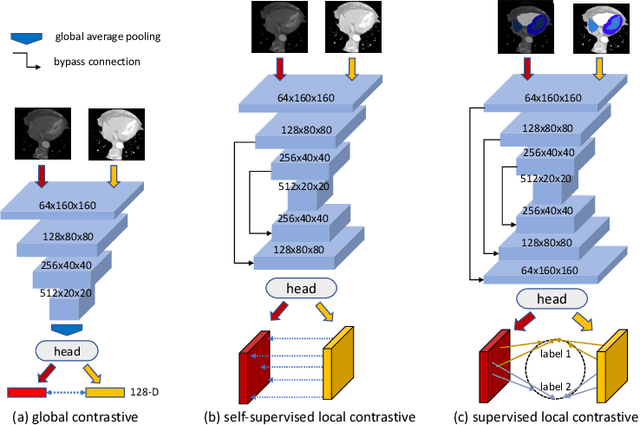

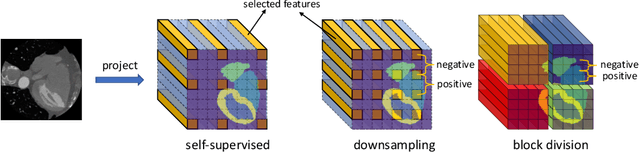

The success of deep learning methods in medical image segmentation tasks heavily depends on a large amount of labeled data to supervise the training. On the other hand, the annotation of biomedical images requires domain knowledge and can be laborious. Recently, contrastive learning has demonstrated great potential in learning latent representation of images even without any label. Existing works have explored its application to biomedical image segmentation where only a small portion of data is labeled, through a pre-training phase based on self-supervised contrastive learning without using any labels followed by a supervised fine-tuning phase on the labeled portion of data only. In this paper, we establish that by including the limited label in formation in the pre-training phase, it is possible to boost the performance of contrastive learning. We propose a supervised local contrastive loss that leverages limited pixel-wise annotation to force pixels with the same label to gather around in the embedding space. Such loss needs pixel-wise computation which can be expensive for large images, and we further propose two strategies, downsampling and block division, to address the issue. We evaluate our methods on two public biomedical image datasets of different modalities. With different amounts of labeled data, our methods consistently outperform the state-of-the-art contrast-based methods and other semi-supervised learning techniques.
Context-guided Triple Matching for Multiple Choice Question Answering
Sep 27, 2021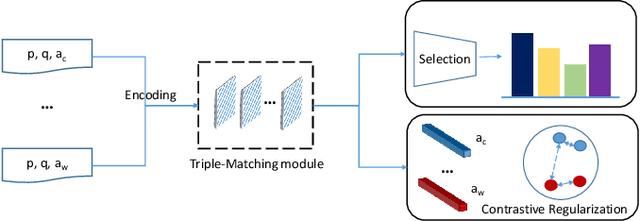
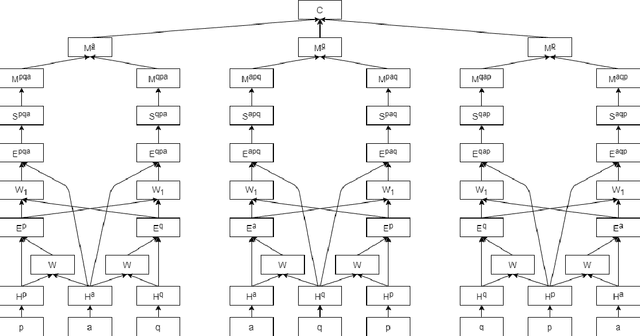

The task of multiple choice question answering (MCQA) refers to identifying a suitable answer from multiple candidates, by estimating the matching score among the triple of the passage, question and answer. Despite the general research interest in this regard, existing methods decouple the process into several pair-wise or dual matching steps, that limited the ability of assessing cases with multiple evidence sentences. To alleviate this issue, this paper introduces a novel Context-guided Triple Matching algorithm, which is achieved by integrating a Triple Matching (TM) module and a Contrastive Regularization (CR). The former is designed to enumerate one component from the triple as the background context, and estimate its semantic matching with the other two. Additionally, the contrastive term is further proposed to capture the dissimilarity between the correct answer and distractive ones. We validate the proposed algorithm on several benchmarking MCQA datasets, which exhibits competitive performances against state-of-the-arts.