 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cascaded Approach for ultraly High Performance Lesion Detection and False Positive Removal in Liver CT Scans
Jun 28, 2023Liver cancer has high morbidity and mortality rates in the world. Multi-phase CT is a main medical imaging modality for detecting/identifying and diagnosing liver tumors. Automatically detecting and classifying liver lesions in CT images have the potential to improve the clinical workflow. This task remains challenging due to liver lesions' large variations in size, appearance, image contrast, and the complexities of tumor types or subtypes. In this work, we customize a multi-object labeling tool for multi-phase CT images, which is used to curate a large-scale dataset containing 1,631 patients with four-phase CT images, multi-organ masks, and multi-lesion (six major types of liver lesions confirmed by pathology) masks. We develop a two-stage liver lesion detection pipeline, where the high-sensitivity detecting algorithms in the first stage discover as many lesion proposals as possible, and the lesion-reclassification algorithms in the second stage remove as many false alarms as possible. The multi-sensitivity lesion detection algorithm maximizes the information utilization of the individual probability maps of segmentation, and the lesion-shuffle augmentation effectively explores the texture contrast between lesions and the liver. Independently tested on 331 patient cases, the proposed model achieves high sensitivity and specificity for malignancy classification in the multi-phase contrast-enhanced CT (99.2%, 97.1%, diagnosis setting) and in the noncontrast CT (97.3%, 95.7%, screening setting).
Representative Image Feature Extraction via Contrastive Learning Pretraining for Chest X-ray Report Generation
Sep 04, 2022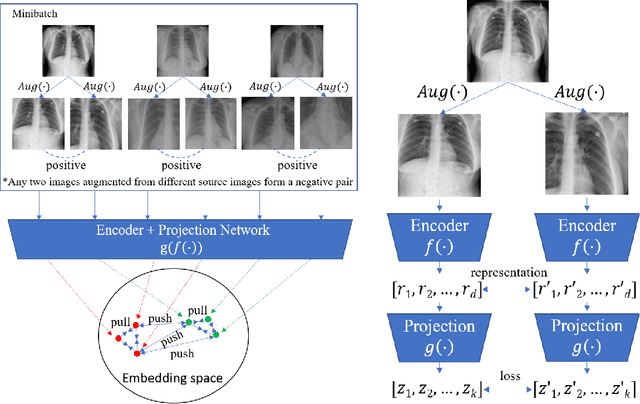
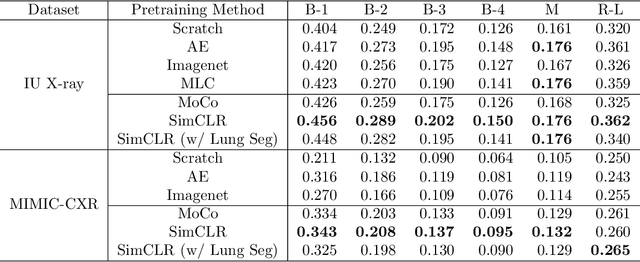

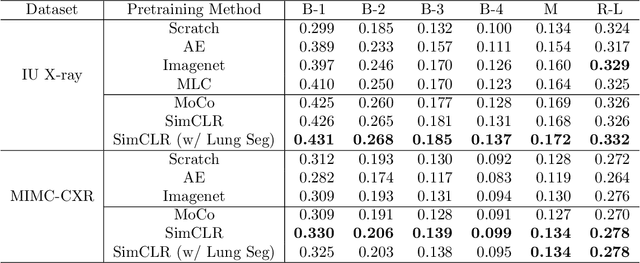
Medical report generation is a challenging task since it is time-consuming and requires expertise from experienced radiologists. The goal of medical report generation is to accurately capture and describe the image findings. Previous works pretrain their visual encoding neural networks with large datasets in different domains, which cannot learn general visual representation in the specific medical domain. In this work, we propose a medical report generation framework that uses a contrastive learning approach to pretrain the visual encoder and requires no additional meta information. In addition, we adopt lung segmentation as an augmentation method in the contrastive learning framework. This segmentation guides the network to focus on encoding the visual feature within the lung region. Experimental results show that the proposed framework improves the performance and the quality of the generated medical reports both quantitatively and qualitatively.
A Flexible Three-Dimensional Hetero-phase Computed Tomography Hepatocellular Carcinoma (HCC) Detection Algorithm for Generalizable and Practical HCC Screening
Aug 17, 2021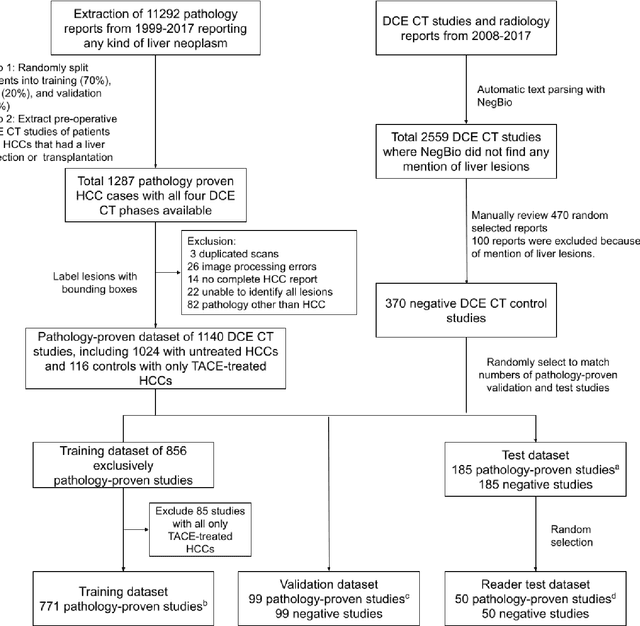
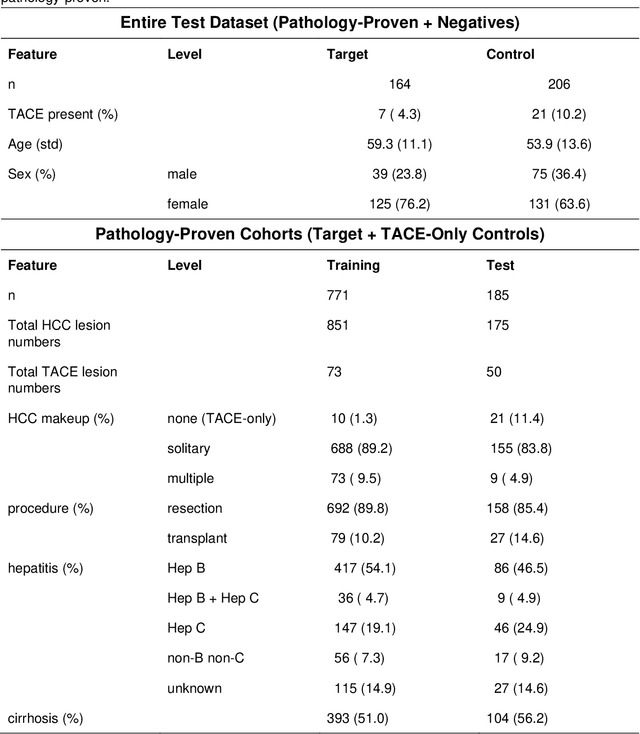
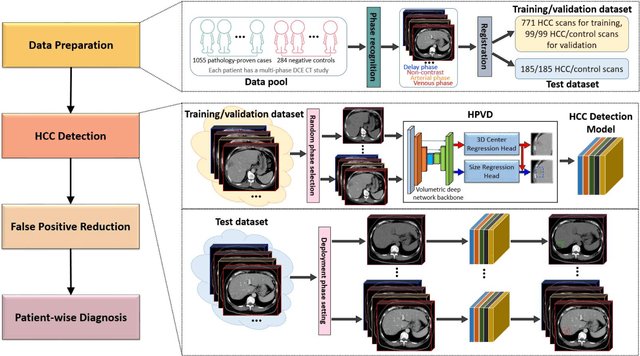
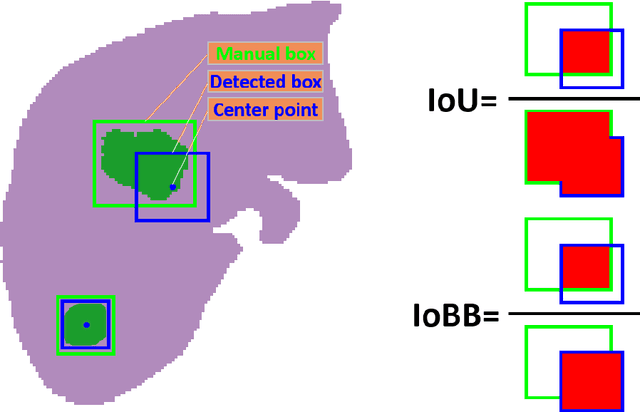
Hepatocellular carcinoma (HCC) can be potentially discovered from abdominal computed tomography (CT) studies under varied clinical scenarios, e.g., fully dynamic contrast enhanced (DCE) studies, non-contrast (NC) plus venous phase (VP) abdominal studies, or NC-only studies. We develop a flexible three-dimensional deep algorithm, called hetero-phase volumetric detection (HPVD), that can accept any combination of contrast-phase inputs and with adjustable sensitivity depending on the clinical purpose. We trained HPVD on 771 DCE CT scans to detect HCCs and tested on external 164 positives and 206 controls, respectively. We compare performance against six clinical readers, including two radiologists, two hepato-pancreatico-biliary (HPB) surgeons, and two hepatologists. The area under curve (AUC) of the localization receiver operating characteristic (LROC) for NC-only, NC plus VP, and full DCE CT yielded 0.71, 0.81, 0.89 respectively. At a high sensitivity operating point of 80% on DCE CT, HPVD achieved 97% specificity, which is comparable to measured physician performance. We also demonstrate performance improvements over more typical and less flexible non hetero-phase detectors. Thus, we demonstrate that a single deep learning algorithm can be effectively applied to diverse HCC detection clinical scenarios.
Deep Implicit Statistical Shape Models for 3D Medical Image Delineation
Apr 07, 2021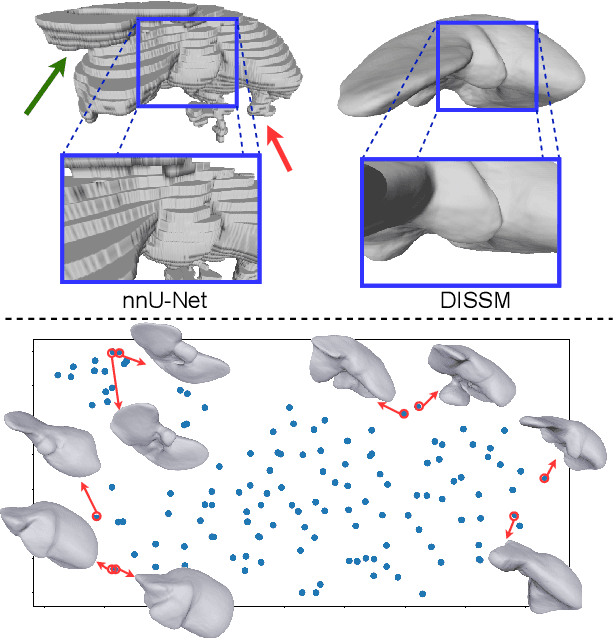
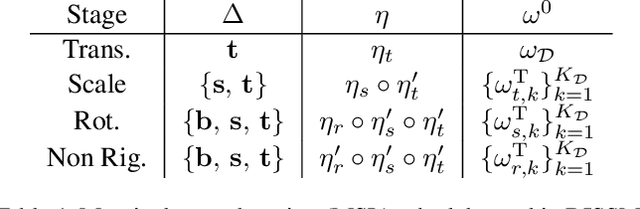
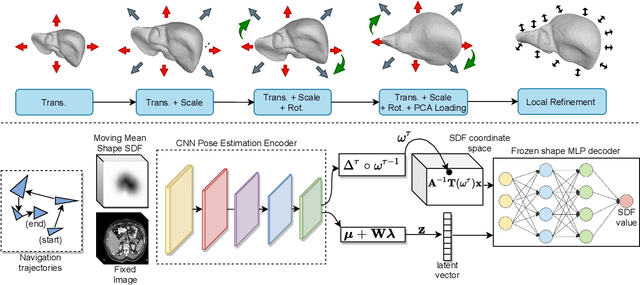

3D delineation of anatomical structures is a cardinal goal in medical imaging analysis. Prior to deep learning, statistical shape models that imposed anatomical constraints and produced high quality surfaces were a core technology. Prior to deep learning, statistical shape models that imposed anatomical constraints and produced high quality surfaces were a core technology. Today fully-convolutional networks (FCNs), while dominant, do not offer these capabilities. We present deep implicit statistical shape models (DISSMs), a new approach to delineation that marries the representation power of convolutional neural networks (CNNs) with the robustness of SSMs. DISSMs use a deep implicit surface representation to produce a compact and descriptive shape latent space that permits statistical models of anatomical variance. To reliably fit anatomically plausible shapes to an image, we introduce a novel rigid and non-rigid pose estimation pipeline that is modelled as a Markov decision process(MDP). We outline a training regime that includes inverted episodic training and a deep realization of marginal space learning (MSL). Intra-dataset experiments on the task of pathological liver segmentation demonstrate that DISSMs can perform more robustly than three leading FCN models, including nnU-Net: reducing the mean Hausdorff distance (HD) by 7.7-14.3mm and improving the worst case Dice-Sorensen coefficient (DSC) by 1.2-2.3%. More critically, cross-dataset experiments on a dataset directly reflecting clinical deployment scenarios demonstrate that DISSMs improve the mean DSC and HD by 3.5-5.9% and 12.3-24.5mm, respectively, and the worst-case DSC by 5.4-7.3%. These improvements are over and above any benefits from representing delineations with high-quality surface.
A New Window Loss Function for Bone Fracture Detection and Localization in X-ray Images with Point-based Annotation
Jan 04, 2021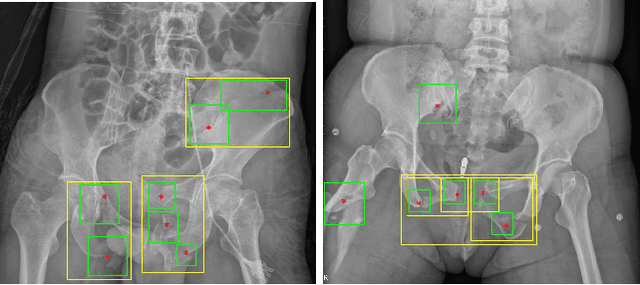
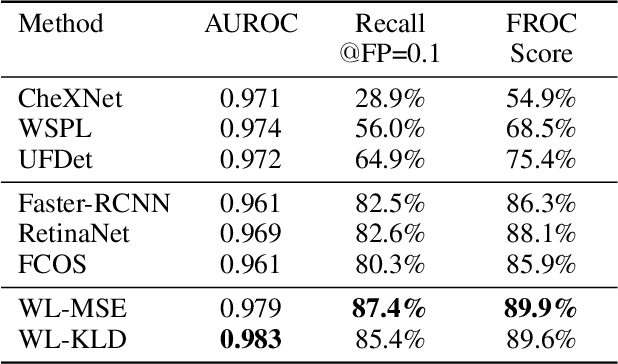
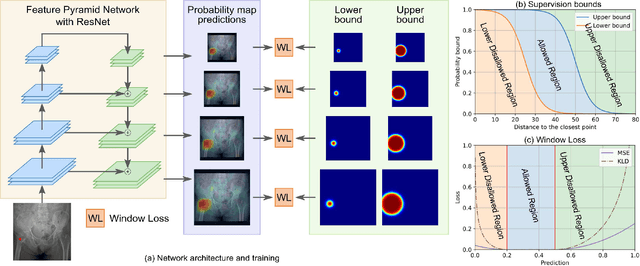
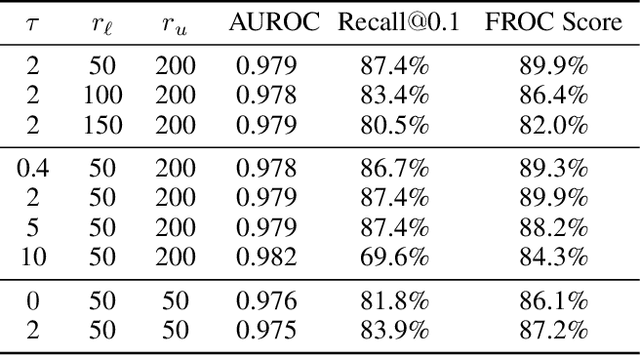
Object detection methods are widely adopted for computer-aided diagnosis using medical images. Anomalous findings are usually treated as objects that are described by bounding boxes. Yet, many pathological findings, e.g., bone fractures, cannot be clearly defined by bounding boxes, owing to considerable instance, shape and boundary ambiguities. This makes bounding box annotations, and their associated losses, highly ill-suited. In this work, we propose a new bone fracture detection method for X-ray images, based on a labor effective and flexible annotation scheme suitable for abnormal findings with no clear object-level spatial extents or boundaries. Our method employs a simple, intuitive, and informative point-based annotation protocol to mark localized pathology information. To address the uncertainty in the fracture scales annotated via point(s), we convert the annotations into pixel-wise supervision that uses lower and upper bounds with positive, negative, and uncertain regions. A novel Window Loss is subsequently proposed to only penalize the predictions outside of the uncertain regions. Our method has been extensively evaluated on 4410 pelvic X-ray images of unique patients. Experiments demonstrate that our method outperforms previous state-of-the-art image classification and object detection baselines by healthy margins, with an AUROC of 0.983 and FROC score of 89.6%.
Deep Volumetric Universal Lesion Detection using Light-Weight Pseudo 3D Convolution and Surface Point Regression
Aug 30, 2020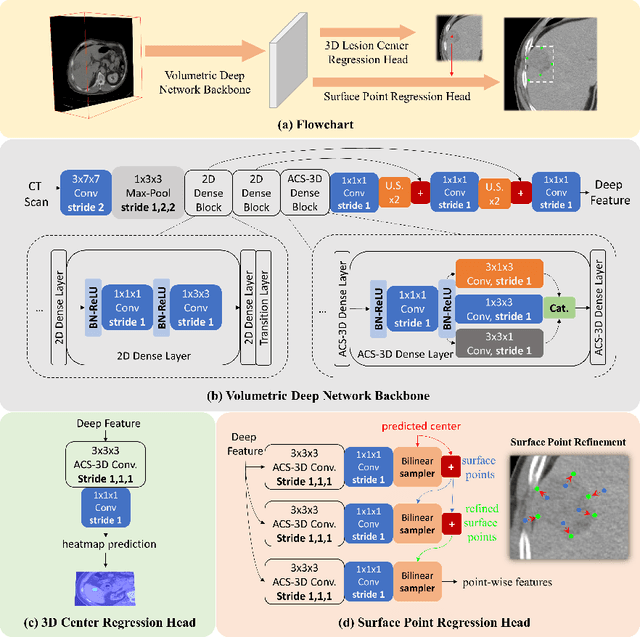
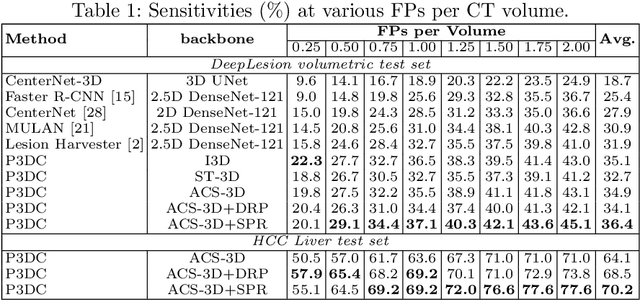

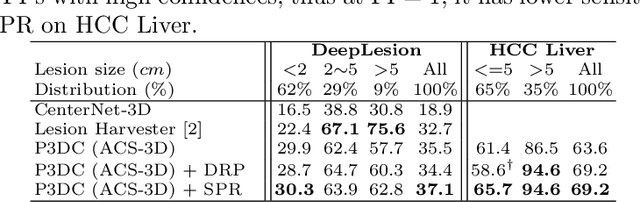
Identifying, measuring and reporting lesions accurately and comprehensively from patient CT scans are important yet time-consuming procedures for physicians. Computer-aided lesion/significant-findings detection techniques are at the core of medical imaging, which remain very challenging due to the tremendously large variability of lesion appearance, location and size distributions in 3D imaging. In this work, we propose a novel deep anchor-free one-stage VULD framework that incorporates (1) P3DC operators to recycle the architectural configurations and pre-trained weights from the off-the-shelf 2D networks, especially ones with large capacities to cope with data variance, and (2) a new SPR method to effectively regress the 3D lesion spatial extents by pinpointing their representative key points on lesion surfaces. Experimental validations are first conducted on the public large-scale NIH DeepLesion dataset where our proposed method delivers new state-of-the-art quantitative performance. We also test VULD on our in-house dataset for liver tumor detection. VULD generalizes well in both large-scale and small-sized tumor datasets in CT imaging.
Anatomy-Aware Siamese Network: Exploiting Semantic Asymmetry for Accurate Pelvic Fracture Detection in X-ray Images
Jul 12, 2020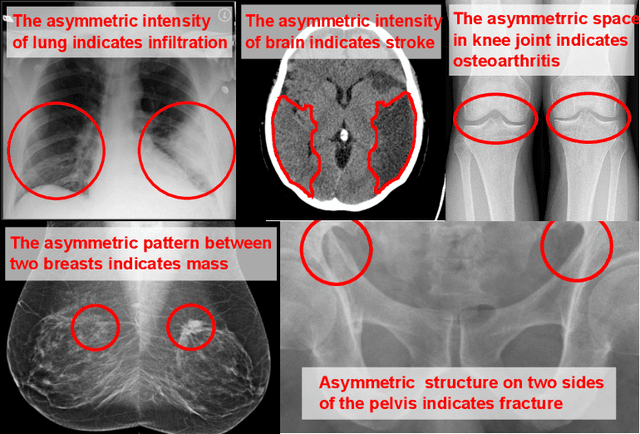
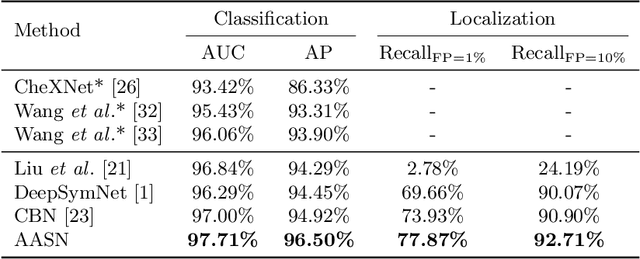
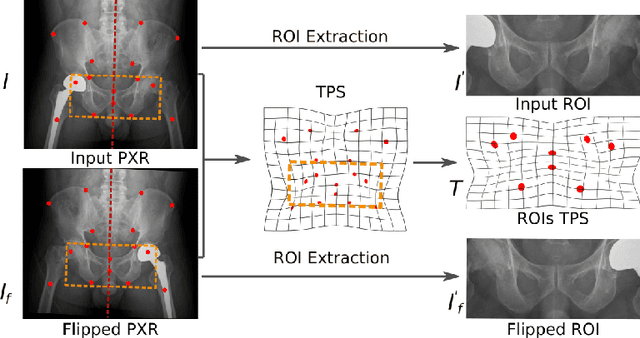
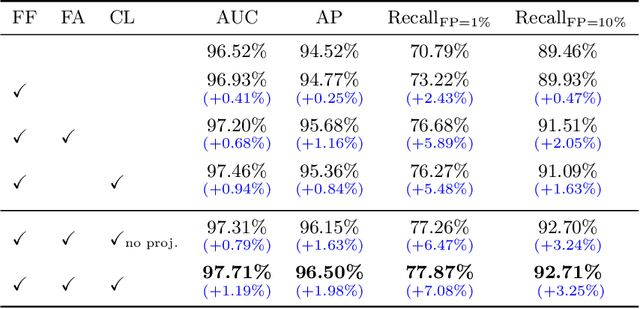
Visual cues of enforcing bilaterally symmetric anatomies as normal findings are widely used in clinical practice to disambiguate subtle abnormalities from medical images. So far, inadequate research attention has been received on effectively emulating this practice in CAD methods. In this work, we exploit semantic anatomical symmetry or asymmetry analysis in a complex CAD scenario, i.e., anterior pelvic fracture detection in trauma PXRs, where semantically pathological (refer to as fracture) and non-pathological (e.g., pose) asymmetries both occur. Visually subtle yet pathologically critical fracture sites can be missed even by experienced clinicians, when limited diagnosis time is permitted in emergency care. We propose a novel fracture detection framework that builds upon a Siamese network enhanced with a spatial transformer layer to holistically analyze symmetric image features. Image features are spatially formatted to encode bilaterally symmetric anatomies. A new contrastive feature learning component in our Siamese network is designed to optimize the deep image features being more salient corresponding to the underlying semantic asymmetries (caused by pelvic fracture occurrences). Our proposed method have been extensively evaluated on 2,359 PXRs from unique patients (the largest study to-date), and report an area under ROC curve score of 0.9771. This is the highest among state-of-the-art fracture detection methods, with improved clinical indications.
Harvesting, Detecting, and Characterizing Liver Lesions from Large-scale Multi-phase CT Data via Deep Dynamic Texture Learning
Jun 28, 2020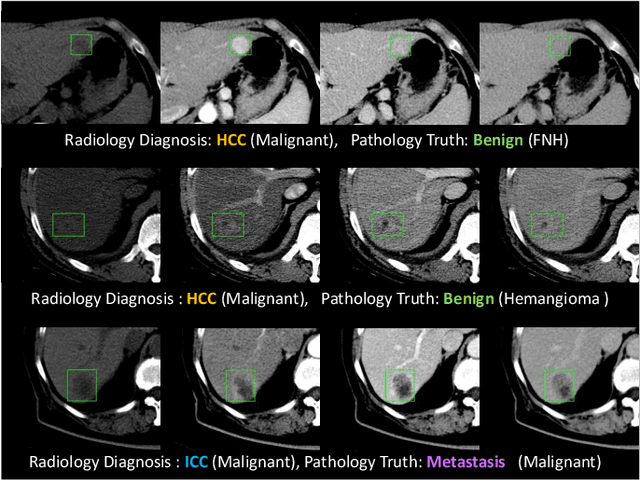
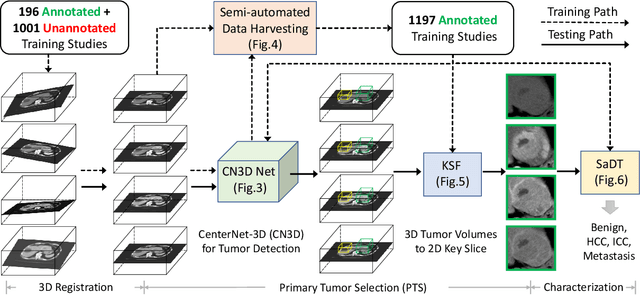
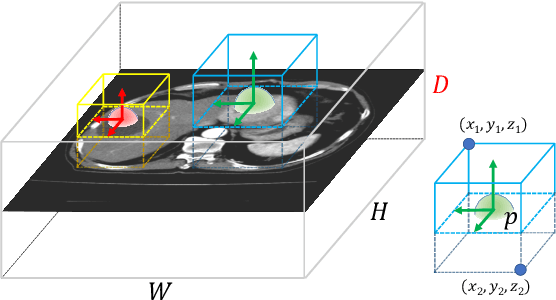
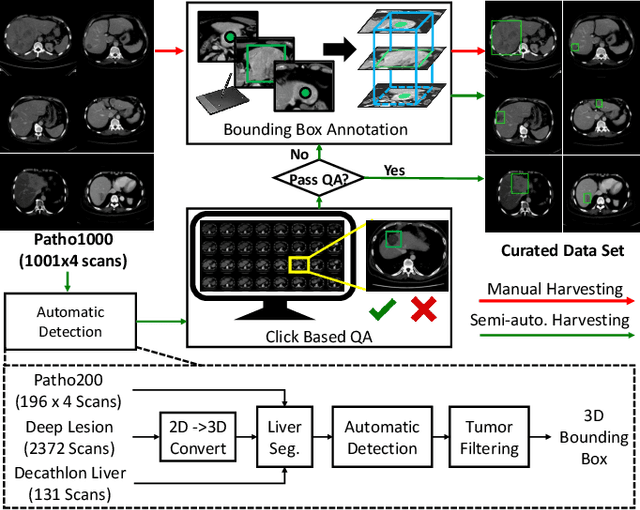
Effective and non-invasive radiological imaging based tumor/lesion characterization (e.g., subtype classification) has long been a major aim in the oncology diagnosis and treatment procedures, with the hope of reducing needs for invasive surgical biopsies. Prior work are generally very restricted to a limited patient sample size, especially using patient studies with confirmed pathological reports as ground truth. In this work, we curate a patient cohort of 1305 dynamic contrast CT studies (i.e., 5220 multi-phase 3D volumes) with pathology confirmed ground truth. A novel fully-automated and multi-stage liver tumor characterization framework is proposed, comprising four steps of tumor proposal detection, tumor harvesting, primary tumor site selection, and deep texture-based characterization. More specifically, (1) we propose a 3D non-isotropic anchor-free lesion detection method; (2) we present and validate the use of multi-phase deep texture learning for precise liver lesion tissue characterization, named spatially adaptive deep texture (SaDT); (3) we leverage small-sized public datasets to semi-automatically curate our large-scale clinical dataset of 1305 patients where four main liver tumor subtypes of primary, secondary, metastasized and benign are presented. Extensive evaluations demonstrate that our new data curation strategy, combined with the SaDT deep dynamic texture analysis, can effectively improve the mean F1 scores by >8.6% compared with baselines, in differentiating four major liver lesion types. This is a significant step towards the clinical goal.
Co-Heterogeneous and Adaptive Segmentation from Multi-Source and Multi-Phase CT Imaging Data: A Study on Pathological Liver and Lesion Segmentation
Jun 10, 2020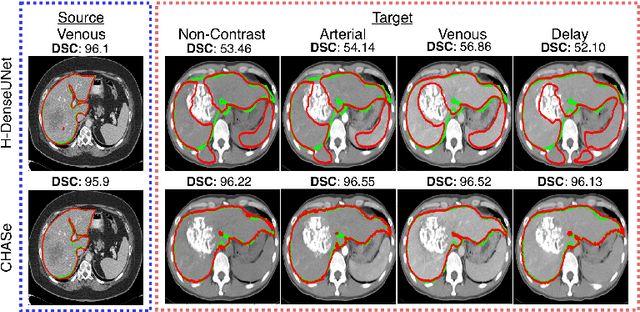
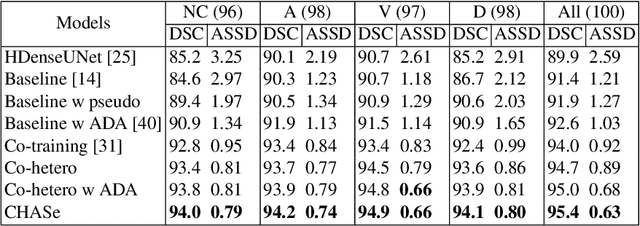
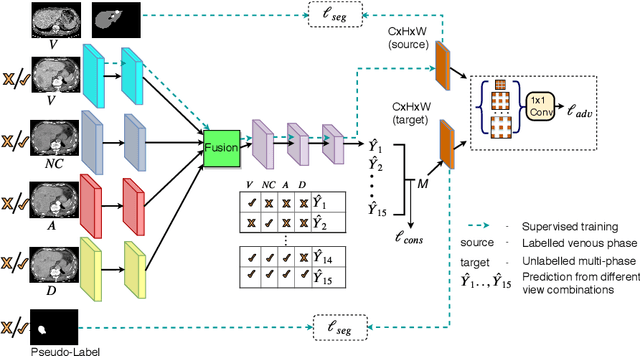
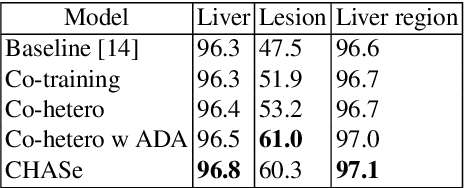
In medical imaging, organ/pathology segmentation models trained on current publicly available and fully-annotated datasets usually do not well-represent the heterogeneous modalities, phases, pathologies, and clinical scenarios encountered in real environments. On the other hand, there are tremendous amounts of unlabelled patient imaging scans stored by many modern clinical centers. In this work, we present a novel segmentation strategy, co-heterogenous and adaptive segmentation (CHASe), which only requires a small labeled cohort of single phase imaging data to adapt to any unlabeled cohort of heterogenous multi-phase data with possibly new clinical scenarios and pathologies. To do this, we propose a versatile framework that fuses appearance based semi-supervision, mask based adversarial domain adaptation, and pseudo-labeling. We also introduce co-heterogeneous training, which is a novel integration of co-training and hetero modality learning. We have evaluated CHASe using a clinically comprehensive and challenging dataset of multi-phase computed tomography (CT) imaging studies (1147 patients and 4577 3D volumes). Compared to previous state-of-the-art baselines, CHASe can further improve pathological liver mask Dice-Sorensen coefficients by ranges of $4.2\% \sim 9.4\%$, depending on the phase combinations: e.g., from $84.6\%$ to $94.0\%$ on non-contrast CTs.
JSSR: A Joint Synthesis, Segmentation, and Registration System for 3D Multi-Modal Image Alignment of Large-scale Pathological CT Scans
May 27, 2020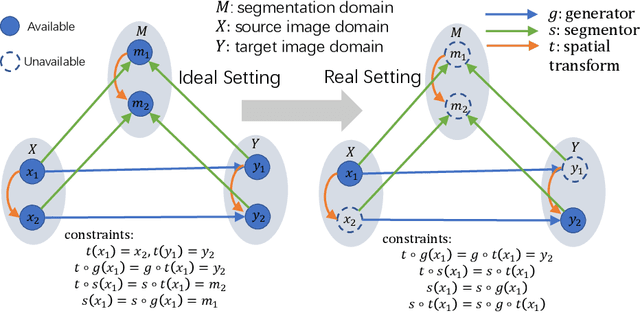
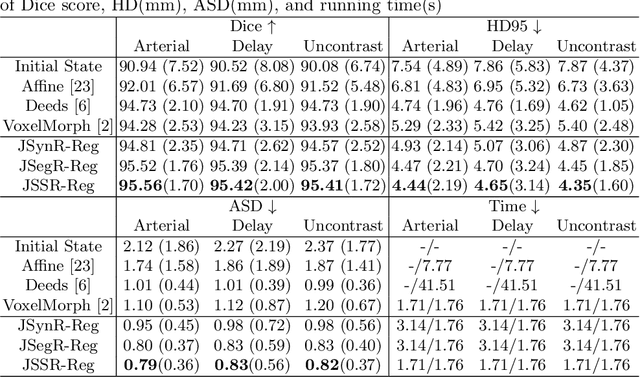
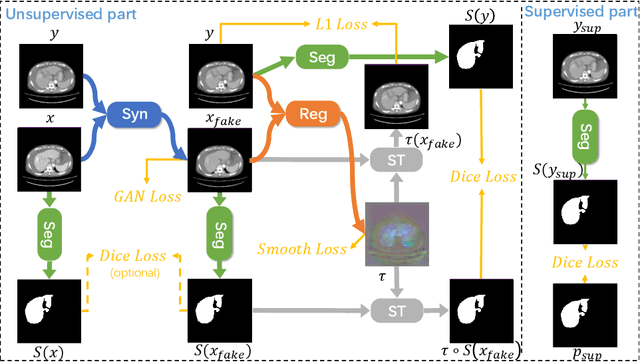
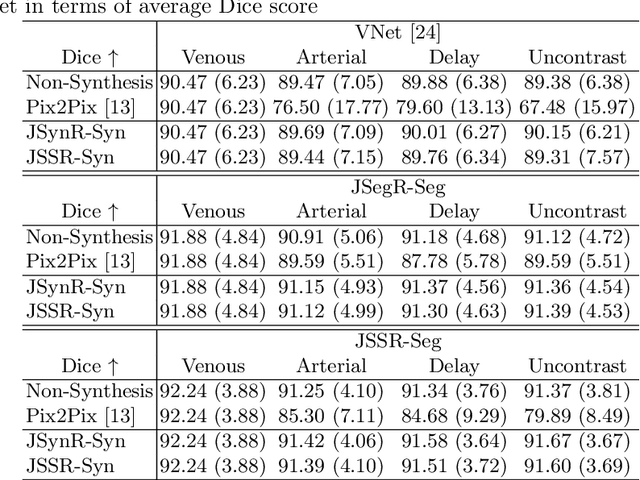
Multi-modal image registration is a challenging problem yet important clinical task in many real applications and scenarios. For medical imaging based diagnosis, deformable registration among different image modalities is often required in order to provide complementary visual information, as the first step. During the registration, the semantic information is the key to match homologous points and pixels. Nevertheless, many conventional registration methods are incapable to capture the high-level semantic anatomical dense correspondences. In this work, we propose a novel multi-task learning system, JSSR, based on an end-to-end 3D convolutional neural network that is composed of a generator, a register and a segmentor, for the tasks of synthesis, registration and segmentation, respectively. This system is optimized to satisfy the implicit constraints between different tasks unsupervisedly. It first synthesizes the source domain images into the target domain, then an intra-modal registration is applied on the synthesized images and target images. Then we can get the semantic segmentation by applying segmentors on the synthesized images and target images, which are aligned by the same deformation field generated by the registers. The supervision from another fully-annotated dataset is used to regularize the segmentors. We extensively evaluate our JSSR system on a large-scale medical image dataset containing 1,485 patient CT imaging studies of four different phases (i.e., 5,940 3D CT scans with pathological livers) on the registration, segmentation and synthesis tasks. The performance is improved after joint training on the registration and segmentation tasks by 0.9% and 1.9% respectively from a highly competitive and accurate baseline. The registration part also consistently outperforms the conventional state-of-the-art multi-modal registration methods.