 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Efficiently Adapt Large Segmentation Model(SAM) to Medical Images
Paper and Code


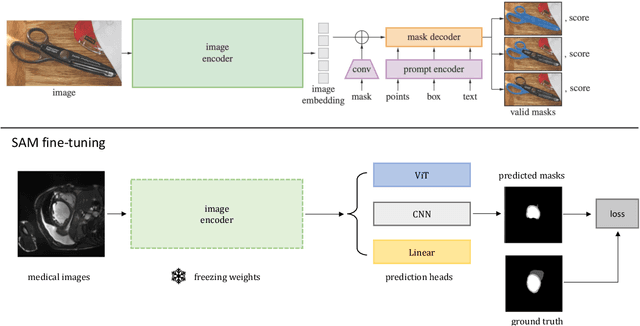

The emerging scale segmentation model, Segment Anything (SAM), exhibits impressive capabilities in zero-shot segmentation for natural images. However, when applied to medical images, SAM suffers from noticeable performance drop. To make SAM a real ``foundation model" for the computer vision community, it is critical to find an efficient way to customize SAM for medical image dataset. In this work, we propose to freeze SAM encoder and finetune a lightweight task-specific prediction head, as most of weights in SAM are contributed by the encoder. In addition, SAM is a promptable model, while prompt is not necessarily available in all application cases, and precise prompts for multiple class segmentation are also time-consuming. Therefore, we explore three types of prompt-free prediction heads in this work, include ViT, CNN, and linear layers. For ViT head, we remove the prompt tokens in the mask decoder of SAM, which is named AutoSAM. AutoSAM can also generate masks for different classes with one single inference after modification. To evaluate the label-efficiency of our finetuning method, we compare the results of these three prediction heads on a public medical image segmentation dataset with limited labeled data. Experiments demonstrate that finetuning SAM significantly improves its performance on medical image dataset, even with just one labeled volume. Moreover, AutoSAM and CNN prediction head also has better segmentation accuracy than training from scratch and self-supervised learning approaches when there is a shortage of annotations.