 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Fairness Through Channel Pruning for Dermatological Disease Diagnosis
May 14, 2024

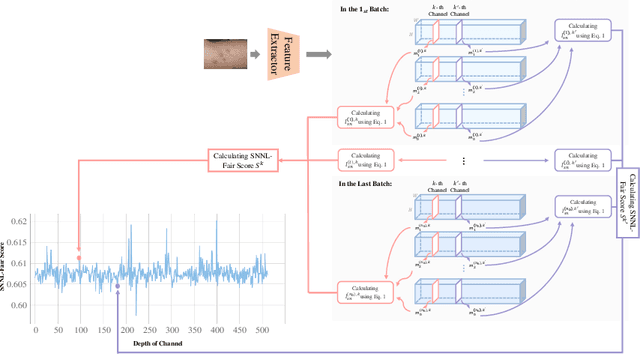

Numerous studies have revealed that deep learning-based medical image classification models may exhibit bias towards specific demographic attributes, such as race, gender, and age. Existing bias mitigation methods often achieve high level of fairness at the cost of significant accuracy degradation. In response to this challenge, we propose an innovative and adaptable Soft Nearest Neighbor Loss-based channel pruning framework, which achieves fairness through channel pruning. Traditionally, channel pruning is utilized to accelerate neural network inference. However, our work demonstrates that pruning can also be a potent tool for achieving fairness. Our key insight is that different channels in a layer contribute differently to the accuracy of different groups. By selectively pruning critical channels that lead to the accuracy difference between the privileged and unprivileged groups, we can effectively improve fairness without sacrificing accuracy significantly. Experiments conducted on two skin lesion diagnosis datasets across multiple sensitive attributes validate the effectiveness of our method in achieving state-of-the-art trade-off between accuracy and fairness. Our code is available at https://github.com/Kqp1227/Sensitive-Channel-Pruning.
Toward Fairness via Maximum Mean Discrepancy Regularization on Logits Space
Feb 20, 2024Fairness has become increasingly pivotal in machine learning for high-risk applications such as machine learning in healthcare and facial recognition. However, we see the deficiency in the previous logits space constraint methods. Therefore, we propose a novel framework, Logits-MMD, that achieves the fairness condition by imposing constraints on output logits with Maximum Mean Discrepancy. Moreover, quantitative analysis and experimental results show that our framework has a better property that outperforms previous methods and achieves state-of-the-art on two facial recognition datasets and one animal dataset. Finally, we show experimental results and demonstrate that our debias approach achieves the fairness condition effectively.
Achieve Fairness without Demographics for Dermatological Disease Diagnosis
Jan 16, 2024In medical image diagnosis, fairness has become increasingly crucial. Without bias mitigation, deploying unfair AI would harm the interests of the underprivileged population and potentially tear society apart. Recent research addresses prediction biases in deep learning models concerning demographic groups (e.g., gender, age, and race) by utilizing demographic (sensitive attribute) information during training. However, many sensitive attributes naturally exist in dermatological disease images. If the trained model only targets fairness for a specific attribute, it remains unfair for other attributes. Moreover, training a model that can accommodate multiple sensitive attributes is impractical due to privacy concerns. To overcome this, we propose a method enabling fair predictions for sensitive attributes during the testing phase without using such information during training. Inspired by prior work highlighting the impact of feature entanglement on fairness, we enhance the model features by capturing the features related to the sensitive and target attributes and regularizing the feature entanglement between corresponding classes. This ensures that the model can only classify based on the features related to the target attribute without relying on features associated with sensitive attributes, thereby improving fairness and accuracy. Additionally, we use disease masks from the Segment Anything Model (SAM) to enhance the quality of the learned feature. Experimental results demonstrate that the proposed method can improve fairness in classification compared to state-of-the-art methods in two dermatological disease datasets.
Toward Fairness Through Fair Multi-Exit Framework for Dermatological Disease Diagnosis
Jul 01, 2023Fairness has become increasingly pivotal in medical image recognition. However, without mitigating bias, deploying unfair medical AI systems could harm the interests of underprivileged populations. In this paper, we observe that while features extracted from the deeper layers of neural networks generally offer higher accuracy, fairness conditions deteriorate as we extract features from deeper layers. This phenomenon motivates us to extend the concept of multi-exit frameworks. Unlike existing works mainly focusing on accuracy, our multi-exit framework is fairness-oriented; the internal classifiers are trained to be more accurate and fairer, with high extensibility to apply to most existing fairness-aware frameworks. During inference, any instance with high confidence from an internal classifier is allowed to exit early. Experimental results show that the proposed framework can improve the fairness condition over the state-of-the-art in two dermatological disease datasets.
Fair Multi-Exit Framework for Facial Attribute Classification
Jan 08, 2023



Fairness has become increasingly pivotal in facial recognition. Without bias mitigation, deploying unfair AI would harm the interest of the underprivileged population. In this paper, we observe that though the higher accuracy that features from the deeper layer of a neural networks generally offer, fairness conditions deteriorate as we extract features from deeper layers. This phenomenon motivates us to extend the concept of multi-exit framework. Unlike existing works mainly focusing on accuracy, our multi-exit framework is fairness-oriented, where the internal classifiers are trained to be more accurate and fairer. During inference, any instance with high confidence from an internal classifier is allowed to exit early. Moreover, our framework can be applied to most existing fairness-aware frameworks. Experiment results show that the proposed framework can largely improve the fairness condition over the state-of-the-art in CelebA and UTK Face datasets.