 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentative Image Feature Extraction via Contrastive Learning Pretraining for Chest X-ray Report Generation
Sep 04, 2022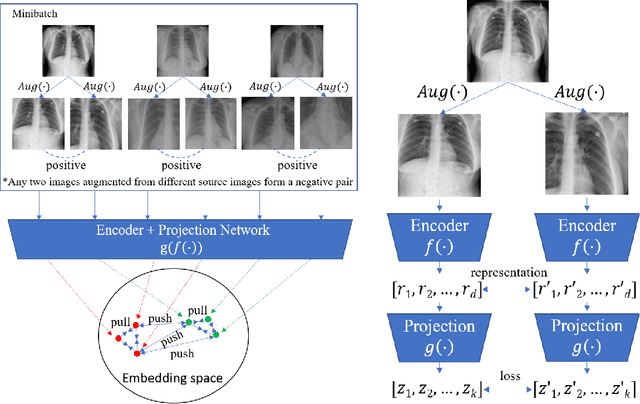
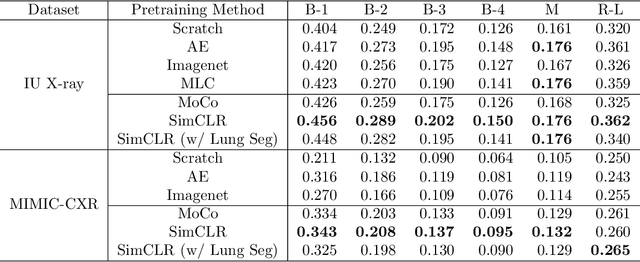

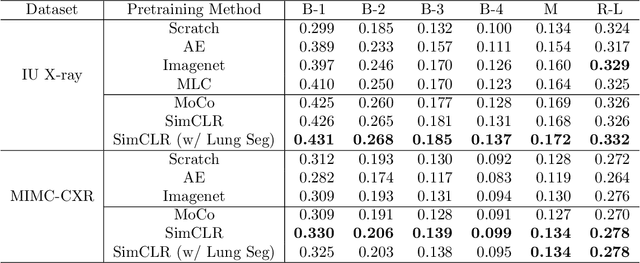
Medical report generation is a challenging task since it is time-consuming and requires expertise from experienced radiologists. The goal of medical report generation is to accurately capture and describe the image findings. Previous works pretrain their visual encoding neural networks with large datasets in different domains, which cannot learn general visual representation in the specific medical domain. In this work, we propose a medical report generation framework that uses a contrastive learning approach to pretrain the visual encoder and requires no additional meta information. In addition, we adopt lung segmentation as an augmentation method in the contrastive learning framework. This segmentation guides the network to focus on encoding the visual feature within the lung region. Experimental results show that the proposed framework improves the performance and the quality of the generated medical reports both quantitatively and qualitatively.