 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeGaussian: High-Fidelity 4D Human Reconstruction in Monocular Videos via Vision Priors
Feb 05, 2026We introduce ShapeGaussian, a high-fidelity, template-free method for 4D human reconstruction from casual monocular videos. Generic reconstruction methods lacking robust vision priors, such as 4DGS, struggle to capture high-deformation human motion without multi-view cues. While template-based approaches, primarily relying on SMPL, such as HUGS, can produce photorealistic results, they are highly susceptible to errors in human pose estimation, often leading to unrealistic artifacts. In contrast, ShapeGaussian effectively integrates template-free vision priors to achieve both high-fidelity and robust scene reconstructions. Our method follows a two-step pipeline: first, we learn a coarse, deformable geometry using pretrained models that estimate data-driven priors, providing a foundation for reconstruction. Then, we refine this geometry using a neural deformation model to capture fine-grained dynamic details. By leveraging 2D vision priors, we mitigate artifacts from erroneous pose estimation in template-based methods and employ multiple reference frames to resolve the invisibility issue of 2D keypoints in a template-free manner. Extensive experiments demonstrate that ShapeGaussian surpasses template-based methods in reconstruction accuracy, achieving superior visual quality and robustness across diverse human motions in casual monocular videos.
ZALM3: Zero-Shot Enhancement of Vision-Language Alignment via In-Context Information in Multi-Turn Multimodal Medical Dialogue
Sep 26, 2024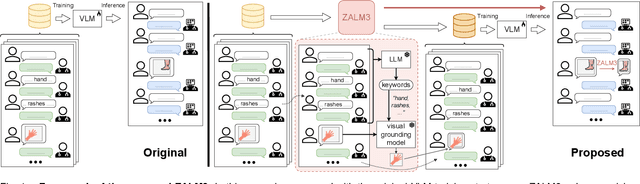
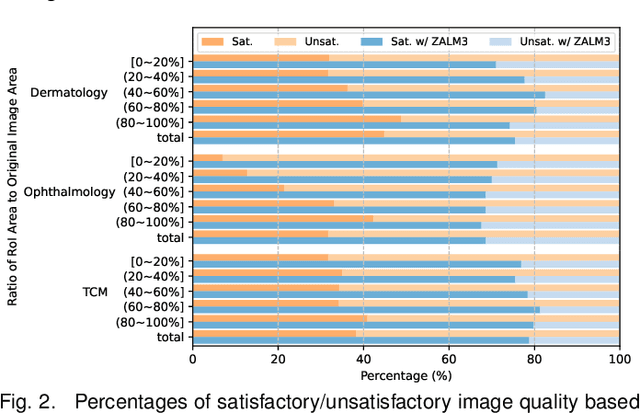
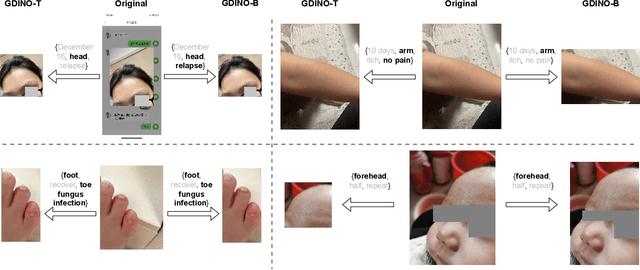
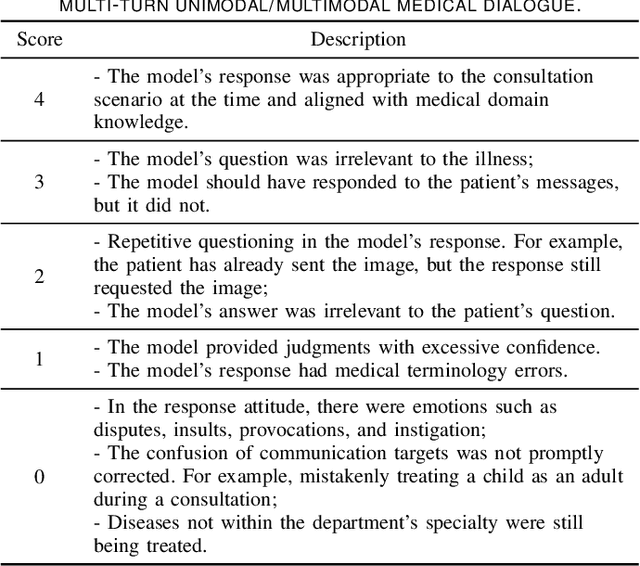
The rocketing prosperity of large language models (LLMs) in recent years has boosted the prevalence of vision-language models (VLMs) in the medical sector. In our online medical consultation scenario, a doctor responds to the texts and images provided by a patient in multiple rounds to diagnose her/his health condition, forming a multi-turn multimodal medical dialogue format. Unlike high-quality images captured by professional equipment in traditional medical visual question answering (Med-VQA), the images in our case are taken by patients' mobile phones. These images have poor quality control, with issues such as excessive background elements and the lesion area being significantly off-center, leading to degradation of vision-language alignment in the model training phase. In this paper, we propose ZALM3, a Zero-shot strategy to improve vision-language ALignment in Multi-turn Multimodal Medical dialogue. Since we observe that the preceding text conversations before an image can infer the regions of interest (RoIs) in the image, ZALM3 employs an LLM to summarize the keywords from the preceding context and a visual grounding model to extract the RoIs. The updated images eliminate unnecessary background noise and provide more effective vision-language alignment. To better evaluate our proposed method, we design a new subjective assessment metric for multi-turn unimodal/multimodal medical dialogue to provide a fine-grained performance comparison. Our experiments across three different clinical departments remarkably demonstrate the efficacy of ZALM3 with statistical significance.
Bidirectional Autoregressive Diffusion Model for Dance Generation
Feb 06, 2024Dance serves as a powerful medium for expressing human emotions, but the lifelike generation of dance is still a considerable challenge. Recently, diffusion models have showcased remarkable generative abilities across various domains. They hold promise for human motion generation due to their adaptable many-to-many nature. Nonetheless, current diffusion-based motion generation models often create entire motion sequences directly and unidirectionally, lacking focus on the motion with local and bidirectional enhancement. When choreographing high-quality dance movements, people need to take into account not only the musical context but also the nearby music-aligned dance motions. To authentically capture human behavior, we propose a Bidirectional Autoregressive Diffusion Model (BADM) for music-to-dance generation, where a bidirectional encoder is built to enforce that the generated dance is harmonious in both the forward and backward directions. To make the generated dance motion smoother, a local information decoder is built for local motion enhancement. The proposed framework is able to generate new motions based on the input conditions and nearby motions, which foresees individual motion slices iteratively and consolidates all predictions. To further refine the synchronicity between the generated dance and the beat, the beat information is incorporated as an input to generate better music-aligned dance movements. Experimental results demonstrate that the proposed model achieves state-of-the-art performance compared to existing unidirectional approaches on the prominent benchmark for music-to-dance generation.
HSTFormer: Hierarchical Spatial-Temporal Transformers for 3D Human Pose Estimation
Jan 18, 2023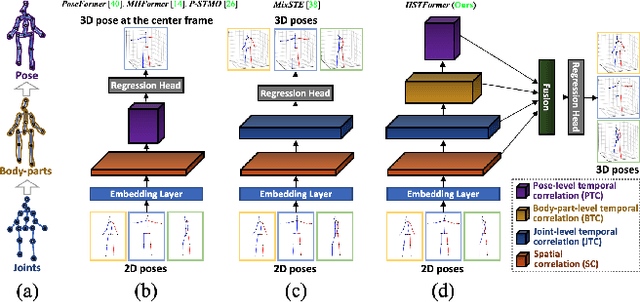
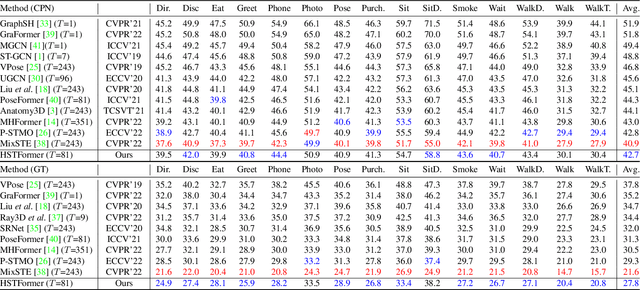
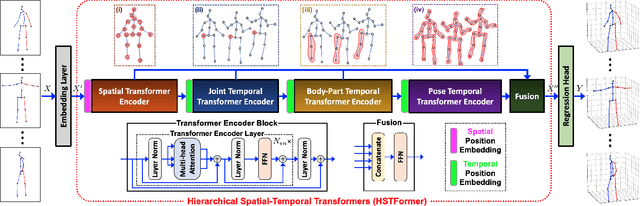
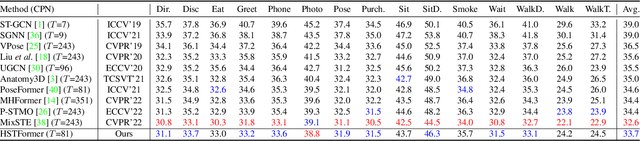
Transformer-based approaches have been successfully proposed for 3D human pose estimation (HPE) from 2D pose sequence and achieved state-of-the-art (SOTA) performance. However, current SOTAs have difficulties in modeling spatial-temporal correlations of joints at different levels simultaneously. This is due to the poses' spatial-temporal complexity. Poses move at various speeds temporarily with various joints and body-parts movement spatially. Hence, a cookie-cutter transformer is non-adaptable and can hardly meet the "in-the-wild" requirement. To mitigate this issue, we propose Hierarchical Spatial-Temporal transFormers (HSTFormer) to capture multi-level joints' spatial-temporal correlations from local to global gradually for accurate 3D HPE. HSTFormer consists of four transformer encoders (TEs) and a fusion module. To the best of our knowledge, HSTFormer is the first to study hierarchical TEs with multi-level fusion. Extensive experiments on three datasets (i.e., Human3.6M, MPI-INF-3DHP, and HumanEva) demonstrate that HSTFormer achieves competitive and consistent performance on benchmarks with various scales and difficulties. Specifically, it surpasses recent SOTAs on the challenging MPI-INF-3DHP dataset and small-scale HumanEva dataset, with a highly generalized systematic approach. The code is available at: https://github.com/qianxiaoye825/HSTFormer.
Prior-enhanced Temporal Action Localization using Subject-aware Spatial Attention
Nov 10, 2022Temporal action localization (TAL) aims to detect the boundary and identify the class of each action instance in a long untrimmed video. Current approaches treat video frames homogeneously, and tend to give background and key objects excessive attention. This limits their sensitivity to localize action boundaries. To this end, we propose a prior-enhanced temporal action localization method (PETAL), which only takes in RGB input and incorporates action subjects as priors. This proposal leverages action subjects' information with a plug-and-play subject-aware spatial attention module (SA-SAM) to generate an aggregated and subject-prioritized representation. Experimental results on THUMOS-14 and ActivityNet-1.3 datasets demonstrate that the proposed PETAL achieves competitive performance using only RGB features, e.g., boosting mAP by 2.41% or 0.25% over the state-of-the-art approach that uses RGB features or with additional optical flow features on the THUMOS-14 dataset.
Accurate and Robust Lesion RECIST Diameter Prediction and Segmentation with Transformers
Aug 28, 2022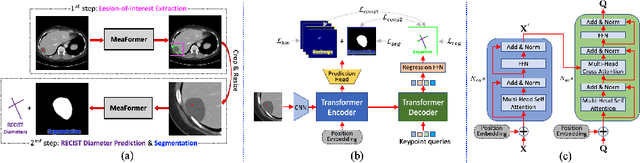
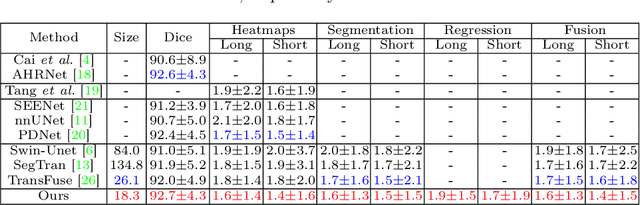
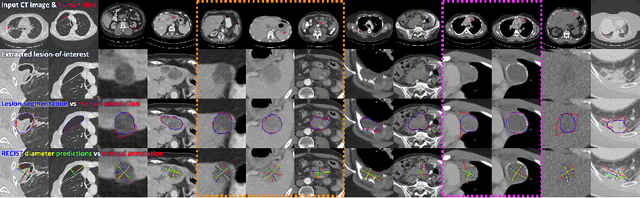

Automatically measuring lesion/tumor size with RECIST (Response Evaluation Criteria In Solid Tumors) diameters and segmentation is important for computer-aided diagnosis. Although it has been studied in recent years, there is still space to improve its accuracy and robustness, such as (1) enhancing features by incorporating rich contextual information while keeping a high spatial resolution and (2) involving new tasks and losses for joint optimization. To reach this goal, this paper proposes a transformer-based network (MeaFormer, Measurement transFormer) for lesion RECIST diameter prediction and segmentation (LRDPS). It is formulated as three correlative and complementary tasks: lesion segmentation, heatmap prediction, and keypoint regression. To the best of our knowledge, it is the first time to use keypoint regression for RECIST diameter prediction. MeaFormer can enhance high-resolution features by employing transformers to capture their long-range dependencies. Two consistency losses are introduced to explicitly build relationships among these tasks for better optimization. Experiments show that MeaFormer achieves the state-of-the-art performance of LRDPS on the large-scale DeepLesion dataset and produces promising results of two downstream clinic-relevant tasks, i.e., 3D lesion segmentation and RECIST assessment in longitudinal studies.
PieTrack: An MOT solution based on synthetic data training and self-supervised domain adaptation
Jul 22, 2022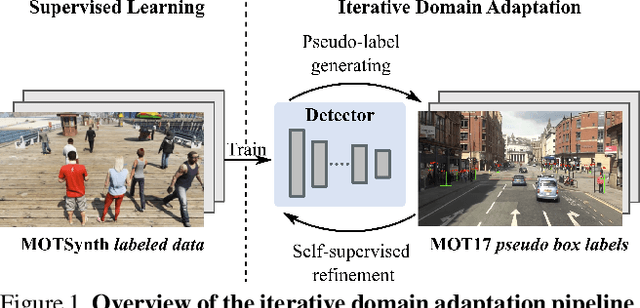
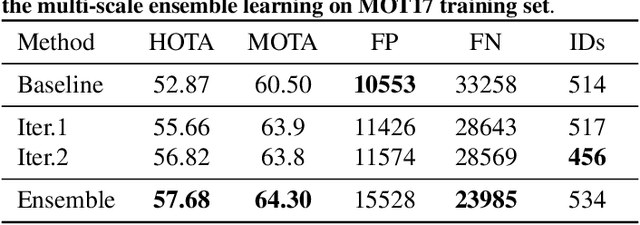
In order to cope with the increasing demand for labeling data and privacy issues with human detection, synthetic data has been used as a substitute and showing promising results in human detection and tracking tasks. We participate in the 7th Workshop on Benchmarking Multi-Target Tracking (BMTT), themed on "How Far Can Synthetic Data Take us"? Our solution, PieTrack, is developed based on synthetic data without using any pre-trained weights. We propose a self-supervised domain adaptation method that enables mitigating the domain shift issue between the synthetic (e.g., MOTSynth) and real data (e.g., MOT17) without involving extra human labels. By leveraging the proposed multi-scale ensemble inference, we achieved a final HOTA score of 58.7 on the MOT17 testing set, ranked third place in the challenge.
A Flexible Three-Dimensional Hetero-phase Computed Tomography Hepatocellular Carcinoma (HCC) Detection Algorithm for Generalizable and Practical HCC Screening
Aug 17, 2021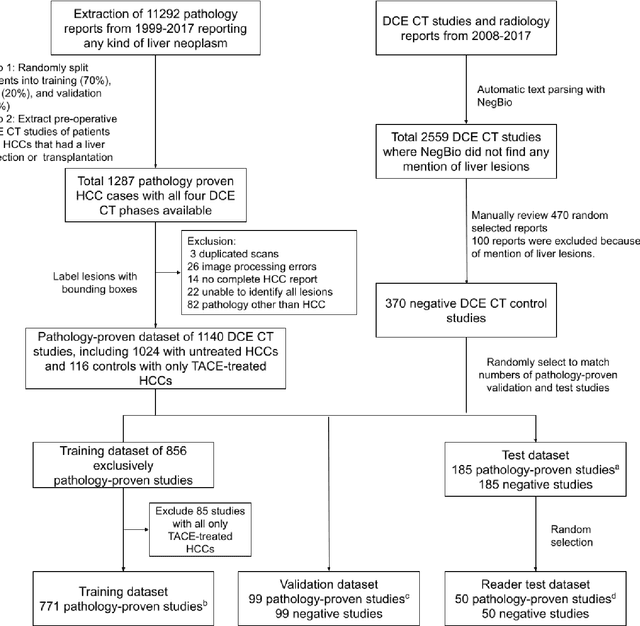
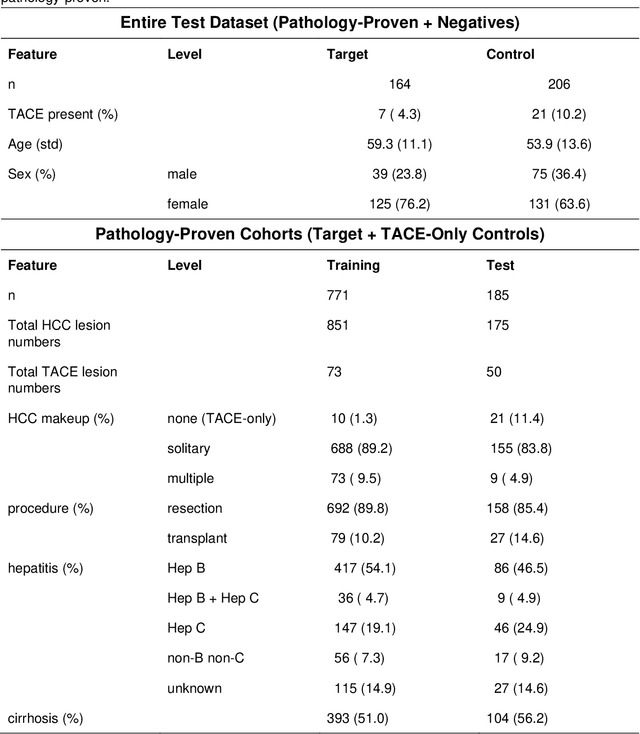
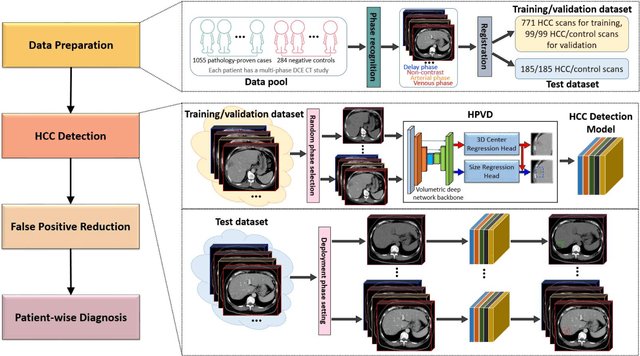
Hepatocellular carcinoma (HCC) can be potentially discovered from abdominal computed tomography (CT) studies under varied clinical scenarios, e.g., fully dynamic contrast enhanced (DCE) studies, non-contrast (NC) plus venous phase (VP) abdominal studies, or NC-only studies. We develop a flexible three-dimensional deep algorithm, called hetero-phase volumetric detection (HPVD), that can accept any combination of contrast-phase inputs and with adjustable sensitivity depending on the clinical purpose. We trained HPVD on 771 DCE CT scans to detect HCCs and tested on external 164 positives and 206 controls, respectively. We compare performance against six clinical readers, including two radiologists, two hepato-pancreatico-biliary (HPB) surgeons, and two hepatologists. The area under curve (AUC) of the localization receiver operating characteristic (LROC) for NC-only, NC plus VP, and full DCE CT yielded 0.71, 0.81, 0.89 respectively. At a high sensitivity operating point of 80% on DCE CT, HPVD achieved 97% specificity, which is comparable to measured physician performance. We also demonstrate performance improvements over more typical and less flexible non hetero-phase detectors. Thus, we demonstrate that a single deep learning algorithm can be effectively applied to diverse HCC detection clinical scenarios.
Lesion Segmentation and RECIST Diameter Prediction via Click-driven Attention and Dual-path Connection
May 05, 2021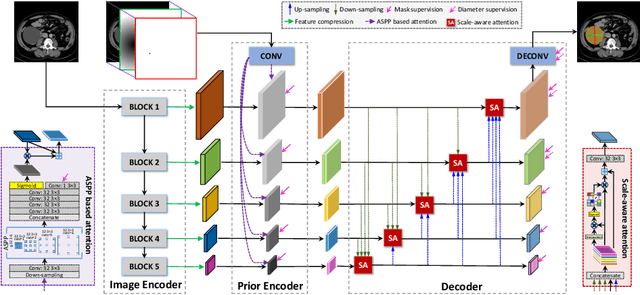
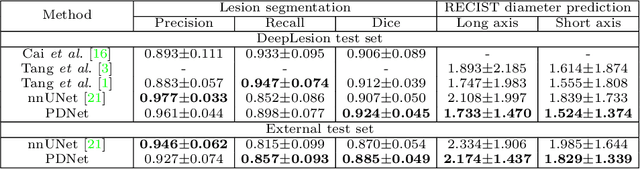
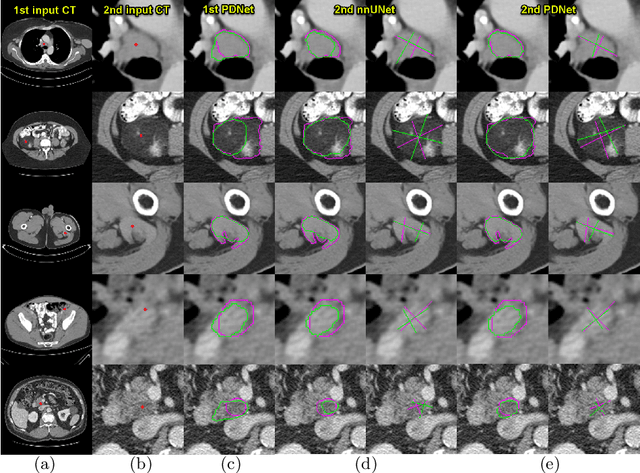
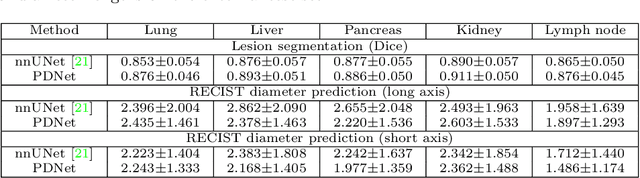
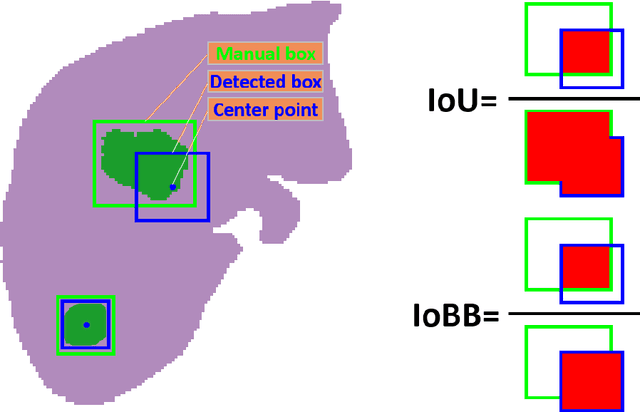
Measuring lesion size is an important step to assess tumor growth and monitor disease progression and therapy response in oncology image analysis. Although it is tedious and highly time-consuming, radiologists have to work on this task by using RECIST criteria (Response Evaluation Criteria In Solid Tumors) routinely and manually. Even though lesion segmentation may be the more accurate and clinically more valuable means, physicians can not manually segment lesions as now since much more heavy laboring will be required. In this paper, we present a prior-guided dual-path network (PDNet) to segment common types of lesions throughout the whole body and predict their RECIST diameters accurately and automatically. Similar to [1], a click guidance from radiologists is the only requirement. There are two key characteristics in PDNet: 1) Learning lesion-specific attention matrices in parallel from the click prior information by the proposed prior encoder, named click-driven attention; 2) Aggregating the extracted multi-scale features comprehensively by introducing top-down and bottom-up connections in the proposed decoder, named dual-path connection. Experiments show the superiority of our proposed PDNet in lesion segmentation and RECIST diameter prediction using the DeepLesion dataset and an external test set. PDNet learns comprehensive and representative deep image features for our tasks and produces more accurate results on both lesion segmentation and RECIST diameter prediction.
Weakly-Supervised Universal Lesion Segmentation with Regional Level Set Loss
May 03, 2021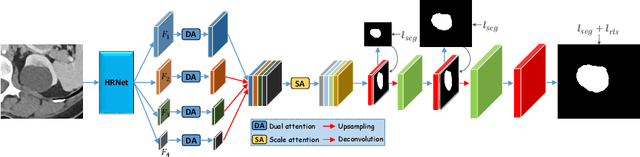
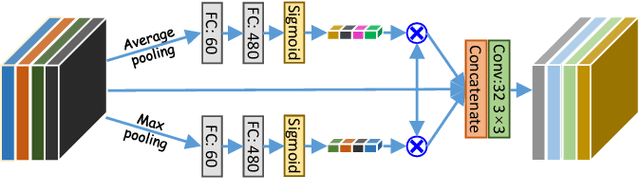
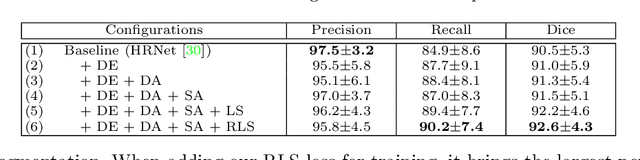
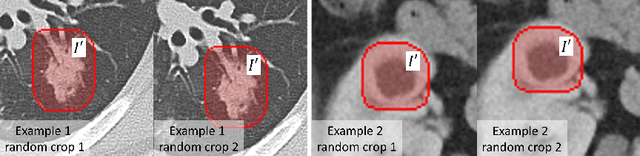
Accurately segmenting a variety of clinically significant lesions from whole body computed tomography (CT) scans is a critical task on precision oncology imaging, denoted as universal lesion segmentation (ULS). Manual annotation is the current clinical practice, being highly time-consuming and inconsistent on tumor's longitudinal assessment. Effectively training an automatic segmentation model is desirable but relies heavily on a large number of pixel-wise labelled data. Existing weakly-supervised segmentation approaches often struggle with regions nearby the lesion boundaries. In this paper, we present a novel weakly-supervised universal lesion segmentation method by building an attention enhanced model based on the High-Resolution Network (HRNet), named AHRNet, and propose a regional level set (RLS) loss for optimizing lesion boundary delineation. AHRNet provides advanced high-resolution deep image features by involving a decoder, dual-attention and scale attention mechanisms, which are crucial to performing accurate lesion segmentation. RLS can optimize the model reliably and effectively in a weakly-supervised fashion, forcing the segmentation close to lesion boundary. Extensive experimental results demonstrate that our method achieves the best performance on the publicly large-scale DeepLesion dataset and a hold-out test set.