 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Machine Learning for Football Performance Analysis: Evidence of Limited Transferability from Elite Leagues to University Competition
May 11, 2026Machine learning has become increasingly prevalent in football performance analysis, yet most studies prioritize predictive accuracy while implicitly assuming that learned performance determinants and their interpretations are transferable across competition levels. Whether interpretability remains reliable under domain shift-from elite to university football remains largely unexplored. This study investigates whether performance determinants learned from elite competitions are structurally transferable to university-level football and whether their interpretations remain robust under domain shift. Models were trained on large-scale event data from the top five European leagues and applied to university football data from National Tsing Hua University (NTHU) using an identical feature space. Random Forest and Multilayer Perceptron models were interpreted using SHapley Additive exPlanations (SHAP) and Counterfactual Impact Score (CIS). Across five experiments, elite football exhibited a stable and consistent hierarchy of performance determinants across leagues, models, and explanation methods. In contrast, NTHU university football showed substantial reordering of key indicators, reduced explanation stability, weaker structural agreement with elite domains, and increased sensitivity to explanation method. These findings suggest that interpretability robustness is domain-dependent. Rather than reflecting methodological limitations alone, instability in explanations under domain shift may serve as a diagnostic signal of structural ambiguity in the target domain.
H-CNN-ViT: A Hierarchical Gated Attention Multi-Branch Model for Bladder Cancer Recurrence Prediction
Nov 19, 2025Bladder cancer is one of the most prevalent malignancies worldwide, with a recurrence rate of up to 78%, necessitating accurate post-operative monitoring for effective patient management. Multi-sequence contrast-enhanced MRI is commonly used for recurrence detection; however, interpreting these scans remains challenging, even for experienced radiologists, due to post-surgical alterations such as scarring, swelling, and tissue remodeling. AI-assisted diagnostic tools have shown promise in improving bladder cancer recurrence prediction, yet progress in this field is hindered by the lack of dedicated multi-sequence MRI datasets for recurrence assessment study. In this work, we first introduce a curated multi-sequence, multi-modal MRI dataset specifically designed for bladder cancer recurrence prediction, establishing a valuable benchmark for future research. We then propose H-CNN-ViT, a new Hierarchical Gated Attention Multi-Branch model that enables selective weighting of features from the global (ViT) and local (CNN) paths based on contextual demands, achieving a balanced and targeted feature fusion. Our multi-branch architecture processes each modality independently, ensuring that the unique properties of each imaging channel are optimally captured and integrated. Evaluated on our dataset, H-CNN-ViT achieves an AUC of 78.6%, surpassing state-of-the-art models. Our model is publicly available at https://github.com/XLIAaron/H-CNN-ViT.
Unsupervised Out-of-Distribution Detection in Medical Imaging Using Multi-Exit Class Activation Maps and Feature Masking
May 13, 2025Out-of-distribution (OOD) detection is essential for ensuring the reliability of deep learning models in medical imaging applications. This work is motivated by the observation that class activation maps (CAMs) for in-distribution (ID) data typically emphasize regions that are highly relevant to the model's predictions, whereas OOD data often lacks such focused activations. By masking input images with inverted CAMs, the feature representations of ID data undergo more substantial changes compared to those of OOD data, offering a robust criterion for differentiation. In this paper, we introduce a novel unsupervised OOD detection framework, Multi-Exit Class Activation Map (MECAM), which leverages multi-exit CAMs and feature masking. By utilizing mult-exit networks that combine CAMs from varying resolutions and depths, our method captures both global and local feature representations, thereby enhancing the robustness of OOD detection. We evaluate MECAM on multiple ID datasets, including ISIC19 and PathMNIST, and test its performance against three medical OOD datasets, RSNA Pneumonia, COVID-19, and HeadCT, and one natural image OOD dataset, iSUN. Comprehensive comparisons with state-of-the-art OOD detection methods validate the effectiveness of our approach. Our findings emphasize the potential of multi-exit networks and feature masking for advancing unsupervised OOD detection in medical imaging, paving the way for more reliable and interpretable models in clinical practice.
Achieving Fairness Through Channel Pruning for Dermatological Disease Diagnosis
May 14, 2024

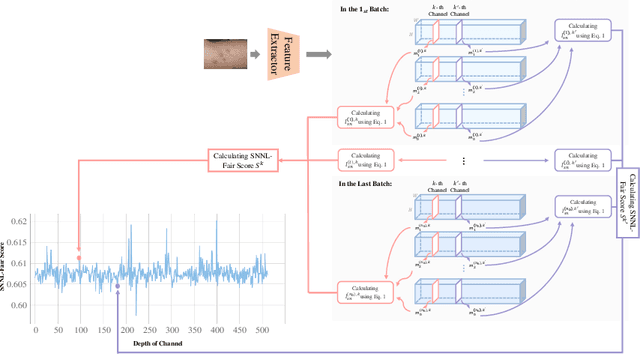

Numerous studies have revealed that deep learning-based medical image classification models may exhibit bias towards specific demographic attributes, such as race, gender, and age. Existing bias mitigation methods often achieve high level of fairness at the cost of significant accuracy degradation. In response to this challenge, we propose an innovative and adaptable Soft Nearest Neighbor Loss-based channel pruning framework, which achieves fairness through channel pruning. Traditionally, channel pruning is utilized to accelerate neural network inference. However, our work demonstrates that pruning can also be a potent tool for achieving fairness. Our key insight is that different channels in a layer contribute differently to the accuracy of different groups. By selectively pruning critical channels that lead to the accuracy difference between the privileged and unprivileged groups, we can effectively improve fairness without sacrificing accuracy significantly. Experiments conducted on two skin lesion diagnosis datasets across multiple sensitive attributes validate the effectiveness of our method in achieving state-of-the-art trade-off between accuracy and fairness. Our code is available at https://github.com/Kqp1227/Sensitive-Channel-Pruning.
Toward Fairness via Maximum Mean Discrepancy Regularization on Logits Space
Feb 20, 2024Fairness has become increasingly pivotal in machine learning for high-risk applications such as machine learning in healthcare and facial recognition. However, we see the deficiency in the previous logits space constraint methods. Therefore, we propose a novel framework, Logits-MMD, that achieves the fairness condition by imposing constraints on output logits with Maximum Mean Discrepancy. Moreover, quantitative analysis and experimental results show that our framework has a better property that outperforms previous methods and achieves state-of-the-art on two facial recognition datasets and one animal dataset. Finally, we show experimental results and demonstrate that our debias approach achieves the fairness condition effectively.
Achieve Fairness without Demographics for Dermatological Disease Diagnosis
Jan 16, 2024In medical image diagnosis, fairness has become increasingly crucial. Without bias mitigation, deploying unfair AI would harm the interests of the underprivileged population and potentially tear society apart. Recent research addresses prediction biases in deep learning models concerning demographic groups (e.g., gender, age, and race) by utilizing demographic (sensitive attribute) information during training. However, many sensitive attributes naturally exist in dermatological disease images. If the trained model only targets fairness for a specific attribute, it remains unfair for other attributes. Moreover, training a model that can accommodate multiple sensitive attributes is impractical due to privacy concerns. To overcome this, we propose a method enabling fair predictions for sensitive attributes during the testing phase without using such information during training. Inspired by prior work highlighting the impact of feature entanglement on fairness, we enhance the model features by capturing the features related to the sensitive and target attributes and regularizing the feature entanglement between corresponding classes. This ensures that the model can only classify based on the features related to the target attribute without relying on features associated with sensitive attributes, thereby improving fairness and accuracy. Additionally, we use disease masks from the Segment Anything Model (SAM) to enhance the quality of the learned feature. Experimental results demonstrate that the proposed method can improve fairness in classification compared to state-of-the-art methods in two dermatological disease datasets.
Toward Fairness Through Fair Multi-Exit Framework for Dermatological Disease Diagnosis
Jul 01, 2023Fairness has become increasingly pivotal in medical image recognition. However, without mitigating bias, deploying unfair medical AI systems could harm the interests of underprivileged populations. In this paper, we observe that while features extracted from the deeper layers of neural networks generally offer higher accuracy, fairness conditions deteriorate as we extract features from deeper layers. This phenomenon motivates us to extend the concept of multi-exit frameworks. Unlike existing works mainly focusing on accuracy, our multi-exit framework is fairness-oriented; the internal classifiers are trained to be more accurate and fairer, with high extensibility to apply to most existing fairness-aware frameworks. During inference, any instance with high confidence from an internal classifier is allowed to exit early. Experimental results show that the proposed framework can improve the fairness condition over the state-of-the-art in two dermatological disease datasets.
AME-CAM: Attentive Multiple-Exit CAM for Weakly Supervised Segmentation on MRI Brain Tumor
Jun 26, 2023Magnetic resonance imaging (MRI) is commonly used for brain tumor segmentation, which is critical for patient evaluation and treatment planning. To reduce the labor and expertise required for labeling, weakly-supervised semantic segmentation (WSSS) methods with class activation mapping (CAM) have been proposed. However, existing CAM methods suffer from low resolution due to strided convolution and pooling layers, resulting in inaccurate predictions. In this study, we propose a novel CAM method, Attentive Multiple-Exit CAM (AME-CAM), that extracts activation maps from multiple resolutions to hierarchically aggregate and improve prediction accuracy. We evaluate our method on the BraTS 2021 dataset and show that it outperforms state-of-the-art methods.
A Novel Confidence Induced Class Activation Mapping for MRI Brain Tumor Segmentation
Jun 26, 2023



Magnetic resonance imaging (MRI) is a commonly used technique for brain tumor segmentation, which is critical for evaluating patients and planning treatment. To make the labeling process less laborious and dependent on expertise, weakly-supervised semantic segmentation (WSSS) methods using class activation mapping (CAM) have been proposed. However, current CAM-based WSSS methods generate the object localization map using internal neural network information, such as gradient or trainable parameters, which can lead to suboptimal solutions. To address these issues, we propose the confidence-induced CAM (Cfd-CAM), which calculates the weight of each feature map by using the confidence of the target class. Our experiments on two brain tumor datasets show that Cfd-CAM outperforms existing state-of-the-art methods under the same level of supervision. Overall, our proposed Cfd-CAM approach improves the accuracy of brain tumor segmentation and may provide valuable insights for developing better WSSS methods for other medical imaging tasks.
Conditional Diffusion Models for Weakly Supervised Medical Image Segmentation
Jun 06, 2023



Recent advances in denoising diffusion probabilistic models have shown great success in image synthesis tasks. While there are already works exploring the potential of this powerful tool in image semantic segmentation, its application in weakly supervised semantic segmentation (WSSS) remains relatively under-explored. Observing that conditional diffusion models (CDM) is capable of generating images subject to specific distributions, in this work, we utilize category-aware semantic information underlied in CDM to get the prediction mask of the target object with only image-level annotations. More specifically, we locate the desired class by approximating the derivative of the output of CDM w.r.t the input condition. Our method is different from previous diffusion model methods with guidance from an external classifier, which accumulates noises in the background during the reconstruction process. Our method outperforms state-of-the-art CAM and diffusion model methods on two public medical image segmentation datasets, which demonstrates that CDM is a promising tool in WSSS. Also, experiment shows our method is more time-efficient than existing diffusion model methods, making it practical for wider applications.